日志集中
所谓日志集中就是将程序的所有日志和异常信息的记录汇总,在只有一台服务器的时候录本地文件问题不大,但是在负载均衡环境下再记录本地日志的话就出现问题了。为了可以直接进行查看、搜索,明确出问题的机器节点,把这些数据汇总在一起保存对于大型网站系统来说是很必要的。
写一个日志远远没有想的这么简单:
-
为了达到比较好的性能,日志是否先写本地内存队列然后定时刷到数据库中去?
-
各种日志混在一起也难以搜索,是否要添加一些搜索字段?比如分模块?
-
如果数据库不可用的话是不是先写本地日志以后再汇总过去?
-
日志是否易于辨明问题还是看日志怎么记录,如果日志中只写错误那么记录了也白记录,一定要写清楚这是哪个模块哪里出现了问题,有条件的话还可以写上一些参数信息和当前的状态。
-
对于未处理的异常信息不太可能手动去记录,一般而言很多框架或服务器都会提供一个接口点可以回调我们自己的代码,在这里我们就可以收集这些未处理异常然后统一记录,最后把用户带到友好的错误页面。不记录任何一个未处理异常都是可怕的事情,想象一下用户已经看到了色彩斑斓的页面,而开发还一无所知,这样的话这个问题始终会存在,即使用户投诉了反馈了我们也很难重现。
配置集中
配置集中和日志集中的目的是一样的,就是统一管理。任何一个系统其实或多或少都会有一些不能在程序中写死的参数(比如至少的数据库连接字符串和外部服务地址),一般情况下会写到配置文件中,这样存在几个问题:
一在多服务器的负载集群情况下要修改配置需要逐一修改每一台服务器的配置
二修改配置还需要重启服务或网站才会生效
三无法统一管理也无法知道是否所有网站都统一配置了相同参数。
解决的办法还是一样的就是汇总保存在统一的地方比如保存在数据库中,然后每一个网站都从数据库中获取配置的值,在实现的时候简单有简单的做法,复杂有复杂的做法,比如要考虑以下问题:
-
参数的值是直接保存强类型的那还是保存字符串在使用的时候转?甚至说值是支持对象和数组的,而不是简单类型。
-
参数的值不可能每一次获取都从数据库取,怎么做缓存,缓存多长时间,值修改了怎么同步回来?
-
程序是否允许修改值?还是说程序只是读取,不允许修改,修改参数的值只能通过数据库或后台进行。
-
是否是需要根据不同的部署环境、用户的语言、服务器的IP来设置不同的值。
不管怎么样,至少一个最简单的配置服务,从数据库中读取参数值,哪怕读取后永远缓存只有重启服务才能生效,也会比直接从本地配置文件中读要好很多。
缓存
缓存是一个非常常用的架构手段,对于一个网站系统来说有很多地方可以做缓存,真正能把缓存用好,在合理的地方用缓存,监控缓存的命中率,想办法提高缓存的命中率其实不是这么容易的,一般来说有这些地方可以做缓存,从上到下:
-
浏览器和CDN缓存:通过这两种整页的缓存可以尽量减少请求打到网站服务器的机会,也就提高了网站服务器的负载能力
-
反向代理的缓存:反向代理作为服务器的代理可以进行整页或是片段页面的缓存,可以提高直接把请求达到网站服务器的机会提高性能。
-
数据的缓存:我们可以尝试把部分数据保存在分布式缓存中。只要Key合理,并且请求有规律那么可以保证比较高的命中率,从而减轻数据库的压力,也减轻网站服务器的压力。
-
大块数据的内存中缓存:对于有一些大块的数据是无法保存在分布式缓存中的,那么可以直接在网站启动的时候把这种不太会改变的大块数据全部加到内存中来,这样这快数据的访问效率和计算效率就很高了。
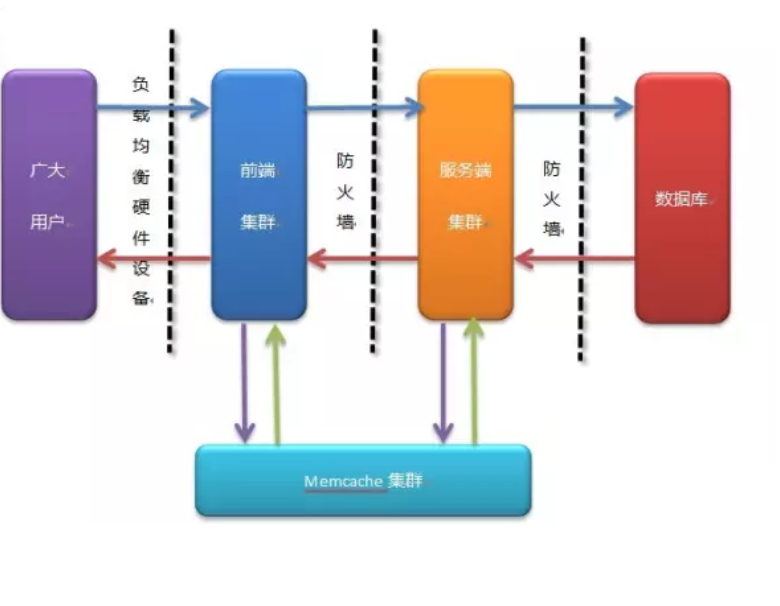
分布式缓存
所谓分布式缓存就是缓存的数据是分布在多个节点上的
优势:
一可以尽量利用服务器的资源。
二可以减少单点故障带来的影响。
在使用分布式缓存的时候要牢记下面几点:
-
缓存就是缓存,数据是允许排出和丢失的,当成文件系统用的话就错了。
-
分布式缓存的数据是通过网络存取的,数据传输走网络和本机内存中效率不能比,而且数据需要序列化和反序列化要考虑到性能开销。
-
缓存的Key生成的策略是很关键的,Key生成的参数过多的话很可能命中率会几乎为0,这种缓存做了也白做,因此需要针对分布式缓存的命中率有监控。
队列
通过把执行时间比较长的任务在队列中进行排队,通过限制队列的最大容纳项目数,实现一个抗高压的能力,并且队列后端的点也能有一个比较平稳的压力。
队列说到底也只是一个容器,如果前端的压力永远比后端处理能力大的话,队列也无法承受压力,因此队列也不是万能的。架构优化针对最薄弱的地方而不是最强的地方。
形式上来说队列有两种:
-
生产者和消费者:生产者生产出来的数据只能被一个消费者消费,也就是任务只能执行一次的。往往这种形式的数据是需要持久化的。
-
发布和订阅:任何一个事件都允许有多个发布者和多个订阅者,订阅者订阅自己感兴趣的东西,只要发布者发布了订阅者感兴趣的内容就会传播到所有的订阅者。一般来说这种形式的数据可以是允许丢失的不需要持久化的。
池技术
所谓的数据库连接池,线程池都是池技术的一个应用。池技术就是把创建开销比较大的对象缓存在池中避免重复创建和销毁。
比如说数据库连接池就是避免了频繁创建代价高的TCP连接,线程池就是避免了频繁创建代价高的线程。
池技术需要考虑的算法:
-
创建的富裕的对象的回收策略怎么做?
-
对象损坏怎么处理?