贝叶斯定理
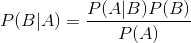
P(A|B)代表B发生的情况下,A发生的概率. P(B)代表B发生的概率. P(AB)代表AB同时发生的概率.P(B|A)代表A发生的情况下,B发生的概率。
显然有P(AB)=P(A|B)*P(B),P(AB)=P(B|A)*P(A)。从而P(B|A)=P(A|B)P(B)/P(A)。
朴素贝叶斯算法原理
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别.
我们已知样本X,$X_{train}=(x_1,x_2,....x_n)$,类别为y. 待预测样本为,$X_{test}=(x_{t1},x_{t2},....x_{tn})$,我们想要求解$P(y_{test}|X_{test})$.
可以算出$P(y_{test}|X_{test}) = frac {P(X_{test}|y_{test})P(y_{test})} {P(X_{test})} $
我们假设X的各个特征之间是相互独立的.
$P(y_{test})$很好求,比如一共有10条训练数据,其中y有三种取值y1,y2,y3,分别有数据量2,3,5条. 那P(y1)=0.2,P(y2)=0.3,P(y3)=0.5
$P(X_{test})$,因为我们假设各个特征之间是相互独立的,所以$P(X_{test})=P(x_{t1})P(x_{t2})....P(x_{tn})$。
$P(X_{test}|y_{test}) = P(x_{t1}|y_{test})P(x_{t2}|y_{test})...P(x_{tn}|y_{test}) $
现在问题很明朗了,就是要根据已知的训练样本$X_{train}$算出样本$X_{test}$中各个特征值的概率,以及不同的y下$X_{test}$中各个特征值的概率. 再比较哪一个y的取值下$P(X_{test}|y_{test})$取的最大值,我们就将$X_{test}$分类为哪一个y(y1/y2/y3)。
特征值是离散的情况下(即只有某几种特定取值),很好计算,就像上面计算P(y1/2/3)一样,统计一下满足条件的样本数量,除以总样本数量就行.比如特征$x_1$,假如有10个样本,其中3个样本的$x_1特征=1$,则$P(x_1=1)=0.3$。其中2个样本的类别为y1,1个样本的类别为y2,则$P(x_1=1|y=y1)=0.2$,$P(x_1=1|y=y2)=0.1$
特征值是连续的.那么$X_{test}=(x_{t1},x_{t2},....x_{tn})$中的$x_{t1},....x_{tn}$是我们没见过的特征. 我们需要根据已知样本假设出一种概率分布.从而我们可以得到新的样本的概率.
通常我们假设数据符合高斯分布: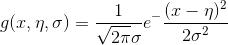
这样根据已知样本,可以求得均值,方差.来了个新样本后,就可以了计算新样本的概率.
写到这里,已经可以求出$P(y_{test}|X_{test})$了.我们看$P(y_1|X_{test}),P(y_2|X_{test}),....,P(y_n|X_{test})$哪个最大,则$X_{test}$属于哪个分类.
注意上面我们有2个假设
- 各个特征概率独立,即特征直接不相关
- 数据符合高斯分布
实际上我们对数据的概率分布可以有多种假设.在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯.
如果数据本身的分布不符合我们的假设,那用朴素贝叶斯可能没法取得好的效果.
sklearn中的使用
%%time
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
clf.fit(X_train,y_train)
predict_result = clf.predict(X_test)
result_df = pd.DataFrame(data={"id":test["id"], "sentiment":predict_result})
result_df.to_csv("naive_bayes.csv",index=False)