# Python 爬虫项目1
● Python 网页请求
requests
POST
GET
网页状态码
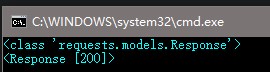
1 # -*- coding: UTF-8 -*- 2 from bs4 import BeautifulSoup 3 import requests 4 5 url = "http://www.baidu.com" 6 unknow = requests.get(url) 7 print(type(unknow)) 8 print(unknow)
通过标签匹配内容
1 # -*- coding: UTF-8 -*- 2 from bs4 import BeautifulSoup 3 import requests 4 5 url = "http://zz.ganji.com/fang1/" 6 r = requests.get(url) 7 soup = BeautifulSoup(r.text,'lxml') 8 for item in soup.find_all('dd'): 9 if item['class'] == ['dd-item','title']: 10 #print(item) 11 print(item.a.string) 12 print("----------------------------------------------------")

通过浏览器复制 copy selector

1 # -*- coding: UTF-8 -*- 2 from bs4 import BeautifulSoup 3 import requests 4 5 url = "http://zz.ganji.com/fang1/" 6 r = requests.get(url) 7 soup = BeautifulSoup(r.text,'lxml') 8 9 #价格获取 10 title = soup.select('dl > dd.dd-item.info > div.price > span.num') 11 print(title) 12 13 title2 = soup.select('dl > dd.dd-item.size > span.first.js-huxing') 14 print(title2)
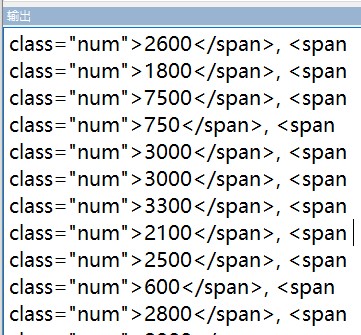
1 title = soup.select('dl > dd.dd-item.info > div.price > span.num') 2 print(title) 3 print(type(title[0]))
title 的类型还是 标签 Tag

soup.body.div.div.a 方式获取
1 # -*- coding: UTF-8 -*- 2 from bs4 import BeautifulSoup 3 import requests 4 5 url = "http://zz.ganji.com/fang1/" 6 r = requests.get(url) 7 soup = BeautifulSoup(r.text,'lxml') 8 print(soup.body.div.div.a)

1 from bs4 import BeautifulSoup 2 import requests 3 4 def isdiv(tag): 5 return tag.name == 'div' 6 7 url = "http://zz.ganji.com/fang1/" 8 r = requests.get(url) 9 soup = BeautifulSoup(r.text,'lxml') 10 11 value = soup.find_all(isdiv) 12 print(value)
python 使用代理发送网页请求
1 import requests 2 proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080", } 3 requests.get("http://example.org", proxies=proxies)