#Windows数据类型

Windows 下定义来百来个数据类型
这些数据类型全部是微软定义出来的(也就是说我们只有使用微软的SDK开发的时候,我们才能够使用这些数据类型)
它并非是 C语言 或者 C++ 所支持的数据类型
如果在Windows下面编程使用的是标准的C++ 或者C 编译器的话,这些数据类型是全部不可用的
Bit 位
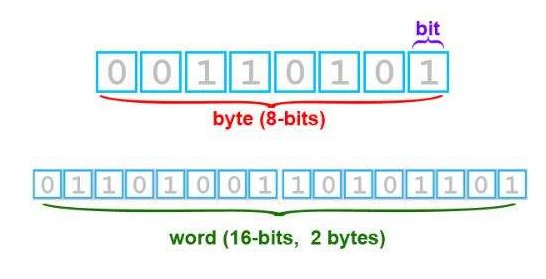
Bit是二进制数系统中,位简记为b,也称为比特,每个二进制数字0或1就是一个位(bit)。位是数据存储的最小单位 详情(图1)
一个位的字长是1
Byte 字节
8 bit 就称为一个字节(Byte)
1字节=8位(1 byte = 8bit)
一个字节的字长是8 详情(图1)
Word 字
1字=2字节(1 word = 2 byte)
一个字的字长为16 详情(图1)
dword
DWORD 就是 Double Word
每个word为2个字节的长度
DWORD 双字即为4个字节
每个字节是8位,共32位
(图1)
__int8
8位(8bit)的 int 整型
范围 -128 到 127
__int16
16位(16bit) int整型
范围 -32768 到 32767
__int32
32位(32bit) int整型
范围 -2147483648 到 2147483647
__int64
64位(64bit) int整型
范围 -9223372036854775808 到 9223372036854775807
BOOL
int 类型 占32位(bit) 代表 TRUE 1 FALSE 0
typedef int BOOL, *PBOOL, *LPBOOL;
BOOLEAN
byte字节型的布尔类型 占用 8位(bit) 代表 TRUE 1 FALSE 0
typedef BYTE BOOLEAN, *PBOOLEAN;
BSTR
typedef WCHAR* BSTR;
CHAR
typedef char CHAR, *PCHAR;
BYTE 代表8位 char 也是8位
typedef 语法
可以对同一个数据类型进行多次命名
*PBYTE *P代表 point 指针 unsigned char*
typedef unsigned char BYTE, *PBYTE, *LPBYTE;
typedef 语法
可以对同一个数据类型进行多次命名

DOUBLE
typedef double DOUBLE;
DWORD
使用的较多,主要用于存放32位数据
typedef unsigned long DWORD, *PDWORD, *LPDWORD;
DWORD_PTR
编程开发很少用到 用户态
内核用的很多
32位系统下表示 32位
64位系统下表示 64位
typedef unsigned long DWORD, *PDWORD, *LPDWORD; //32位 typedef ULONG_PTR DWORD_PTR, *PDWORD_PTR; //32位地址值 //用来装地址值的类型 typedef _W64 unsigned long ULONG_PTR, *PULONG_PTR; //32位系统下,内存地址值的长度 32位 -> DWORD_PTR(存储地址值) //64位系统时,内存长度变成了 64位 -> DWORD_PTR 64
DWORD32
慢慢的64位系统出来以后,变成了另外的一种数据类型 int
原因是原来设计这个类型的人已经走了
新来的人搞不清楚DWORD是什么类型 就把它理解成了int
之后的DWORD可以理解位int
T_T头好晕 这都是什么鬼
typedef unsigned int DWORD32;
DWORD64
慢慢的64位系统出来以后,变成了另外的一种数据类型 int
原因是原来设计这个类型的人已经走了
新来的人搞不清楚DWORD是什么类型 就把它理解成了int
之后的DWORD可以理解位int
T_T头好晕 这都是什么鬼
typedef unsigned __int64 DWORD64, *PDWORD64;
//微软中间经过了很多个版本 //后面的版本很多是找的印度的外包公司来做的 //印度的外包公司对Windows的了解是很有限的. //所以所他会认为 DWORD 它锁表示的是一个数值 //所以就会出现了 DWORD32 DWORD64
error_status_t
错误编号或者错误状态
微软中间经过了30年,经过很多的之手
设置任何一个API函数都要有一套错误的处理机制
typedef unsigned long error_status_t;
FLOAT
typedef float FLOAT;
HANDLE
把手
typedef void* HANDLE;
HCALL
typedef DWORD HCALL;
HRESULT
也会用来表示返回值
typedef LONG HRESULT;
INT
微软经历了各种各样的时代,命名也不统一了。
typedef int INT, *LPINT;
INT8
typedef signed char INT8;
INT16
typedef signed short INT16;
INT32
typedef signed int INT32;
INT64
typedef signed __int64 INT64;
STR部分
微软字符处理的版本也经过几个版本
字符处理是字符编码的处理
归根结底都是在 char wchar_t上面
字符在WIndows 里面有N种叫法
typedef char CHAR //8bit 长度 typedef wchar_t WCHAR //16bit 长度 typedef WCHAR *PWCHAR, *LPWCH, *PWCH; //都是 WCHAR 指针 point typedef CONST WCHAR *LPCWCH, *PCWCH; //代表 const WCHAR 指针 //long point (指针) w(宽) STR(字符串)c const(常量)
TCHAR 根据编译器 如果定义了 UNINCODE 就使用宽字符集 如果没有定义就使用ASCII字符集
VS2015直接在图中
如果使用的是命令行模式 可以直接在源文件的第一行 写入
1 #define UNICODE 2 //必须写在包含头文件之前,才会生效也就是程序的第一行 3 //具体原因 展开windows.h里面会有各种各样的宏定义判断是否定义UNICODE 4 //来进行学则使用 ASCII版本的函数 还是 W版本的函数

LPCWSTR
typedef const wchar_t* LPCWSTR;
LPWSTR
typedef wchar_t* LPWSTR, *PWSTR;
QWORD
typedef unsigned __int64 QWORD;
#Windows字符编码
//1Byte = 8Bit
//char == BYTE
//char 窄字节 8bit
//wchar_t 宽字节 16BIT
//字符集
//A 225个字符 ASCII字符集
//UTF-8 字符集最小单位是8位
//UTF-16 16位
//UTF-32 32位
// 32位包含了全世界所有的字符集
// UTF是一个大的标准,标准指定了所有字符(包括外星字符)的数量 ^_^
// 0-255 -> 和 ASCII重叠
// 256-326349
//所有的字符都占用32位的话是不是很兰妃
// 8bIT => 32Bit
// 可变长