作者:忆臻 (哈工大SCIR实验室在读博士生)
魏福煊 哈工大英才实验班本科生
谢天宝 哈工大英才实验班本科生
一、前言
在我们要用pytorch构建自己的深度学习模型的时候,基本上都是下面这个流程步骤,写在这里让一些新手童鞋学习的时候有一个大局感觉,无论是从自己写,还是阅读他人代码,按照这个步骤思想(默念4大步骤,找数据定义、找model定义、(找损失函数、优化器定义),主循环代码逻辑),直接去找对应的代码块,会简单很多。
二、基本步骤思想
所有的深度学习模型过程都可以形式化如下图:
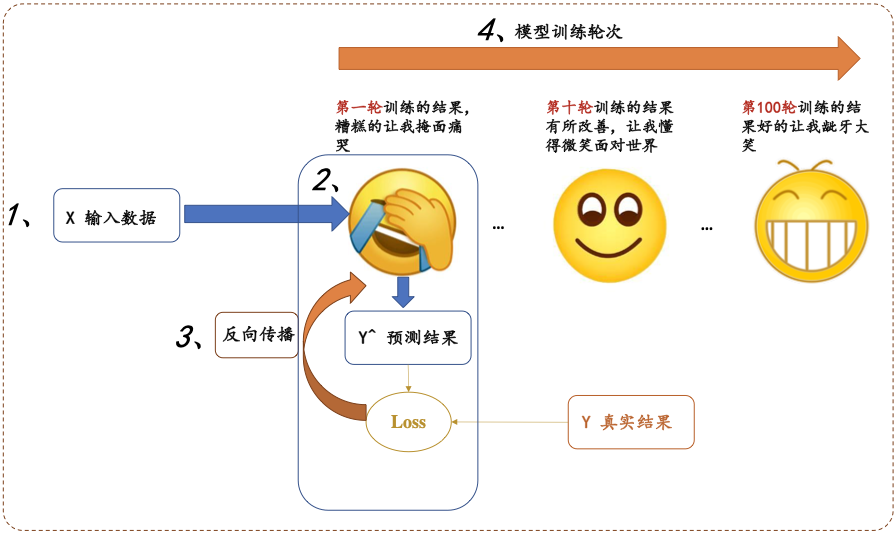
分为四大步骤:
1、输入处理模块 (X 输入数据,变成网络能够处理的Tensor类型)
2、模型构建模块 (主要负责从输入的数据,得到预测的y^, 这就是我们经常说的前向过程)
3、定义代价函数和优化器模块 (注意,前向过程只会得到模型预测的结果,并不会自动求导和更新,是由这个模块进行处理)
4、构建训练过程 (迭代训练过程,就是上图表情包的训练迭代过程)
这几个模块分别与上图的数字标号1,2,3,4进行一一对应!
三、实例讲解
知道了上面的宏观思想之后,后面给出每个模块稍微具体一点的解释和具体一个例子,再帮助大家熟悉对应的代码!
1.数据处理
对于数据处理,最为简单的⽅式就是将数据组织成为⼀个 。但许多训练需要⽤到mini-batch,直 接组织成Tensor不便于我们操作。pytorch为我们提供了Dataset和Dataloader两个类来方便的构建。
torch.utils.data.Dataset
继承Dataset 类需要override 以下⽅法:

torch.utils.data.DataLoader
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False)DataLoader Batch。如果选择shuffle = True,每⼀个epoch 后,mini-Batch batch_size 常⻅的使⽤⽅法如下:

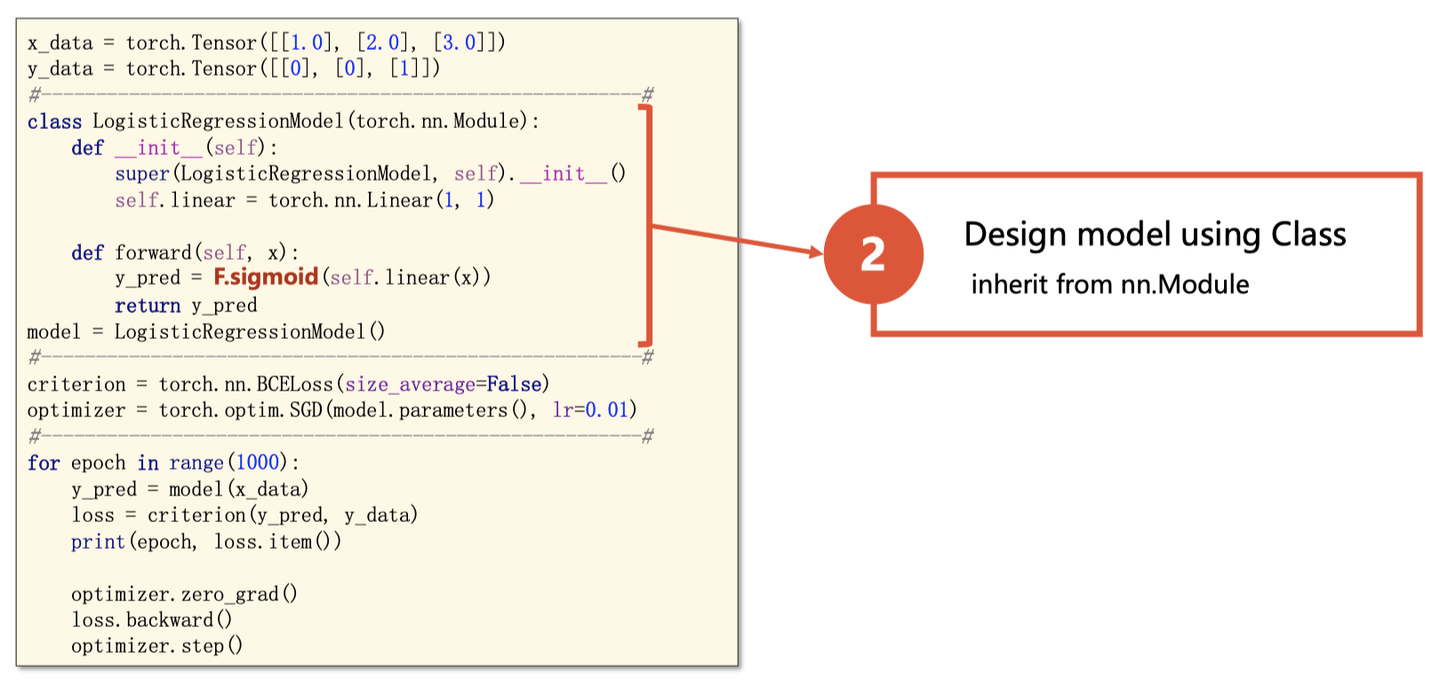
2. 模型构建
所有的模型都需要继承torch.nn.Module , 需要实现以下⽅法:

其中forward() ⽅法是前向传播的过程。在实现模型时,我们不需要考虑反向传播。
3. 定义代价函数和优化器

这部分根据⾃⼰的需求去参照doc
4、构建训练过程
pytorch的训练循环⼤致如下:

下面再用一个简单例子,来巩固一下:
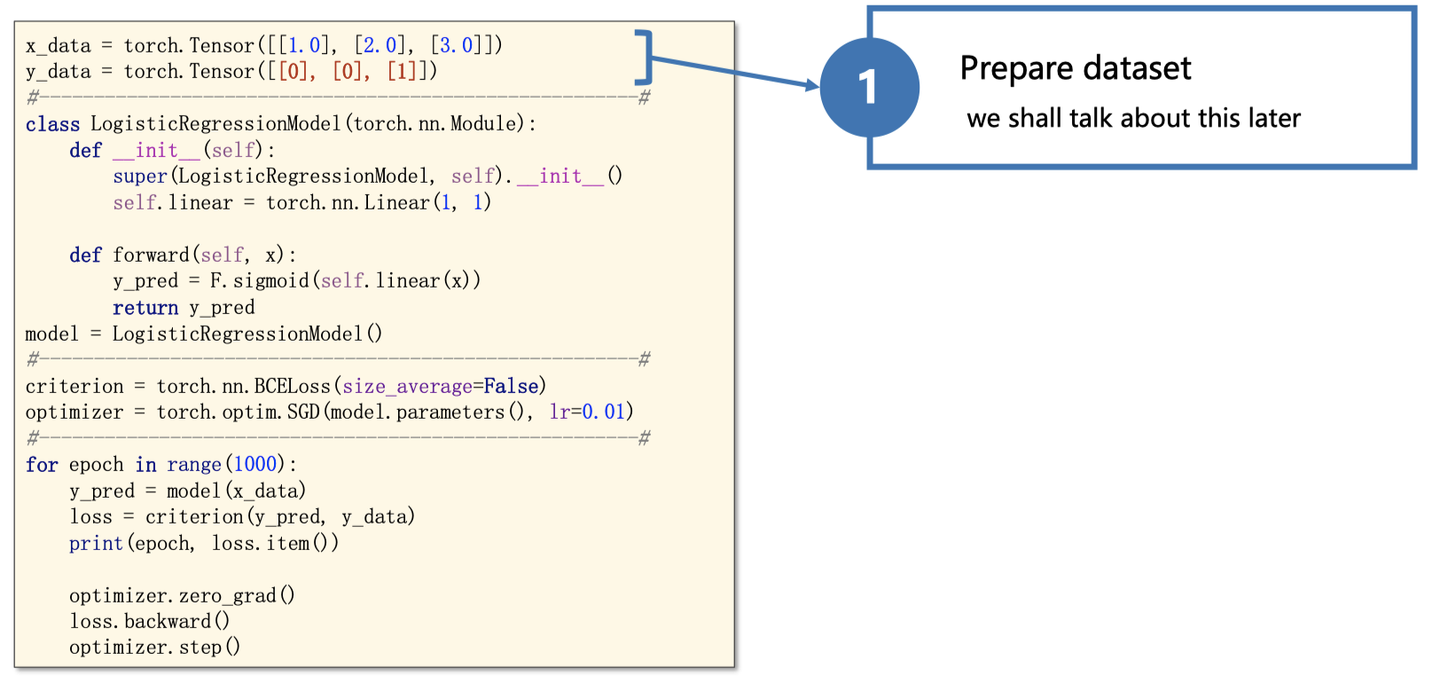
 slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699
slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699 slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699
slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699 slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699
slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699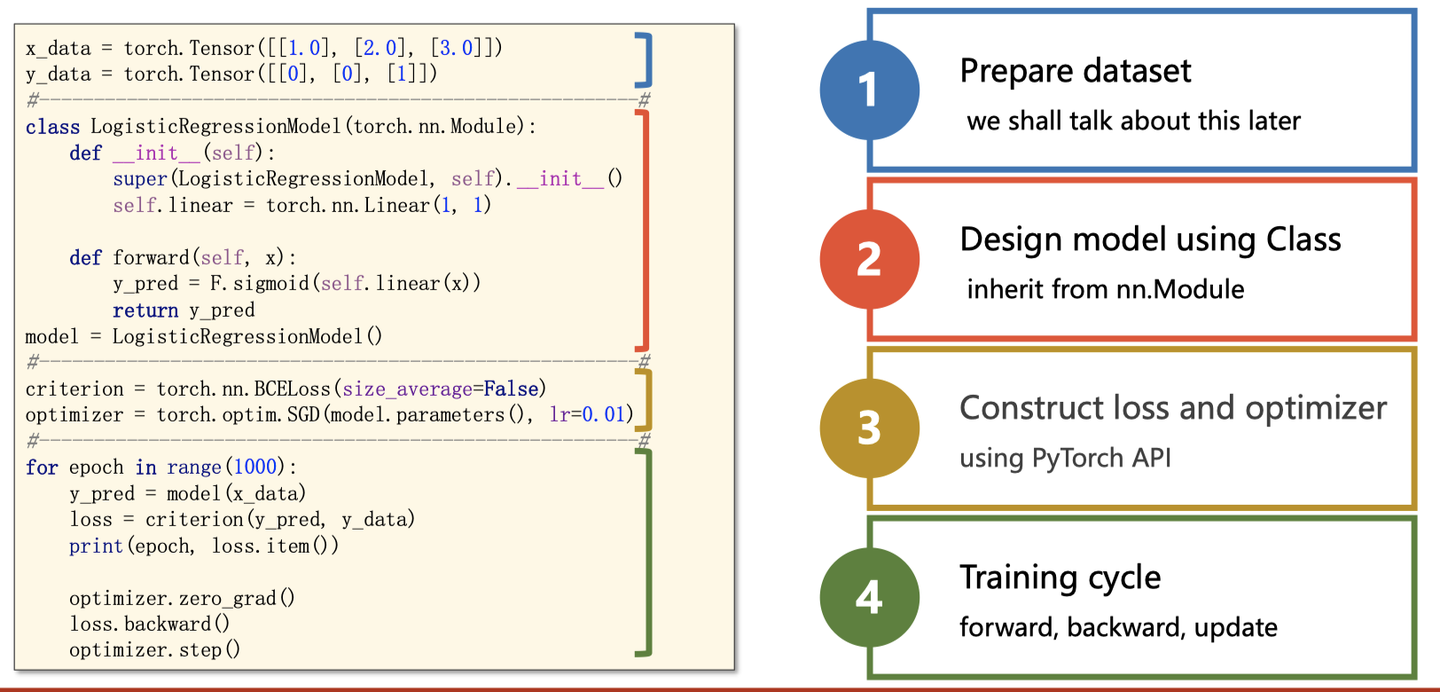 slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699
slides来自https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=3765076366663992699
四、资源推荐
希望上面的讲解能帮助新手童鞋建立一个基本的代码逻辑轮廓,这里推荐几个我觉得很好的资源:
1、第一个是B站刘二大人的入门Pytorch视频,这是我见过入门最好的视频资源之一,强烈推荐,上面的例子slides也均来自于此,地址如下
https://www.bilibili.com/video/BV1Y7411d7Ys?p=62、其实入门之后,就不用看太多学习资料了,你是搞哪个方向的,推荐直接去看一下相关方向顶会论文实现,从配环境、debug看懂他的code,到调参到他论文的相近结果,功力会针对性提高很多。
希望文章对一些新手朋友有帮助~
CNN训练的6大流程:
零、 函数总体说明
from torch.utils.data import Dataset 所有数据读取的基类,自定义数据读取会用到,返回一个列表。然后用torch.utils.data.DataLoader封装成Tensor。最后变variable。
from torchvision.dataset import ImageFolder :ImageFolder(root,transform,loader读片读取的方法)读取 root/dog/xxx.png,返回一个列表,列表中的每个值都是一个tuple,每个tuple包含的是图像路径和标签信息。所以需要转换为DataLoader将其转换tensor,在后期转成Variable数据类型作为网络输入。注意:list是不能作为模型输入的,因此在PyTorch中需要用另一个类来封装list,那是:torch.utils.data.DataLoader
from torch.utils.data import DataLoader DataLoader(dataset or ImageFolder,batchsize,shuffle)将Dataset可以batch、shuffle、多线程读取,torch.utils.data.DataLoader类可以将list类型的输入数据封装成Tensor数据格式,以备模型使用。,返回两个Tensor, data = inputs, labels
from torchvision import transfrom 预处理模块
一、数据导入
这里采用官方写好的torchvision.datasets.ImageFolder接口实现数据导入。这个接口需要你提供图像所在的文件夹,就是下面的data_dir=‘/data’这句,然后对于一个分类问题,这里data_dir目录下一般包括两个文件夹:train和val,每个文件件下面包含N个子文件夹,N是你的分类类别数,且每个子文件夹里存放的就是这个类别的图像。这样torchvision.datasets.ImageFolder就会返回一个列表(比如下面代码中的image_datasets[‘train’]或者image_datasets[‘val]),列表中的每个值都是一个tuple,每个tuple包含图像和标签信息。
data_dir = '/data'
自定义数据读取+多gpu运算
1. torch.utils.data.Dataset基类 or torchvision.datasets.ImageFolder 将路径和标签变列表
根据训练集和验证集预处理的不同和路径的不同,设置一个字典。
image_datasets = {x: ImageFolder(
os.path.join(data_dir, x),
data_transforms[x]),#data_transforms是一个字典
for x in ['train', 'val']}
变成一行,看for生成的字典:
image_datasets = {x: ImageFolder(os.path.join(data_dir, x),data_transforms[x]),for x in ['train', 'val']}
data_transforms = {
'train': transforms.Compose([ #torchvision.transforms.Compose叠加transforms操作
transforms.RandomSizedCrop(224),#输入对象都是PIL Image,也就是用python的PIL库读进来的图像内容
transforms.RandomHorizontalFlip(),#输入对象都是PIL Image,也就是用python的PIL库读进来的图像内容
transforms.ToTensor(),#生成Tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#输入对象 Tensor
]),
'val': transforms.Compose([
transforms.Scale(256),#transforms.Scale(256)其实就是resize操作,目前已经被transforms.Resize类取代了。
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
torch.utils.data.Dataset
class TensorDataset(Dataset): """Dataset wrapping data and target tensors.
Each sample will be retrieved by indexing both tensors along the first
dimension.
Arguments:
data_tensor (Tensor): contains sample data.
target_tensor (Tensor): contains sample targets (labels).
"""
def __init__(self, data_tensor, target_tensor):
assert data_tensor.size(0) == target_tensor.size(0)
self.data_tensor = data_tensor
self.target_tensor = target_tensor
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index]
def __len__(self): return self.data_tensor.size(0)
2. torch.utils.data.DataLoader对图像和标签列表分别封装成一个Tensor
前面torchvision.datasets.ImageFolder只是返回list,list是不能作为模型输入的,因此在PyTorch中需要用另一个类来封装list,那就是:torch.utils.data.DataLoader。torch.utils.data.DataLoader类可以将list类型的输入数据封装成Tensor数据格式,以备模型使用。注意,这里是对图像和标签分别封装成一个Tensor。这里要提到另一个很重要的类:torch.utils.data.Dataset,这是一个抽象类,在pytorch中所有和数据相关的类都要继承这个类来实现。比如前面说的torchvision.datasets.ImageFolder类是这样的,以及这里的torch.util.data.DataLoader类也是这样的。自定义一个类读取数据,自定义的这个类必须继承自torch.utils.data.Dataset这个基类,最后同样用torch.utils.data.DataLoader封装成Tensor。
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x], #加入ImageFolder输出的图片的名字
batch_size=4,
shuffle=True,
num_workers=4)#
for x in ['train', 'val']}
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
参数:
dataset (Dataset): 加载数据的数据集
batch_size (int, optional): 每批加载多少个样本
shuffle (bool, optional): 设置为“真”时,在每个epoch对数据打乱.(默认:False)
sampler (Sampler, optional): 定义从数据集中提取样本的策略,返回一个样本
batch_sampler (Sampler, optional): like sampler, but returns a batch of indices at a time 返回一批样本. 与atch_size, shuffle, sampler和 drop_last互斥.
num_workers (int, optional): 用于加载数据的子进程数。0表示数据将在主进程中加载。(默认:0)
collate_fn (callable, optional): 合并样本列表以形成一个 mini-batch. # callable可调用对象
pin_memory (bool, optional): 如果为 True, 数据加载器会将张量复制到 CUDA 固定内存中,然后再返回它们.
drop_last (bool, optional): 设定为 True 如果数据集大小不能被批量大小整除的时候, 将丢掉最后一个不完整的batch,(默认:False).
timeout (numeric, optional): 如果为正值,则为从工作人员收集批次的超时值。应始终是非负的。(默认:0)
worker_init_fn (callable, optional): If not None, this will be called on each worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as input, after seeding and before data loading. (default: None).
3. 将Tensor数据类型封装成Variable数据类型。
来看下面这段代码。dataloaders是一个字典,dataloders[‘train’]存的就是训练的数据,下面这个for循环就是从dataloders[‘train’]中读取batch_size个数据,batch_size在前面生成dataloaders的时候就设置了。因此这个data里面包含图像数据(inputs)这个Tensor和标签(labels)这个Tensor。然后用torch.autograd.Variable将Tensor封装成模型真正可以用的Variable数据类型。
for data in dataloders['train']:#dataloders迭代器
inputs, labels = data#每次取出batch_size个数据
if use_gpu:
inputs = Variable(inputs.cuda())#两个Variable
labels = Variable(labels.cuda())#
else:
inputs, labels = Variable(inputs), Variable(labels)
补充:Sample
class torch.utils.data.sampler.Sampler(data_source)
参数: data_source (Dataset) – dataset to sample from
作用: 创建一个采样器, class torch.utils.data.sampler.Sampler是所有的Sampler的基类, 其中,iter(self)函数来获取一个迭代器,对数据集中元素的索引进行迭代,len(self)方法返回迭代器中包含元素的长度.
class RandomSampler(Sampler): """Samples elements randomly, without replacement. Arguments: data_source (Dataset): dataset to sample from """ def __init__(self, data_source): self.data_source = data_source def __iter__(self): return iter(torch.randperm(len(self.data_source)).long()) def __len__(self): return len(self.data_source) class sampler(Sampler): def __init__(self, train_size, batch_size): """
返回一个所有的rand_num_view排序的迭代器,至于batchsize放到dataloader里面,这里面存着一个batch接着一个batch. (1)batchsize:每批数据量的大小。DL通常用SGD的优化算法进行训练,也就是一次(1 个iteration)一起训练batchsize个样本,计算它们的平均损失函数值,来更新参数。 (2)iteration:1个iteration即迭代一次,也就是用batchsize个样本训练一次。 """ self.num_data = train_size # 训练大小 self.num_per_batch = int(train_size / batch_size) #iteration 总数据/批处理大小 self.batch_size = batch_size self.range = torch.arange(0,batch_size).view(1, batch_size).long() self.leftover_flag = False if train_size % batch_size: self.leftover = torch.arange(self.num_per_batch*batch_size, train_size).long() self.leftover_flag = True def __iter__(self): #torch.randperm(n, out=None) → LongTensor 给定参数n,返回一个从0 到n -1 的随机整数排列。 rand_num = torch.randperm(self.num_per_batch).view(-1,1) * self.batch_size self.rand_num = rand_num.expand(self.num_per_batch, self.batch_size) + self.range self.rand_num_view = self.rand_num.view(-1) if self.leftover_flag: self.rand_num_view = torch.cat((self.rand_num_view, self.leftover),0) return iter(self.rand_num_view)#返回一个所有的rand_num_view排序的迭代器 def __len__(self): return self.num_data
二、导入你的模型
封装好了数据后,就可以作为模型的输入了。所以要先导入你的模型。在PyTorch中已经默认为大家准备了一些常用的网络结构,比如分类中的VGG,ResNet,DenseNet等等,可以用torchvision.models模块来导入。比如用torchvision.models.resnet18(pretrained=True)来导入ResNet18网络,同时指明导入的是已经预训练过的网络。因为预训练网络一般是在1000类的ImageNet数据集上进行的,所以要迁移到你自己数据集的2分类,需要替换最后的全连接层为你所需要的输出。因此下面这三行代码进行的就是用models模块导入resnet18网络,然后获取全连接层的输入channel个数,用这个channel个数和你要做的分类类别数(这里是2)替换原来模型中的全连接层。这样网络结果也准备好。
model = models.resnet18(pretrained=True) num_ftrs = model.fc.in_features#获取全连接层的输入channel个数 model.fc = nn.Linear(num_ftrs, 2)
三、定义损失函数criterion = nn.CrossEntropyLoss()
在PyTorch中采用torch.nn模块来定义网络的所有层,比如卷积、降采样、损失层等等,这里采用交叉熵函数,因此可以这样定义:
criterion = nn.CrossEntropyLoss()
四、定义优化函数optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
在PyTorch中是通过torch.optim模块来实现的。另外这里虽然写的是SGD,但是因为有momentum,所以是Adam的优化方式。这个类的输入包括需要优化的参数:model.parameters(),学习率,还有Adam相关的momentum参数。现在很多优化方式的默认定义形式就是这样的。
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
五、定义学习率的变化策略scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
这里采用的是torch.optim.lr_scheduler模块的StepLR类,表示每隔step_size个epoch就将学习率降为原来的gamma倍。
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
六、开始训练
1. 更新下学习率 scheduler.step()【制定了学习率的变化策略的原因】
这是因为我们前面制定了学习率的变化策略,所以在每个epoch开始时都要更新下:
scheduler.step()
2. 设置模型状态为训练状态 model.train(True)
model.train(True)
3. 所有梯度置0 model.zero_grad()
# Zero the gradients before running the backward pass.
model.zero_grad()
model.zero_grad()
4. 网络的前向传播model(inputs)
outputs = model(inputs)
5. 得到损失criterion(outputs, labels)
然后将输出的outputs和原来导入的labels作为loss函数的输入就可以得到损失了:
loss = criterion(outputs, labels)
6. torch.max预测该样本属于哪个类别的信息
输出的outputs也是torch.autograd.Variable格式,得到输出后(网络的全连接层的输出)还希望能到到模型预测该样本属于哪个类别的信息,这里采用torch.max。torch.max()的第一个输入是tensor格式,所以用outputs.data而不是outputs作为输入;第二个参数1是代表dim的意思,也就是取每一行的最大值,其实就是我们常见的取概率最大的那个index;第三个参数loss也是torch.autograd.Variable格式。
_, preds = torch.max(outputs.data, 1)
torch.max()返回的是两个Variable,第一个Variable存的是最大值,第二个存的是其对应的位置索引index。这里我们想要得到的是索引,所以后面用[1]。
7. 梯度置0
optimizer.zero_grad() # Before the backward pass, use the optimizer object to zero all of the # gradients for the variables it will update (which are the learnable weights # of the model)
根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 了。
8. loss.backward()回传损失,过程中会计算梯度
计算得到loss后就要回传损失。要注意的是这是在训练的时候才会有的操作,测试时候只有forward过程。
loss.backward()
9. 根据这些梯度更新参数 optimizer.step()
回传损失过程中会计算梯度,然后需要根据这些梯度更新参数,optimizer.step()就是用来更新参数的。optimizer.step()后,你就可以从optimizer.param_groups[0][‘params’]里面看到各个层的梯度和权值信息。
optimizer.step()
这样一个batch数据的训练就结束了!当你不断重复这样的训练过程,最终就可以达到你想要的结果了。
0. 判断你是否有gpu可以用use_gpu = torch.cuda.is_available()
另外如果你有gpu可用,那么包括你的数据和模型都可以在gpu上操作,这在PyTorch中也非常简单。判断你是否有gpu可以用可以通过下面这行代码,如果有,则use_gpu是true。
use_gpu = torch.cuda.is_available()
完整代码请移步:Github
整理自:https://blog.csdn.net/u014380165/article/details/78525273
————————————————
版权声明:本文为CSDN博主「Snoopy_Dream」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/e01528/article/details/83894811

