来源:EDX上的课程BigData Fundamentals中Waht is data mining一节的字幕
部分翻译参考网易有道词典的翻译结果
由于笔者水平有限,部分翻译可能不太准确,还望大家不吝指正。
FRANK NEUMANN: In this video, you will learn some of the basics when considering algorithms for big data.
在这个视频里,你可以学到有关大数据算法的一些基础知识。
One of the most frequently used approaches to finding out information from big data is through data mining.
But what is data mining?
但是什么是数据挖掘呢?
Most probably you have some ideas on what data mining is about.
很可能你有一些关于数据挖掘是什么的想法。
Think about it for a second.
想一下。
I want to make your notion of data mining precise by providing you the following definition.
我想通过提供下边的定义来让你对数据挖掘的概念更加精确。
"Data mining is the discovery of 'models' for data."
“数据挖掘是对数据中‘模型’的发现。”
A model can be various things, and I would like to show you some examples.
模型可以是各种各样的东西,在这里我将向你展示一些例子。
An important example is PageRank by Google, which is used for web search.
一个重要的例子是Google的用于网页搜索的PageRank。
It models the importance of web pages in the internet.
它模拟了互联网上网页的重要性。
Pages are connected through links in a web graph.
网页通过网络图中的链接被连接起来。
In this model, each page is assigned a value that summarises the importance of that page.
在这个模型里,每个页面被指定了一个概括了这个页面重要性的值。
I will get to this in greater detail later in the course.
我会在接下来的课程里更加详细地讨论这个问题。
But essentially, the number assigned to a specific web page is the probability that a random surfer on the web graph is at this page at any given point in time.
但从本质上讲,每个特定的网页被指定的数字正是网络图上一个随机的上网者在任何给定时间在这个页面的概率
A high value means that the web page is an important one.
高值意味着这个网页很重要。
In this example, you can see a graph with five nodes and a page rank assigned to every page.
在这个例子里,你可以看到一个有着五个节点的图和以及每个页面都被指定了一个页面级别。

It can be observed that the central node, which has many incoming links, gets a higher score than the nodes that have not that many pages pointing to them.
我们可以看到中间节点(有着许多传入链接),比那些没有很多页面指向它们的节点获得了更高的分数。
In this sense, a page rank of a page is high if it is regarded as important by other pages that link to it.
从这个意义上讲,如果一个网页被链接到它的其他页面认为很重要,则它的页面级别就会很高。
Having the importance of web pages modelled in this way - one score per page - allows algorithms to judge the importance of pages as part of an internet search engine.
以这样的方式来模拟网页的重要性—一个页面对应一个分数—允许算法去判断作为互联网搜索引擎的一部分的网页的重要性。
As another example of data model, I'd like to look at the performance of algorithms.
作为另一个有关数据模型的例子,我想看看一下算法的性能。
Let's say you have designed an algorithm and have run it on various benchmarks.
比如说你设计了一个算法,并在各种基准上运行了它。
To make things simple, assume that all benchmark instances have the same size - let's say graphs of 10,000 nodes.
简单来说,假定所有基准实例都同样大—比如说有着10000节点的图。
The runtime of your algorithm on one particular benchmark instance would be measured in milliseconds.
算法在一个特定基准实例上的运行时间将以毫秒位单位测量。
Running your algorithm on each benchmark instance gives you a set of numbers characterising the runtime behaviour.
在每个基准实例上运行算法可以得出一组描述运行时行为的数字。
If you have done many runs of your algorithm, you might want to have a more compact model of your runtime data.
如果你将算法运行了很多遍,你可能会想要一个更紧凑的用于运行时数据模型。
If you assume that the data comes from a Gaussian distribution, then the model can be given by the average of these numbers together with its standard deviation.
如果假设数据来自高斯分布,那么模型可以由这些数字的平均值及其标准差给出。
This chart shows different Gaussian in distributions - all have mean 100.
这张图显示了不同的高斯分布—它们的平均值都是100
Three distributions having standard deviation 5, 10, and 15 are shown.
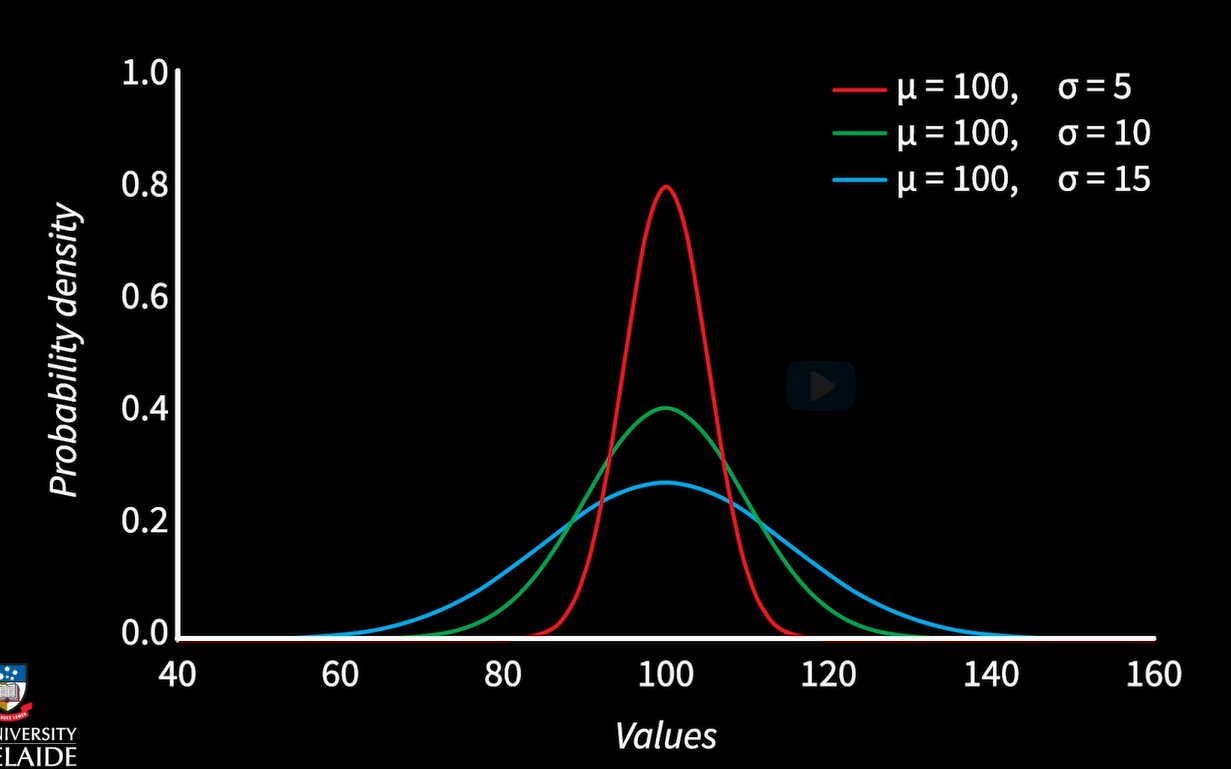
其中三个分布的标准差分别是5,10和15。
You can observe that the distributions have higher concentration around the mean if the standard deviation is small.
你可以看到如果分布的标准差更小,它在平均值附近就会更集中。
If your data consists of a lot of data points - let's say a billion - in a particular application, then describing your data by just two parameters, average and standard deviation, gives a very compact description.
如果在一个特定的应用中,你的数据中包含了大量的数据点(比如说一百万个),那么只需要平均值和标准差这两个参数来描述数据就可以得出一个非常紧凑的描述。
Having a compact description of your data is useful because you can easily implement algorithms that exploit the model.
有一个紧凑的数据描述是有用的,因为你可以轻松地实现利用这个模型的算法。
You will see this throughout the course.
你将在整个课程中看到这一点。
Next, you will be looking at how to make data mining models more precise and discuss different ways of modelling data in detail.