HTTP协议 学习:1-报文分析
背景
上一讲我们介绍了HTTP协议的一些 概念 ,对HTTP协议有了一个基础的认识。
正如之前学习MQTT协议一样,我们需要对HTTP的报文进行分析。
HTTP 报文
HTTP/1.1以及更早的HTTP协议报文都是语义可读的。在HTTP/2中,这些报文被嵌入到了一个新的二进制结构,帧。帧允许实现很多优化,比如报文头部的压缩和复用。即使只有原始HTTP报文的一部分以HTTP/2发送出来,每条报文的语义依旧不变,客户端会重组原始HTTP/1.1请求。因此用HTTP/1.1格式来理解HTTP/2报文仍旧有效。
有两种HTTP报文的类型,请求与响应,每种都有其特定的格式。
请求
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求报头(header)、空行和请求正文(数据)四个部分组成,下图给出了请求报文的一般格式。
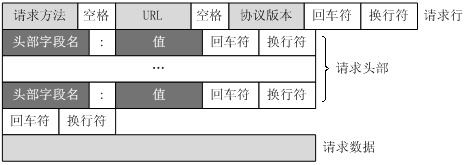
请求由以下元素组成:
- 一个HTTP的method,经常是由一个动词像
GET,POST或者一个名词像OPTIONS,HEAD来定义客户端的动作行为。通常客户端的操作都是获取资源(GET方法)或者发送HTML form表单值(POST方法),虽然在一些情况下也会有其他操作。 - 要获取的资源的路径,通常是上下文中就很明显的元素资源的URL,它没有protocol (
http://),domain(developer.mozilla.org),或是TCP的port(HTTP一般在80端口)。 - HTTP协议版本号。
- 为服务端表达其他信息的可选头部headers。
- 对于一些像POST这样的方法,报文的body就包含了发送的资源,这与响应报文的body类似。
请求行
HTTP请求第一行为请求行,由3个部分组成,
- 请求方法(method):说明了该请求时POST请求,
- 路径(url):用来说明请求是该域名根目录下的什么对象,
- 版本(version):HTTP协议版本号。
请求报头
HTTP请求第二行为请求头(也被称为消息头)。其中,HOST代表请求主机地址,User-Agent代表浏览器的标识,请求头由客户端自行设定。
POST /test.php HTTP/1.1 //请求行,方法是post,路径是"/test.php", 版本是HTTP/1.1
HOST:www.test.com //请求头
User-Agent:Mozilla/5.0 (windows NT 6.1;rv:15.0)Gecko/20100101 Firefox/15.0
//空白行,代表请求头结束
Username=admin&password=admin //请求正文
空白行
空行是作为请求行、消息报头 与 请求正文 之间的分隔符。也有一些博客将其归到请求报头的结尾中。
请求正文
HTTP请求第三行为请求正文,请求正文是可选的,它最常出现在POST请求方式中。
响应
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空白行和响应正文。
HTTP/1.1 200 OK // 状态行
Date: Sat, 31 Dec 2020 23:59:59 GMT // 消息报头
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
// 空白行
<html> // 以下都是响应正文
<head>
<title>Schips Homepage</title>
</head>
<body>
<!-- body goes here>
</body>
</html>
状态行
状态行由:“版本”+“状态号”+状态信息组成。
- 版本:HTTP协议版本号。
- 状态号(status code):一个状态码,来告知对应请求执行成功或失败,以及失败的原因。
- 状态信息:非权威的状态码描述信息,可以由服务端自行设定。
消息报头
与请求头部类似。
空白行
与请求中的空白和类似。
响应正文
比起请求报文,响应报文中更常见地包含获取的资源body。
HTTP 请求类型
HTTP 协议中共定义了八种方法(method)或者叫“动作”来表明对 Request-URI 指定的资源的不同操作方式,具体介绍如下:
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了五种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
虽然 HTTP 的请求方式有 8 种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
- OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送'*'的请求来测试服务器的功能性。
- HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET:向特定的资源发出请求。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。
五种状态码:
- 1xx:信息提示,表示请求已被成功接收,继续处理。
- 2xx:请求被成功提交。
- 3xx:客户端被重定向到其他资源。
- 4xx:客户端错误状态码,格式错误或者不存在资源。
- 5xx:描述服务器内部错误。
常见的状态码描述如下:
- 200:客户端请求成功,是最常见的状态。
- 302:重定向。
- 404:请求资源不存在,是最常见的状态。
- 400:客户端请求有语法错误,不能被服务器所理解。
- 401:请求未经授权。
- 403:服务器收到请求,但是拒绝提供服务。
- 500:服务器内部错误,是最常见的状态。
- 503:服务器当前不能处理客户端的请求。
HTTP content-type
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些 PHP 网页点击的结果却是下载一个文件或一张图片的原因。
Content-Type 标头告诉客户端实际返回的内容的内容类型。
语法格式:
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
HTTP 响应头信息
HTTP请求头提供了关于请求,响应或者其他的发送实体的信息。
在本章节中我们将具体来介绍HTTP响应头信息。
| 应答头 | 说明 |
|---|---|
| Allow | 服务器支持哪些请求方法(如GET、POST等)。 |
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
| Content-Length | 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。 |
| Content-Type | 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
| Date | 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
| Expires | 应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified | 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
| Location | 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。 注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。 注意Refresh的意义是"N秒之后刷新本页面或访问指定页面",而不是"每隔N秒刷新本页面或访问指定页面"。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV="Refresh" ...>。 注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。 |
| Server | 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
| Set-Cookie | 设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。 |
| WWW-Authenticate | 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。 注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。 |