什么是goroutine?
Goroutine是建立在线程之上的轻量级的抽象。它允许我们以非常低的代价在同一个地址空间中并行地执行多个函数或者方法。相比于线程,它的创建和销毁的代价要小很多,并且它的调度是独立于线程的。在golang中创建一个goroutine非常简单,使用“go”关键字即可:
package main
import (
"fmt"
"time"
)
func learning() {
fmt.Println("My first goroutine")
}
func main() {
go learning() /* we are using time sleep so that the main program does not terminate before the execution of goroutine.*/
time.Sleep(1 * time.Second)
fmt.Println("main function")
}
输出:
My first goroutine main function
若是将time.sleep拿掉
package main
import (
"fmt"
//"time"
)
func learning() {
fmt.Println("My first goroutine")
}
func main() {
go learning() /* we are using time sleep so that the main program does not terminate before the execution of goroutine.*/
//time.Sleep(1 * time.Second)
fmt.Println("main function")
}
只输出:
main function
这是因为,和线程一样,golang的主函数(其实也跑在一个goroutine中)并不会等待其它goroutine结束。如果主goroutine结束了,所有其它goroutine都将结束。
Goroutine与线程的区别
许多人认为goroutine比线程运行得更快,这是一个误解。Goroutine并不会更快,它只是增加了更多的并发性。当一个goroutine被阻塞(比如等待IO),golang的scheduler会调度其它可以执行的goroutine运行。与线程相比,它有以下几个优点:
- 内存消耗更少:
Goroutine所需要的内存通常只有2kb,而线程则需要1Mb(500倍)。
- 创建与销毁的开销更小
由于线程创建时需要向操作系统申请资源,并且在销毁时将资源归还,因此它的创建和销毁的开销比较大。相比之下,goroutine的创建和销毁是由go语言在运行时自己管理的,因此开销更低。
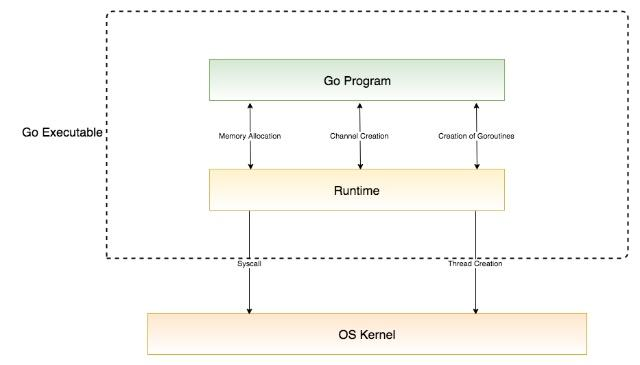
- 切换开销更小
这是goroutine于线程的主要区别,也是golang能够实现高并发的主要原因。线程的调度方式是抢占式的,如果一个线程的执行时间超过了分配给它的时间片,就会被其它可执行的线程抢占。在线程切换的过程中需要保存/恢复所有的寄存器信息,比如16个通用寄存器,PC(Program Counter),SP(Stack Pointer),段寄存器等等。
而goroutine的调度是协同式的,它不会直接地与操作系统内核打交道。当goroutine进行切换的时候,之后很少量的寄存器需要保存和恢复(PC和SP)。因此gouroutine的切换效率更高。
Goroutine的调度
真如前面提到的,goroutine的调度方式是协同式的。在协同式调度中,没有时间片的概念。为了并行执行goroutine,调度器会在以下几个时间点对其进行切换:
- Channel接受或者发送会造成阻塞的消息
- 当一个新的goroutine被创建时
- 可以造成阻塞的系统调用,如文件和网络操作垃圾回收
下面让我们来看一下调度器具体是如何工作的。Golang调度器中有三个概念
- Processor(P):逻辑处理器,代表着调度的上下文,它使goroutine在一个M上跑
- OSThread(M):操作系统线程,这是真正的内核OS线程
- Goroutines(G):拥有自己的栈,指令指针等信息,被P调度
在一个Go程序中,可用的线程数是通过GOMAXPROCS来设置的,默认值是可用的CPU核数。我们可以用runtime包动态改变这个值。OSThread调度在processor上,goroutines调度在OSThreads上,
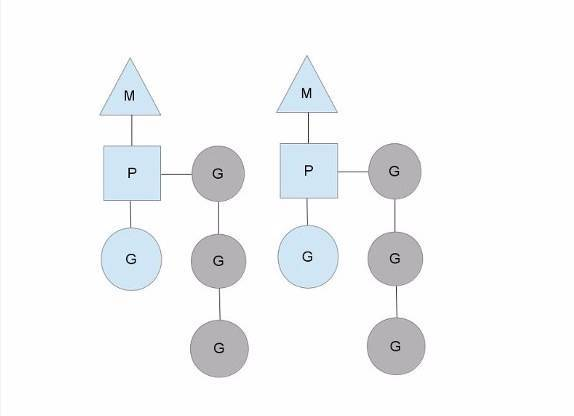
每个P会维护一个全局运行队列(称为runqueue),处于ready就绪状态的goroutine(灰色G)被放在这个队列中等待被调度。在编写程序时,每当go func启动一个goroutine时,runqueue便在尾部加入一个goroutine。在下一个调度点上,P就从runqueue中取出一个goroutine出来执行(蓝色G)。
当某个操作系统线程M阻塞的时候(比如goroutine执行了阻塞的系统调用),P可以绑定到另外一个操作系统线程M上,让运行队列中的其他goroutine继续执行:

上图中G0执行了阻塞操作,M0被阻塞,P将在新的系统线程M1上继续调度G执行。M1有可能是被新创建的,或者是从线程缓存中取出。Go调度器保证有足够的线程来运行所有的P,Go语言运行时默认限制每个程序最多创建10000个线程,这个现在可以通过调用runtime/debug包的SetMaxThreads方法来更改。
Go可以在在一个逻辑处理器P上实现并发,如果需要并行,必须使用多于1个的逻辑处理器。Go调度器会把goroutine平等分配到每个逻辑处理器上,此时goroutine将在不同的线程上运行,不过前提是要求机器拥有多个物理处理器。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
wg sync.WaitGroup
)
func main() {
//分配一个逻辑处理器P给调度器使用
runtime.GOMAXPROCS(1)
//在这里,wg用于等待程序完成,计数器加2,表示要等待两个goroutine
wg.Add(2)
//声明1个匿名函数,并创建一个goroutine
fmt.Printf("Begin Coroutinesn
")
go func() {
//在函数退出时,wg计数器减1
defer wg.Done()
//打印3次小写字母表
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c ", char)
}
fmt.Println("
")
}
}()
//声明1个匿名函数,并创建一个goroutine
go func() {
defer wg.Done()
//打印大写字母表3次
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c ", char)
}
fmt.Println("
")
}
}()
fmt.Printf("Waiting To Finish....
")
//等待2个goroutine执行完毕
wg.Wait()
}
这个程序使用runtime.GOMAXPROCS(1)来分配一个逻辑处理器给调度器使用,两个goroutine将被该逻辑处理器调度并发执行。程序输出:
Begin Coroutinesn Waiting To Finish.... A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m n o p q r s t u v w x y z
从输出来看,是先执行完一个goroutine,再接着执行第二个goroutine的,大写字母全部打印完后,再打印全部的小写字母。那么,有没有办法让两个goroutine并行执行呢?为程序指定两个逻辑处理器即可:
package main
import (
"fmt"
"runtime"
"sync"
)
var (
wg sync.WaitGroup
)
func main() {
//分配一个逻辑处理器P给调度器使用
runtime.GOMAXPROCS(2)
//在这里,wg用于等待程序完成,计数器加2,表示要等待两个goroutine
wg.Add(2)
//声明1个匿名函数,并创建一个goroutine
fmt.Printf("Begin Coroutinesn
")
go func() {
//在函数退出时,wg计数器减1
defer wg.Done()
//打印3次小写字母表
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c ", char)
}
fmt.Println("
")
}
}()
//声明1个匿名函数,并创建一个goroutine
go func() {
defer wg.Done()
//打印大写字母表3次
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c ", char)
}
fmt.Println("
")
}
}()
fmt.Printf("Waiting To Finish....
")
//等待2个goroutine执行完毕
wg.Wait()
}
结果输出
Begin Coroutinesn Waiting To Finish.... A B C D E F a b c d e G H I J K L M N O P Q R S T U V W X Y Z A B C D E F G H I J K L M N O P Q R S f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h T U V W X Y Z A B C D E F G H I J K L M N O P i j k l m n o p q r s t u v w x y z Q R S T U V W X Y Z
那如果只有1个逻辑处理器,如何让两个goroutine交替被调度?实际上,如果goroutine需要很长的时间才能运行完,调度器的内部算法会将当前运行的goroutine让出,防止某个goroutine长时间占用逻辑处理器。由于示例程序中两个goroutine的执行时间都很短,在为引起调度器调度之前已经执行完。不过,程序也可以使用runtime.Gosched()来将当前在逻辑处理器上运行的goruntine让出,让另一个goruntine得到执行:
package main
import (
"fmt"
"runtime"
"sync"
)
var (
wg sync.WaitGroup
)
func main() {
//分配一个逻辑处理器P给调度器使用
runtime.GOMAXPROCS(2)
//在这里,wg用于等待程序完成,计数器加2,表示要等待两个goroutine
wg.Add(2)
//声明1个匿名函数,并创建一个goroutine
fmt.Printf("Begin Coroutinesn
")
go func() {
//在函数退出时,wg计数器减1
defer wg.Done()
//打印3次小写字母表
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
if char == 'k' {
runtime.Gosched()
}
fmt.Printf("%c ", char)
}
fmt.Println("
")
}
}()
//声明1个匿名函数,并创建一个goroutine
go func() {
defer wg.Done()
//打印大写字母表3次
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
if char == 'K' {
runtime.Gosched()
}
fmt.Printf("%c ", char)
}
fmt.Println("
")
}
}()
fmt.Printf("Waiting To Finish....
")
//等待2个goroutine执行完毕
wg.Wait()
}
两个goroutine在循环的字符为k/K的时候会让出逻辑处理器,程序的输出结果为:
Begin Coroutinesn Waiting To Finish.... A B C D E F G H I J a K L b c d e f g h i j M N O P Q R S T U V W X Y Z k l A B C D E F G H I J m n o p q r s K L M N O P Q R S T U V W X Y Z A B C D E F G H I J t K L M N O P Q R S T U V W X Y Z u v w x y z a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m n o p q r s t u v w x y z
这里大小写字母果然是交替着输出了。
处理竞争状态
并发程序避免不了的一个问题是对资源的同步访问。如果多个goroutine在没有互相同步的情况下去访问同一个资源,并进行读写操作,这时goroutine就处于竞争状态下:
package main
import (
"fmt"
"runtime"
"sync"
)
var (
//counter为访问的资源
counter int64
wg sync.WaitGroup
)
func addCount() {
defer wg.Done()
for count := 0; count < 2; count++ {
value := counter
//当前goroutine从线程退出
runtime.Gosched()
value++
counter = value
}
}
func main() {
wg.Add(2)
go addCount()
go addCount()
wg.Wait()
fmt.Printf("counter: %d
", counter)
}
//output:counter: 4 或者counter: 2
这段程序中,goroutine对counter的读写操作没有进行同步,goroutine 1对counter的写结果可能被goroutine 2所覆盖。Go可通过如下方式来解决这个问题:
- 使用原子函数操作
- 使用互斥锁锁住临界区
- 使用通道chan
检测竞争状态
有时候竞争状态并不能一眼就看出来。Go 提供了一个非常有用的工具,用于检测竞争状态。使用方式是:
go build -race example4.go//用竞争检测器标志来编译程序./example4 //运行程序
原子操作实例:
package main
import (
"fmt"
"runtime"
"sync"
"sync/atomic"
)
var (
//counter为访问的资源
counter int64
wg sync.WaitGroup
)
func addCount() {
defer wg.Done()
for count := 0; count < 2; count++ {
//使用原子操作来进行
atomic.AddInt64(&counter, 1)
//当前goroutine从线程退出
runtime.Gosched()
}
}
func main() {
wg.Add(2)
go addCount()
go addCount()
wg.Wait()
fmt.Printf("counter: %d
", counter)
}
这里使用atomic.AddInt64函数来对一个整形数据进行加操作,另外一些有用的原子操作还有:atomic.StoreInt64() //写 , atomic.LoadInt64() //读 ,更多的原子操作函数请看atomic包中的声明。
使用互斥锁
对临界区的访问,可以使用互斥锁来进行
package main
import (
"fmt"
"runtime"
"sync"
)
var (
//counter为访问的资源
counter int64
wg sync.WaitGroup
mutex sync.Mutex
)
func addCount() {
defer wg.Done()
for count := 0; count < 2; count++ {
//加上锁,进入临界区域
mutex.Lock()
value := counter
//当前goroutine从线程退出
runtime.Gosched()
value++
counter = value
//离开临界区,释放互斥锁
mutex.Unlock()
}
}
func main() {
wg.Add(2)
go addCount()
go addCount()
wg.Wait()
fmt.Printf("counter: %d
", counter)
}
输出: counter: 4
使用Lock()与Unlock()函数调用来定义临界区,在同一个时刻内,只有一个goroutine能够进入临界区,直到调用Unlock()函数后,其他的goroutine才能够进入临界区。
在Go中解决共享资源安全访问,更常用的使用通道chan。
利用通道共享数据
CSP(Communicating Sequential Process)模型提供一种多个进程公用的“管道(channel)”, 这个channel中存放的是一个个”任务”.
目前正流行的go语言中的goroutine就是参考的CSP模型,原始的CSP中channel里的任务都是立即执行的,而go语言为其增加了一个缓存,即任务可以先暂存起来,等待执行进程准备好了再逐个按顺序执行.
Go语言采用CSP消息传递模型。通过在goroutine之间传递数据来传递消息,而不是对数据进行加锁来实现同步访问。这里就需要用到通道chan这种特殊的数据类型。当一个资源需要在goroutine中共享时,chan在goroutine中间架起了一个通道。通道使用make来创建:
unbuffered := make(chan int) //创建无缓存通道,用于int类型数据共享
buffered := make(chan string,10)//创建有缓存通道,用于string类型数据共享
buffered<- "hello world" //向通道中写入数据
value:= <-buffered //从通道buffered中接受数据
通道用于放置某一种类型的数据。创建通道时指定通道的大小,将创建有缓存的通道。无缓存通道是一种同步通信机制,它要求发送goroutine和接收goroutine都应该准备好,否则会进入阻塞。
无缓存的通道
无缓存通道是同步的——一个goroutine向channel写入消息的操作会一直阻塞,直到另一个goroutine从通道中读取消息。反过来也是,一个goroutine从channel读取消息的操作会一直阻塞,直到另一个goroutine向通道中写入消息。《Go in action》中关于无缓存通道的解释有一个非常棒的例子:网球比赛。在网球比赛中,两位选手总是处在以下两种状态之一:要么在等待接球,要么在把球打向对方。球的传递可看为通道中数据传递。下面这段代码使用通道模拟了这个过程:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var wg sync.WaitGroup
func player(name string, court chan int) {
defer wg.Done()
for {
//如果通道关闭,那么选手胜利
ball, ok := <-court
if !ok {
fmt.Printf(" %s Won
", name)
return
}
n := rand.Intn(100)
//随机概率使某个选手Miss
if n%13 == 0 {
fmt.Printf(" %s Missed
", name)
//关闭通道
close(court)
return
}
fmt.Printf(" %s Hit %d
", name, ball)
ball++
//否则选手进行击球
court <- ball
}
}
func main() {
rand.Seed(time.Now().Unix())
//创建无缓存channel
court := make(chan int)
//等待两个goroutine都执行完
wg.Add(2)
//选手1等待接球
go player("candy", court)
//选手2等待接球
go player("luffic", court)
//球进入球场(可以开始比赛了)
court <- 1
wg.Wait()
}
有缓存的通道
有缓存的通道是一种在被接收前能存储一个或者多个值的通道,它与无缓存通道的区别在于:无缓存的通道保证进行发送和接收的goroutine会在同一时间进行数据交换,有缓存的通道没有这种保证。有缓存通道让goroutine阻塞的条件为:通道中没有数据可读的时候,接收动作会被阻塞;通道中没有区域容纳更多数据时,发送动作阻塞。向已经关闭的通道中发送数据,会引发panic,但是goroutine依旧能从通道中接收数据,但是不能再向通道里发送数据。所以,发送端应该负责把通道关闭,而不是由接收端来关闭通道。
小结
- goroutine被逻辑处理器执行,逻辑处理器拥有独立的系统线程与运行队列
- 多个goroutine在一个逻辑处理器上可以并发执行,当机器有多个物理核心时,可通过多个逻辑处理器来并行执行。
- 使用关键字 go 来创建goroutine。
- 在Go中,竞争状态出现在多个goroutine试图同时去访问一个资源时,可以使用互斥锁或者原子函数,去防止竞争状态的出现。
- 在go中,更好的解决竞争状态的方法是使用通道来共享数据。
- 无缓冲通道是同步的,而有缓冲通道不是。