作业题:
1:文字回答:ResNet的shortcut connection与Highway Net有什么差别?
Highway networks也使用了带有门函数的shortcut。但是这些门函数需要参数,而ResNet的shortcut不需要参数。而且当Highway networks的门函数的shortcut关闭时,相当于没有了残差函数,但是ResNet的shortcut一直保证学习残差函数。而且,当Highway networks的层数急剧增加时,没有表现出准确率的上升了。总之,ResNet可以看成是Highway networks的特例,但是从效果上来看,要比Highway networks好。
2:文字回答:ResNet的训练曲线与GoogLenet的曲线为什么有明显差异?是什么原因导致的?
ResNet采用了预热训练,避免一开始较大学习率导致模型不稳定。训练一开始用较小的学习率训练一个epoch,然后恢复正常学习率。
Resnet还应用了随机梯度下降SGD以及shortcut,使得训练曲线比较陡。
3:文字回答:ResNet的shortcut connection有哪三种形式,请简述,并思考是否有其他方式?(提示:后面的模型会用concat,而不是相加)
A-全零填充:维度增加的部分用零来填充
B-网络层映射:当维度发生变化时,通过网络层映射(例如:1*1卷积)特征图至相同维度。特别注意:ResNet 50/101/152用的是B方案,这是一种折中的方案--维度没有变化时就是恒等变换,有变化时就是通过网络层映射。
C-所有Shortcur均通过网络层映射(例如1*1卷积)。虽然实验结果更好,但是没有在深度网络中使用。原因可能是由于怕导致模型的参数量过大。
4:文字回答:读完该论文,对你的启发点有哪些?
特征图修改在12~20分辨率时会产生较好效果?
残差元的主要设计有两个,快捷连接和恒等映射,快捷连接使得残差变得可能,而恒等映射使得网络变深。残差结构使得网络更容易学习,可能还有反馈的效果?
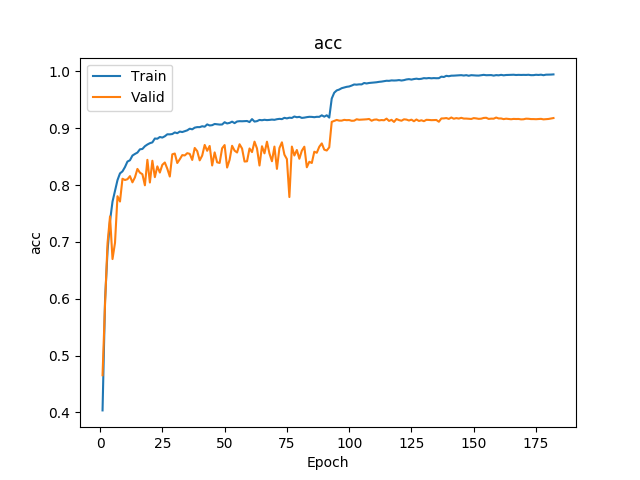
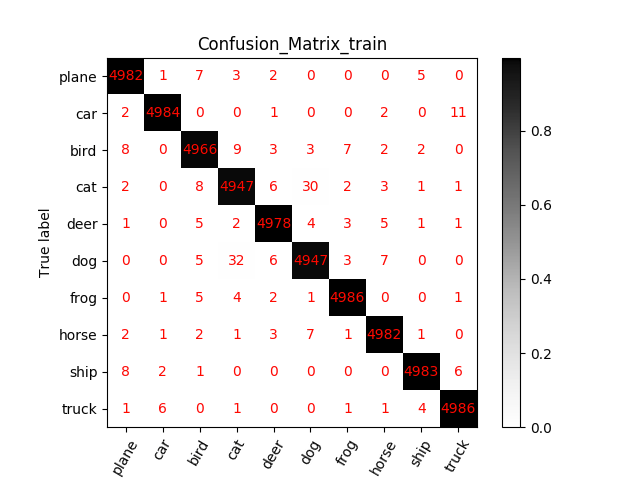
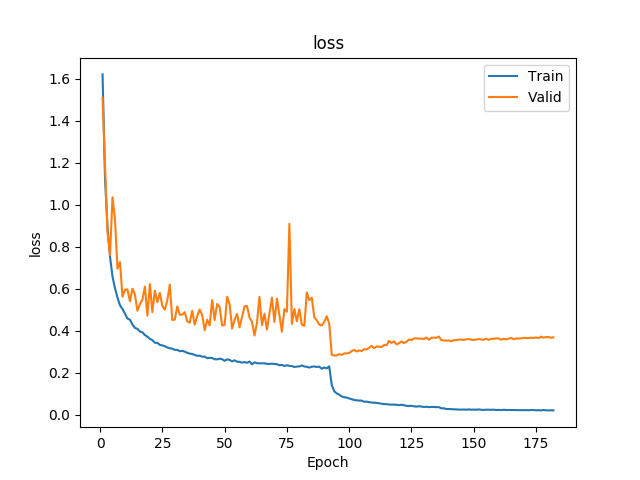
5:代码实现:在cifar-10上训练一个resnet20或34或56或者110或1202, 将训练曲线,混淆矩阵图等信息贴出来分享
测试:resnet18

resnet 20