转译☞:https://www.cs.rice.edu/~as143/COMP441_Spring17/scribe/lect4.pdf
1 大规模图片检索问题
基于树模型的算法在分类跟聚类中很受欢迎,然而对于高维数据来说,分类可能就不是那么有效了,因为有名声狼藉infamous维数诅咒的存在空间的划分随着维数成指数性增长,举个例子来说,如果一个图片有10个特征,对每个特征分成两组,总共就会呈现(2^{10})个分类。所以说空间划分的方法在检索相似的高维数据并不是很有用。
2哈希算法
2.1detour,换个思路,考虑一下更简单的问题
假定我们有一个充满整数的数组,我们想要知道这个数组是否包含了一个确定的整数,我们有三个算法用来解决这个问题:
- (O(N))的解法。 我们将给定的整数遍历数组中的所有整数进行两两对比。这个遍历花费了(O(N))的时间
- (O(logN))的解法。 为了减少时间复杂度,我们可以在检索前对数组数据进行预处理。我们将数组分割。尽管分割数组这个预处理需要花费时间,但是它有效的提升了检索的效率。
- (O(1))的解法。 为了更一步提高效率我们可以在预处理过程中使用哈希映射,因此我们可以得到一个哈希表去检索。对于给定的一个整数,平均起来会花费(O(1))的时间。
回到图片检索问题上。我们也可以使用哈希算法提高检索效率,。然而不同于传统哈希的是,这个哈希算法是用来比较两个图片的相似性,而不是精确的复制品。因为当用传统哈希算法时,两个非常相似的图片会拥有不同的哈希值,就不会满足相似性检索这个要求。
2.2标准哈希
一个哈希函数是一个映射:输入一个向量x并将其映射到一个离散的值Key
传统哈希也会有这样的性质:
传统的哈希不满足我们的要求,我们想要去评估两个图片经过哈希之后的相似性。传统的哈希会对两个不是完全相同但是非常相似的两张图片会返回不同的值。
2.3Locality sensitive hashing:广义化的哈希
LSH是哈希算法并且拥有概率松弛的性质probabilistic relaxation,LSH具有一下性质:
如果(similaruty(x,y))高,那么(probability(h(x)=h(y)))也高,相反的也有
如果(similaruty(x,y))低,那么(probability(h(x)=h(y)))也低。
不同于传统哈希的是,LSH以最大概率将两个相似的对象放入同一个桶中。通过LSH,我们可以对图片数据库进行预处理,以这种方法,我们可以降低图片数据的维度。在图片检索过程中,我们不用去计算两个图片的相似性,我们可以通过使用LSH计算哈希值来评估图片之间的相似性。
3formal LSH ,LSH的严格按表述
一个有效的近似最近邻检索工具,以locality sensitive hashing为底层理论。
LSH是一个函数族,它具有将相似的输入对象比不相似的输入对象有更高的几率在范围空间内发生碰撞。 考虑(cal H)一个哈希函数族将(cal R^D) 映射到离散集合[0,R-1]
定义:locality sensitive hashing LSH family ,如果(for any x,yin R^d) ,然后不带偏好的从函数族(cal H)选一个哈希函数h满足如下的性质:
- (if sim(x,y)geq s_0 then P_{r_cal H}(h(x)=h(y))geq p_1)
- (if sim(x,y)leq cs_0 then P_{r_cal H}(h(x)=h(y))leq p_2)
"Uniformly" means without applying any preference to a particular part of a region.
5关于相似性基本的想法
我们使用LSH对图片进行预处理。在图片库中,我们对,每一张图片都计算出哈希值,并且将他们放入桶中。为了提高精确度,我们重复几次这个的处理过程,得到多个哈希表,当一个要检索的图片来到时,我们使用相同的算法来计算出他的哈希值,再根据预处理得到的哈希表来找到相似文档。
因为LSH对两个相似图片以最大概率掉进同一个桶中,所以要要检索的图片掉入的桶中包含相似图片的概率就会非常高。
References
[1] http://cdn.iopscience.com/images/1749-4699/5/1/015004/full/csd422281fig1.jpg.
[2] https://www.facebook.com/notes/facebook-engineering/10-billion-photos/30695603919.
[3] Jure Leskovec, Anand Rajaraman, and Jeffrey David Ullman.Mining of massive datasets.Cambridge University Press, 2014
转译☞:https://www.cs.rice.edu/~as143/COMP441_Spring17/scribe/lect5.pdf
1 通过哈希进行亚线性检索
LSH是一个函数族,它们具有将其定义域内的相似的输入对象在范围空间中有更高的碰撞概率。考虑(cal H) 一个哈希函数族将(cal R^D)映射到离散的空间[0,R-1]中。
定义:locality sensitive hashing LSH family ,如果(for any x,yin R^d) ,然后不带偏好的从函数族(cal H)选一个哈希函数h满足如下的性质:
- (if sim(x,y)geq s_0 then P_{r_cal H}(h(x)=h(y))geq p_1)
- (if sim(x,y)leq cs_0 then P_{r_cal H}(h(x)=h(y))leq p_2)
通过(K,L)LSH算法进行亚线性检索:对于近似最近邻检索问题,为了将检索时间在sub-linear time内,思想是创造哈希表。对象集(cal C) ,通过LSH函数族创造哈希表。在经典的(K,L)-LSH算法中。我们生成了L个不同的元哈希函数(B_j(x)=[h_{j1}(x);h_{j2}(x);...;h_{jK}(x)],jin{1,2,...,L}) ,总共具有KL个适当的位置敏感哈希函数,每个元哈希函数都是由从哈希函数族中简单的哈希值串接得到的。最后得到的就有L个哈希表,
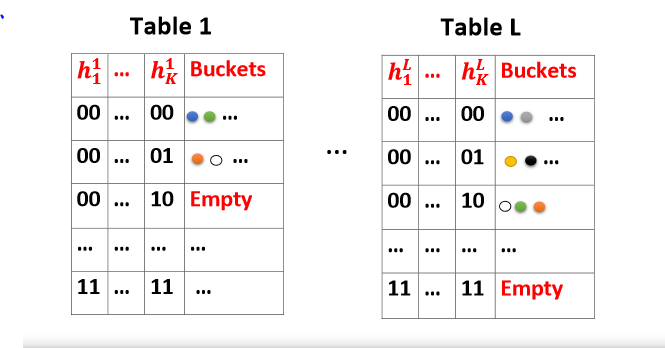
算法大体上可以分为两个阶段:
-
预处理阶段:我们从数据中通过将对象集所有的点,在第j个哈希表中方到位置(B_j(x))中,构建L个哈希表,在表中,我们只存储点而不是向量,因为向量在存储方面不是很有效率。
-
检索阶段:给定检索的对象Q,我们report在(B_j(Q) for jin {1,2,...,L}) 的所有点。这些点的个数一定比L多?我们不是扫描所有在对象集(cal C) 中的数据,我们仅仅是探测L个不同的哈希桶,每一个哈希桶都分别在不同的哈希表中,因此它是亚线性的。
已经被证明了对于一个给定相似度度量对额并且适当的选择(K=O(logn),L=O(n^ ho)) 的LSH函数族,是非常有效率的。
定理1(sub-linear search)对于一个((s_0,cs_0,p_1,p_2))-敏感的哈希函数,当(K=O(logn),L=O(n^ ho)),LSH解决近似最近邻检索仅需要(O(n^ ho log_{1/p_2}n))检索时间,( ho=frac{log(p_1)}{log(p_2)}<1)
2基于shingle的呈现
可以由一系列关于字母的标记来呈现文档。举个例子,文档:”This is Rice University“对于k=2,也就是2-shingles集合{This is,is Rice,Rice University}
大多数网络数据都是稀疏的或者近似二元的。现代的大数据系统仅仅使用二元稀疏矩阵。
Jaccard 相似度
两个集合(X,Ysubset Omega)的jaccard相似度得定义为:
对于二元的向量,对于每一个数字(0 or 1)在向量的坐标下代表着这个方向的元素存在与否。也就有
Minwise Hashing
算法:对于全体(Omega)选取一个随机排列(pi) ,i.e.
minhash:
也就是说每一次排列都会赋值新的行号,我们从最小的行号的那一行开始检索,出现第一个一个不为零的行号就是此列的minhash值
Binary vector view: the hash value of the vector is the smallest index that is not zero
Fingerprint:MinHash values can be used as fingerprint of data vector because the hash of one vector is independent of other vectors and Minhash values can be used to estimate similarity.
References
Shrivastava, Anshumali. COMP 441 Lecture5.pdf. 2017
Chapter 3 of Mining Massive Datasets Book (http://infolab.stanford.edu/~ullman/mmds/book.pdf)