Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了。
这篇就讲解hadoop双namenode的部署,实现高可用.
系统环境:
OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar.gz zookeeper-3.3.6.tar.gz
下载地址:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.3.6/zookeeper-3.3.6.tar.gz
主机列表信息:
|
主机名 |
IP 地址 |
安装软件 |
角色 |
运行服务 |
|
hadoop-01 |
192.168.153.128 |
Jdk,hadoop |
NameNode |
NameNode,ResourceManager,DFSZKFailoverController,QuorumPeerMain,JournalNode,JobHistoryServer |
|
hadoop-02 |
192.168.153.129 |
Jdk,hadoop |
NameNode、DataNode |
NameNode,ResourceManager,DFSZKFailoverController,QuorumPeerMain,JournalNode |
|
hadoop-03 |
192.168.153.130 |
Jdk,Hadoop zookeep |
DataNode |
DataNode,NodeManager,QuorumPeerMain, mapred,QuorumPeerMain |
1.Hosts文件设置(三台主机的host文件需要保持一致)
[root@hadoop-01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ####################################### 192.168.153.128 hadoop-01 192.168.153.129 hadoop-02 192.168.153.130 hadoop-03
2.创建hadoop账户,使用该账户运行hadoop服务(三台主机都创建hadoop用户).
创建hadoop用户,设置拥有sudo权限 [root@hadoop-01 ~]# useradd hadoop && echo hadoop | passwd --stdin hadoop Changing password for user hadoop. passwd: all authentication tokens updated successfully. [root@hadoop-01 ~]# echo "hadoop ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
3.生成SSH免秘钥认证文件(在三台主机都执行)
[root@hadoop-01 ~]# su - hadoop [hadoop@hadoop-01 ~]$ ssh-keygen -t rsa
4.SSH密钥认证文件分发
1.>将hadoop-01的公钥信息复制到另外两台机器上面 [hadoop@hadoop-01 ~]$ ssh-copy-id 192.168.153.128 [hadoop@hadoop-01 ~]$ ssh-copy-id 192.168.153.129 [hadoop@hadoop-01 ~]$ ssh-copy-id 192.168.153.130 2.>分发hadoop@hadoop-02的公钥到其他两台主机 hadoop@hadoop-02 ~]$ ssh-copy-id 192.168.153.128 [hadoop@hadoop-02 ~]$ ssh-copy-id 192.168.153.129 [hadoop@hadoop-02 ~]$ ssh-copy-id 192.168.153.130 3.>分发hadoop@hadoop-03的公钥到其他两台主机 [hadoop@hadoop-03 ~]$ ssh-copy-id 192.168.153.128 [hadoop@hadoop-03 ~]$ ssh-copy-id 192.168.153.129 [hadoop@hadoop-03 ~]$ ssh-copy-id 192.168.153.130 这样三台机器都可以互相免密钥访问, ssh-copy-id会以追加的方式进行密钥的分发
5.安装jdk(三台主机jdk安装)
[root@hadoop-01 ~]# rpm -ivh jdk-8u151-linux-x64.rpm Preparing... ########################################### [100%] 1:jdk1.8 ########################################### [100%] [root@hadoop-01 ~]# export JAVA_HOME=/usr/java/jdk1.8.0_151/ [root@hadoop-01 ~]# export PATH=$JAVA_HOME/bin:$PATH [root@hadoop-01 ~]# java -version java version "1.8.0_151" Java(TM) SE Runtime Environment (build 1.8.0_151-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
6、安装hadoop:
[hadoop@hadoop-01~]$ wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4-src.tar.gz [hadoop@hadoop-01 ~]$ sudo tar zxvf hadoop-2.7.4.tar.gz -C /home/hadoop/ && cd /home/hadoop [hadoop@hadoop-01 ~]$ sudo mv hadoop-2.7.4/ hadoop [hadoop@hadoop-01 ~]$ sudo chown -R hadoop:hadoop hadoop/ #将hadoop的二进制目录添加到PATH变量,并设置HADOOP_HOME环境变量 [hadoop@hadoop-01 ~]$ export HADOOP_HOME=/home/hadoop/hadoop/ [hadoop@hadoop-01 ~]$ export PATH=$HADOOP_HOME/bin:$PATH #在安装hadoop中,只需在hadoop-01上面下载和解压即可,配置完成后再同步到其他节点即可.
7、修改hadoop的配置文件
配置文件位置:/home/hadoop/hadoop/etc/hadoop
1.>修改hadoop-env.sh配置文件,指定JAVA_HOME为JAVA的安装路径.
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_151/
2.> 修改yarn-env.sh文件
指定yran框架的java运行环境,该文件是yarn框架运行环境的配置文件,需要修改JAVA_HOME的位置
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 修改为: export JAVA_HOME=/usr/java/jdk1.8.0_151/
3.> 修改slaves文件
指定DataNode数据存储服务器,将所有的DataNode的机器的主机名写入到此文件中,如下:
[hadoop@hadoop-01 hadoop]$ cat slaves hadoop-02 hadoop-03
4.>修改core-site.xml文件.在<configuration>……</configuration>中添加如下:
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-01:2181,hadoop-02:2181,hadoop-03:2181</value>
</property>
</configuration>
5.> 修改hdfs-site.xml配置文件,在<configuration>……</configuration>中添加如下:
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop-01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop-01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop-02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop-02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-01:8485;hadoop-02:8485;hadoop-03:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置:Fencing实现自动切换-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-01:9001</value>
<description># 通过web界面来查看HDFS状态 </description>
</property>
</configuration>
6.> 修改mapred-site.xml
指定Hadoop的MapReduce运行在YARN环境
[hadoop@hadoop-01 hadoop]$ cp mapred-site.xml.template mapred-site.xml [hadoop@hadoop-01 hadoop]$ vim mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-01:19888</value> </property> </configuration>
7.> 修改yarn-site.xml
#该文件为yarn架构的相关配置
<configuration>
<!-- Site specific YARN configuration properties -->
<!--HA配置-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--集群名字-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop-01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop-02</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop-01:8132</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop-02:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop-01:8130</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop-02:8130</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop-01:8131</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop-02:8131</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop-01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop-01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-01:2181,hadoop-02:2181,hadoop-03:2181</value>
</property>
<!--故障切换-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--HA配置结束-->
<!--shuffle配置-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--资源配置-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>98304</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>10</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>48</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
</configuration>
8.复制hadoop到其他节点.
[hadoop@hadoop-01 ~]$ scp -r /home/hadoop/hadoop/ 192.168.153.129:/home/hadoop/ [hadoop@hadoop-01 ~]$ scp -r /home/hadoop/hadoop/ 192.168.153.130:/home/hadoop/
zookeeper集群配置:
由于我的hosts和jdk在安装hadoop时已经配置好,此处就不在重复配置
下载zookeeper及修改配置:
[hadoop@hadoop-01 ~]$cd /opt/ #sudo wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.3.6/zookeeper-3.3.6.tar.gz [hadoop@hadoop-01 ~]$tar -zxvf zookeeper-3.3.6.tar.gz -C /home/hadoop/ [hadoop@hadoop-01 ~]$mv zookeeper-3.3.6/ zookeeper [hadoop@hadoop-01 ~]$cd zookeeper/conf [hadoop@hadoop-01 ~]$cp zoo_sample.cfg zoo.cfg [hadoop@hadoop-01 conf]$ vim zoo.cfg ickTime=2000 dataDir=/var/lib/zookeeper/ initLimit=5 syncLimit=2 clientPort=2181 server.1=hadoop_01:2888:3888 server.2=hadoop_02:2888:3888 server.3=hadoop_03:2888:3888
远程复制分发安装文件:
上面已经在hadoop-01上配置完成ZooKeeper,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下
[hadoop@hadoop-01 ~]$cd /home/hadoop/ [hadoop@hadoop-01 ~]$scp -r zookeeper/ 192.168.153.129:/home/hadoop/ [hadoop@hadoop-01 ~]$scp -r zookeeper/ 192.168.153.130:/home/hadoop/ [hadoop@hadoop-01 ~]$cd /home/hadoop/zookeeper/
设置myid文件要在每台机器的dataDir下,新建一个myid文件,里面存放一个数字,用来标识当前主机。
[hadoop@hadoop-01 ~]$ sudo -p mkdir /var/lib/zookeeper/ [hadoop@hadoop-01 ~]$ sudo chown -R hadoop.hadoop /var/lib/zookeeper/ [hadoop@hadoop-02 ~]$ sudo -p mkdir /var/lib/zookeeper/ [hadoop@hadoop-02 ~]$ sudo chown -R hadoop.hadoop /var/lib/zookeeper/ [hadoop@hadoop-03 ~]$ sudo -p mkdir /var/lib/zookeeper/ [hadoop@hadoop-03 ~]$ sudo chown -R hadoop.hadoop /var/lib/zookeeper/ [root@hadoop_01 ~]# echo "1" >> /var/lib/zookeeper/myid [root@hadoop_02 ~]# echo "2" >> /var/lib/zookeeper/myid [root@hadoop_03 ~]# echo "3" >> /var/lib/zookeeper/myid
启动ZooKeeper集群:
[hadoop@hadoop-01 zookeeper]$./zkServer.sh start [hadoop@hadoop-02 zookeeper]$./zkServer.sh start [hadoop@hadoop-03 zookeeper]$./zkServer.sh start [hadoop@hadoop-01 zookeeper]$ jps -ml 95779 org.apache.zookeeper.server.quorum.QuorumPeerMain /home/hadoop/zookeeper/bin/../conf/zoo.cfg 97003 sun.tools.jps.Jps –ml
启动hadoop集群服务:
首次初始化启动命令和之后启动的命令是不同的,首次启动比较复杂,步骤不对的话就会报错,不过之后就好了
首次启动命令:
1.首先启动各个节点的Zookeeper,在各个节点上执行以下命令(我的zookeeper集群在上面已经启动,此步骤可以省略.):
[hadoop@hadoop-01 zookeeper]$./zkServer.sh start
2.格式化formatZK,在某一个namenode节点执行如下命令,创建命名空间(我是在hadoop-01上面操作的).
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs zkfc –formatZK [hadoop@hadoop-01 ~]$ echo $? 0
验证:
连接hadoop客户端,查看是否存在hadoop-ha节点.
查看节点命令:ls / [hadoop@hadoop-01 ~]$ /home/hadoop/zookeeper/bin/zkCli.sh

3.启动journalnode (负责两个namenode之间的通信和数据同步):
我配置文件中配置了三个节点都是journalnode,所以三个节点都得启动journalnode
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start journalnode starting journalnode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-journalnode-hadoop-01.out [hadoop@hadoop-01 ~]$ jps 95779 QuorumPeerMain 114294 JournalNode 114588 Jps [hadoop@hadoop-02 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start journalnode starting journalnode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-journalnode-hadoop-02.out [hadoop@hadoop-02 ~]$ jps 29911 JournalNode 29592 QuorumPeerMain 29962 Jps [hadoop@hadoop-02 ~]$ [hadoop@hadoop-03 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start journalnode starting journalnode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-journalnode-hadoop-03.out [hadoop@hadoop-03 ~]$ jps 43591 QuorumPeerMain 44827 JournalNode 44877 Jps [hadoop@hadoop-03 ~]$
4.在主namenode节点格式化namenode和journalnode目录.
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs namenode -format ns 17/11/24 03:58:46 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop-01/192.168.153.128 STARTUP_MSG: args = [-format, ns] STARTUP_MSG: version = 2.7.4 17/11/24 03:58:50 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop-01/192.168.153.128 ************************************************************/ [hadoop@hadoop-01 ~]$ echo $? 0 [hadoop@hadoop-01 ~]$
5.在主namenode节点启动namenode进程
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start namenode starting namenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-namenode-hadoop-01.out
6.在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程!
[hadoop@hadoop-02 ~]$ /home/hadoop/hadoop/bin/hdfs namenode –bootstrapStandby [hadoop@hadoop-02 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start namenode starting namenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-namenode-hadoop-02.out
7.在两个namenode(Hadoop-01、hadoop-02)节点都执行以下命令.
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start zkfc [hadoop@hadoop-02 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start zkfc starting zkfc, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-zkfc-hadoop-02.out
8.在所有datanode节点都执行以下命令启动datanode.
[hadoop@hadoop-02 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start datanode starting datanode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-datanode-hadoop-02.out [hadoop@hadoop-03 ~]$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start datanode starting datanode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-datanode-hadoop-03.out
9.启动yarn分布式计算框架(ResourceManager:接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM))
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/sbin/start-yarn.sh
10.启动historyserver服务:JobHistoryServer
[hadoop@hadoop-01 hadoop]$ sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /home/hadoop/hadoop/logs/mapred-hadoop-historyserver-hadoop-01.out
三台主机查看分别运行的服务:
Hadoop-01:

Hadoop-02:

Hadoop-03:

13.查看HDFS分布式文件系统状态
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs dfsadmin -report
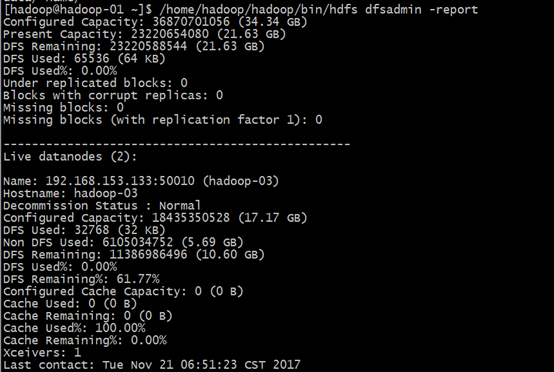
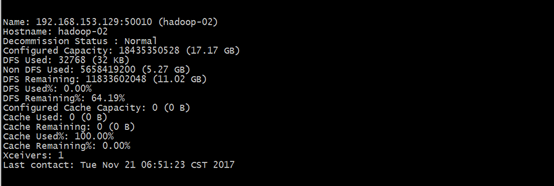
#查看文件块组成,一个文件由那些块组成
[hadoop@hadoop-01 ~]$ /home/hadoop/hadoop/bin/hdfs fsck / -files -blocks
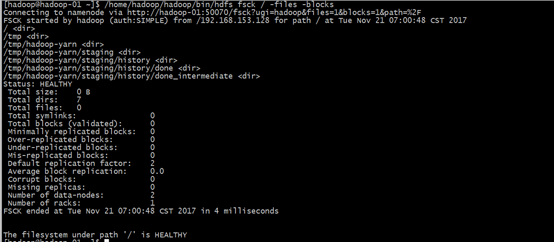
14. 日常启停命令
sbin/start-dfs.sh sbin/stop-dfs.sh 或者/sbin/start-all.sh /sbin/stop-all.sh 这两个包含(start-dfs.sh and start-yarn.sh)的启动和停止.
15. web页面查看hadoop集群状态
查看HDFS状态:http://192.168.153.128:50070

查看Hadoop集群状态: http://192.168.153.128:8088/cluster
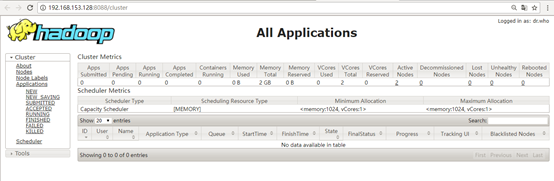
验证HDFS - HA主备切换:
1.验证Hadoop-01服务器NameNode和Hadoop-02服务器NameNode数据文件是否可以共享: 执行命令:./hdfs dfs -put /etc/hosts / [hadoop@hadoop-01 bin]$ ./hdfs dfs -put /etc/hosts / [hadoop@hadoop-01 bin]$ ./hdfs dfs -ls -h / Found 2 items drwxr-xr-x - hadoop supergroup 0 2017-11-24 04:17 /home -rw-r--r-- 2 hadoop supergroup 276 2017-11-24 04:34 /hosts [hadoop@hadoop-01 bin]$ 在hadoop-02上面执行查看/etc/hosts文件是否同步过来. [hadoop@hadoop-02 bin]$ [hadoop@hadoop-02 bin]$ ./hdfs dfs -ls -h / Found 2 items drwxr-xr-x - hadoop supergroup 0 2017-11-24 17:17 /home -rw-r--r-- 2 hadoop supergroup 276 2017-11-24 17:34 /hosts [hadoop@hadoop-02 bin]$ Hadoop-02上面文件存在,说明同步成功.
2.验证nameserver 主备切换.
首先在浏览器分别打开两个节点的namenode状态,其中一个显示active,另一个显示standby:
Hadoop-01访问地址:http://192.168.153.128:50070
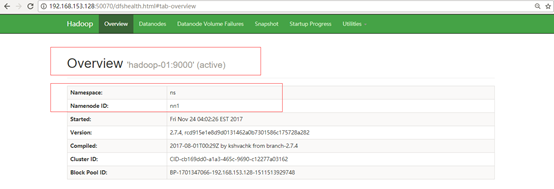
Hadoop-02访问地址:http://192.168.153.129:50070
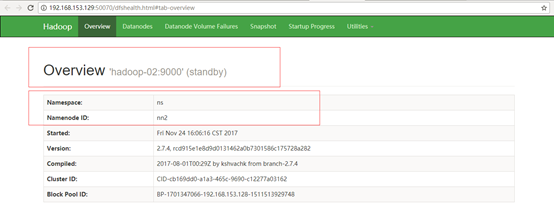
然后在active所在的namenode(Hadoop-01)节点执行jps,杀掉相应的namenode进程

前面standby所对应的namenode(Hadoop-02)变成active.
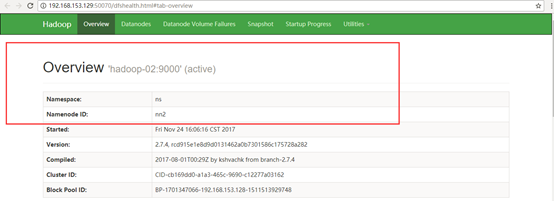
至此hadoop双namserver节点服务已经部署和测试成功.
参考文档: