1.Hadoop分布式文件系统(HDFS)
- HDFS基于GFS(Google File System),能够存储海量的数据,并且使用分布式网络客户端透明访问。
- HDFS中将文件拆分成特定大小的块结构(block-structured filesystem),一个文件的不同块存储在不同的节点中。
- 为了防止数据丢失,HDFS默认将一个块重复保存3份。
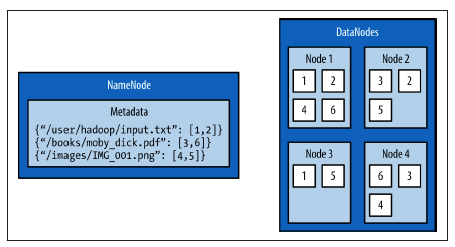
- HDFS的架构主要包括两个部分:NameNode和DataNode。
- NameNode保存整个文件系统的基础信息,例如:文件名,文件权限,文件每个块的存储位置等。为了能够快速访问获取信息,NameNode将这些基础信息保存在内存中。
- DataNodes是那些保存块(blocks)的机器,通常由大容量存储空间的廉价机器充当。
hadoop中常用文件操作命令
-
hdfs dfs -ls / (列出HDFS根目录的文件信息)
-
hdfs dfs -mkdir /user (在HDFS中创建目录)
-
hdfs dfs -put INPUT_PATH OUTPUT_PATH
-
hdfs dfs -cat
-
hdfs dfs -get
-
hadoop fs,hadoop dfs和hdfs dfs命令的区别:fs既能操作本地文件又能操作分布式文件系统,而dfs只能操作HDFS分布式文件系统。hadoop dfs已经废弃
2.MapReduce with Python
- MapReduce是一种编程模型,用它来将大量的数据计算任务划分成并行的独立的小任务。
- MapReduce框架主要包括3个阶段:map, shuffle and sort, and reduce(映射,混合和排序,规约)
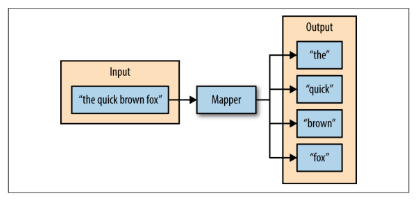
- Map阶段:maper函数分别处理系列键值对,产生零个或多个新的键值对。

- shuffle and sort:利用基于哈希的分割器给每确定每个键值对对于的reducer,并且进行排序。
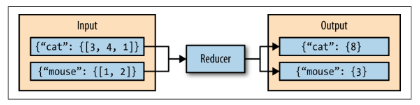
- Reduce阶段:利用reduce函数,将多个map阶段输出的键值对按照键对值进行合并,然后输出新的键值对。
- Hadoop streaming:maper和reducer都是按照一行一行的顺序从标准输入(stdin)读取数据,然后进行标准输出,maper的输出值为多个键值对,每个键值对用制表符(tab)分开。
3.Hadoop streaming
-
Hadoop Streaming工具的最大的好处是:能够让任何语言编写的map, reduce程序能够在hadoop集群上运行;map/reduce程序只要遵循从标准输入stdin读,写出到标准输出stdout即可。
-
另外一个方便之处就是:需要编写的map和reduce程序容易进行单机调试,通过管道前后相接的方式就可以模拟streaming, 在本地完成map/reduce程序的调试。
-
最后,streaming工具提供了丰富的参数来灵活控制作业的过程。
-
map/reduce作业是由一些可执行文件或脚本文件充当mapper或者reducer。
例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar
-input myInputDirs
-output myOutputDir
-mapper /bin/cat
-reducer /bin/wc
任何可执行文件都可以被指定为mapper/reducer。这些可执行文件不需要事先存放在集群上; 如果在集群上还没有,则需要用-file选项让framework把可执行文件作为作业的一部分,一起打包提交。
例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar
-input myInputDirs
-output myOutputDir
-mapper myPythonScript.py
-reducer /bin/wc
-file myPythonScript.py