word2vec
引入
一篇文章、一段话、一个句子是由一个个单词按照某个顺序组合而成。在自然语言处理的过程中不可避免地要考虑如何用计算机来表示一个词。
一种方法是One-hot Representation,即先将所有的词创建一个词库,并将每个词编号,然后词就用一个向量来表示,向量的长度与词库的大小相同,向量除了当前词编号的位置的分量为1外,其他位置分量都是0。这种表示方法简单,但是:1.通常向量的维数太高,2.无法描述词与词之间的相似性。
另一种表示方法是Distributed Representation ,即将一个词映射成一个K维向量,维度K相对较小,向量每个分量可以取到任意实数。
如果把一个词的表示向量坐标看成是空间中的一个点,那么用One-hot Representation时,不同词之间的距离总是一样的。而用Distributed Representation表示词时,就可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
先介绍一下统计语言模型。有文本序列(S=w_1, w_2, ... , w_T),假设位置(t)出现单词(w_t)的概率只与位置(t)之前的单词(w_1, w_2,...,w_{t-1})有关。那么序列(S)的概率可以表示为:
N-gram模型,就是上文窗口大小取N,位置(t)出现单词(w_t)的概率只与位置(t)之前的N个单词有关。
当N=2时,为bigram模型;当N=3时,为trigram模型。其他还有back-off trigram模型、interpolated trigram模型等。
N-gram模型存在的问题
- n-gram 语言模型复杂度高,无法建模更远的关系,如果N取太大,一是会导致语料库不足,二是导致计算量太大,大部分研究或工作都是使用Trigram,就算使用高阶的模型,其统计到的概率可信度就大打折扣,还有一些比较小的问题采用 Bigram。 (随着海量的数据积累和运算速度的提升,后来也有更高阶的语言模型开始使用。)
- 这种模型无法建模出词之间的相似度,有时候两个具有某种相似性的词,如果一个词经常出现在某段词之后,那么也许另一个词出现在这段词后面的概率也比较大,比如
The cat is walking in the bedroom.
A dog was running in a room.
如果第一句话里的元组在语料中出现的很多,训练的很充分,第二句话中的元组在语料中出现的少,训练的不充分,那么使用语言模型计算第一句话的概率就比较高,而第二句话的概率就低。 如果有一种方法,能知道The和a相似,cat和dog相似等等,并且会给相似的词类似的语言模型概率,那么第二句话也可以得到高概率。
3. 训练语料里面有些 n 元组没有出现过,其对应的条件概率就是 0,导致计算一整句话的概率为 0。解决方法包括平滑法和回退法。
n-pos 模型
n-pos 模型是N-gram模型的改进,它在计算第t个词的概率时,会考虑前面词的词性和语法功能。
此外还有基于决策树的语言模型,最大熵模型等。
神经网络语言模型
首先看一下深度学习(机器学习)领域最重要几个人物之间的关系图:

这图不由得引起了我的思考:到底是因为能够和大牛合作自己才成为大牛的,还是因为自己本来就是大牛才能和大牛在一起合作?(这话好像有语病,算了不想了。)
2003年,Bengio(就是图中间那位)等发表了一篇开创性的文章:A neural probabilistic language model。在这篇文章里,他们总结出了一套用神经网络建立统计语言模型的框架(Neural Network Language Model,简称NNLM),并首次提出了word embedding的概念(虽然没有叫这个名字),从而奠定了包括word2vec在内后续研究word representation learning的基础。
NNLM中,每个词被表示为一个浮点向量。
其模型图如下:

整个模型可以分成两个部分:
1.首先是一个线性的embedding层。它将输入的(n−1)个one-hot词向量,通过一个共享的(D×V)的矩阵(C),映射为(n−1)个分布式的词向量(distributed vector)。其中,(V)是词典的大小,(D)是embedding向量的维度(一个先验参数)。(C)矩阵里存储了要学习的word vector。
2.其次是一个简单的前向反馈神经网络(g)。它由一个tanh隐层和一个softmax输出层组成。通过将embedding层输出的(n−1)个词向量映射为一个长度为(V)的概率分布向量,从而对词典中的word在输入context下的条件概率做出预估:
输出层使用softmax函数处理得到概率值。
训练的目标函数就是加正则项的极大似然函数:
通过极大化(L( heta))的值求( heta)的值。参数( heta)包括矩阵(C)的值和神经网络的权重。
NNLM存在的问题:
1.同Ngram模型一样,NNLM模型只能处理定长的序列。
2.NNLM的训练太慢。
CBoW模型

从结构图可以看出,CBoW模型是基于上下文来预测当前词。输入的是词向量,中间层对向量求和,
输出当前词的概率。
在最后计算概率的过程中,可以利用Huffman编码树,将条件概率的成绩与编码数从根结点到叶节点的路径对应起来。从而将计算复杂度减小到log级别。

Skip-gram模型
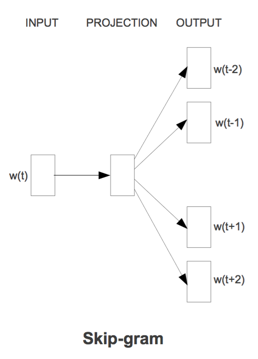
Skip-gram模型是用当前词来计算上下文的概率。
word2vec
word2vec,从广义上来讲指将词映射到连续向量(word embedding )的方法,狭义上来说,指的是Google开源的计算词向量的工具。在word2vec开源工具中可以使用CBoW模型或Skip-gram模型进行训练,虽然CBoW模型和Skip-gram模型最后得到的都是词的概率值,但是中间的embedding层可以作为词映射而成的向量。
参考:
http://www.cnblogs.com/iloveai/p/word2vec.html
http://blog.csdn.net/itplus/article/details/37969519
Deep Learning 实战之 word2vec 邓澍军、陆光明、夏龙 网易有道
http://blog.csdn.net/u014595019/article/details/51884529
https://cs224d.stanford.edu/lecture_notes/notes1.pdf
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/word2vec (v2).pdf