Prometheus内置了一个基于本地存储的时间序列数据库。在Prometheus设计上,使用本地存储可以降低Prometheus部署和管理的复杂度同时减少高可用(HA)带来的复杂性。
在默认情况下,用户只需要部署多套Prometheus,采集相同的Targets即可实现基本的HA。同时由于Promethus高效的数据处理能力,单个Prometheus Server基本上能够应对大部分用户监控规模的需求。
当然本地存储也带来了一些不好的地方,首先就是数据持久化的问题,特别是在像Kubernetes这样的动态集群环境下,如果Promthues的实例被重新调度,那所有历史监控数据都会丢失。
其次本地存储也意味着Prometheus不适合保存大量历史数据(一般Prometheus推荐只保留几周或者几个月的数据)。
最后本地存储也导致Prometheus无法进行弹性扩展。
为了适应这方面的需求,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据。通过将监控与数据分离,Prometheus能够更好地进行弹性扩展。
除了本地存储方面的问题,由于Prometheus基于Pull模型,当有大量的Target需要采样本时,单一Prometheus实例在数据抓取时可能会出现一些性能问题,联邦集群的特性可以让Prometheus将样本采集任务划分到不同的Prometheus实例中,并且通过一个统一的中心节点进行聚合,从而可以使Prometheuse可以根据规模进行扩展。
本地存储
Prometheus 2.x 采用自定义的存储格式将样本数据保存在本地磁盘当中。如下所示,按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每一个块中包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
t0 t1 t2 now
┌───────────┐ ┌───────────┐ ┌───────────┐
│ │ │ │ │ │ ┌────────────┐
│ │ │ │ │ mutable │ <─── write ──── ┤ Prometheus │
│ │ │ │ │ │ └────────────┘
└───────────┘ └───────────┘ └───────────┘ ^
└──────────────┴───────┬──────┘ │
│ query
│ │
merge ──────────────────────────────────┘
当前时间窗口内正在收集的样本数据,Prometheus则会直接将数据保存在内存当中。为了确保此期间如果Prometheus发生崩溃或者重启时能够恢复数据,Prometheus启动时会从写入日志(WAL)进行重播,从而恢复数据。此期间如果通过API删除时间序列,删除记录也会保存在单独的逻辑文件当中(tombstone)。
在文件系统中这些块保存在单独的目录当中,Prometheus保存块数据的目录结构如下所示:
./data
|- 01BKGV7JBM69T2G1BGBGM6KB12 # 块
|- meta.json # 元数据
|- wal # 写入日志
|- 000002
|- 000001
|- 01BKGTZQ1SYQJTR4PB43C8PD98 # 块
|- meta.json #元数据
|- index # 索引文件
|- chunks # 样本数据
|- 000001
|- tombstones # 逻辑数据
|- 01BKGTZQ1HHWHV8FBJXW1Y3W0K
|- meta.json
|- wal
|-000001
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。
同时该存储方式可以简化历史数据的删除逻辑。只要一个块的时间范围落在了配置的保留范围之外,直接丢弃该块即可。
|
┌────────────┐ ┌────┼─────┐ ┌───────────┐ ┌───────────┐
│ 1 │ │ 2 | │ │ 3 │ │ 4 │ . . .
└────────────┘ └────┼─────┘ └───────────┘ └───────────┘
|
|
retention boundary
本地存储配置
用户可以通过命令行启动参数的方式修改本地存储的配置。
| 启动参数 | 默认值 | 含义 |
|---|---|---|
| —storage.tsdb.path | data/ | Base path for metrics storage |
| —storage.tsdb.retention | 15d | How long to retain samples in the storage |
| —storage.tsdb.min-block-duration | 2h | The timestamp range of head blocks after which they get persisted |
| —storage.tsdb.max-block-duration | 36h | The maximum timestamp range of compacted blocks,It’s the minimum duration of any persisted block. |
| —storage.tsdb.no-lockfile | false | Do not create lockfile in data directory |
在一般情况下,Prometheus中存储的每一个样本大概占用1-2字节大小。如果需要对Prometheus Server的本地磁盘空间做容量规划时,可以通过以下公式计算:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
从上面公式中可以看出在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。因此有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。考虑到Prometheus会对时间序列进行压缩效率,减少时间序列的数量效果更明显。
从失败中恢复
如果本地存储由于某些原因出现了错误,最直接的方式就是停止Prometheus并且删除data目录中的所有记录。当然也可以尝试删除那些发生错误的块目录,不过相应的用户会丢失该块中保存的大概两个小时的监控记录。
远程存储
Prometheus的本地存储设计可以减少其自身运维和管理的复杂度,同时能够满足大部分用户监控规模的需求。但是本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展和迁移。
为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在Promthues中称为Remote Storage。
Remote Write
用户可以在Prometheus配置文件中指定Remote Write(远程写)的URL地址,一旦设置了该配置项,Prometheus将采集到的样本数据通过HTTP的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。

Remote Read
如下图所示,Promthues的Remote Read(远程读)也通过了一个适配器实现。在远程读的流程当中,当用户发起查询请求后,Promthues将向remote_read中配置的URL发起查询请求(matchers,ranges),Adaptor根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为Promthues的原始样本数据返回给Prometheus Server。
当获取到样本数据后,Promthues在本地使用PromQL对样本数据进行二次处理。
注意:启用远程读设置后,只在数据查询时有效,对于规则文件的处理,以及Metadata API的处理都只基于Prometheus本地存储完成。

配置文件
Prometheus配置文件中添加remote_write和remote_read配置,其中url用于指定远程读/写的HTTP服务地址。如果该URL启动了认证则可以通过basic_auth进行安全认证配置。对于https的支持需要设定tls_concig。proxy_url主要用于Prometheus无法直接访问适配器服务的情况下。
remote_write和remote_write具体配置如下所示:
remote_write:
url: <string>
[ remote_timeout: <duration> | default = 30s ]
write_relabel_configs:
[ - <relabel_config> ... ]
basic_auth:
[ username: <string> ]
[ password: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: /path/to/bearer/token/file ]
tls_config:
[ <tls_config> ]
[ proxy_url: <string> ]
remote_read:
url: <string>
required_matchers:
[ <labelname>: <labelvalue> ... ]
[ remote_timeout: <duration> | default = 30s ]
[ read_recent: <boolean> | default = false ]
basic_auth:
[ username: <string> ]
[ password: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: /path/to/bearer/token/file ]
[ <tls_config> ]
[ proxy_url: <string> ]
使用Influxdb作为Remote Storage
目前Prometheus社区也提供了部分对于第三方数据库的Remote Storage支持:
| 存储服务 | 支持模式 |
|---|---|
| AppOptics | write |
| Chronix | write |
| Cortex: | read/write |
| CrateDB | read/write |
| Gnocchi | write |
| Graphite | write |
| InfluxDB | read/write |
| OpenTSDB | write |
| PostgreSQL/TimescaleDB: | read/write |
| SignalFx | write |
这里将介绍如何使用Influxdb作为Prometheus的Remote Storage,从而确保当Prometheus发生宕机或者重启之后能够从Influxdb中恢复和获取历史数据。
这里使用docker-compose定义并启动Influxdb数据库服务,docker-compose.yml定义如下:
version: '2'
services:
influxdb:
image: influxdb:1.3.5
command: -config /etc/influxdb/influxdb.conf
ports:
- "8086:8086"
environment:
- INFLUXDB_DB=prometheus
- INFLUXDB_ADMIN_ENABLED=true
- INFLUXDB_ADMIN_USER=admin
- INFLUXDB_ADMIN_PASSWORD=admin
- INFLUXDB_USER=prom
- INFLUXDB_USER_PASSWORD=prom
启动influxdb服务
$ docker-compose up -d
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
795d0ead87a1 influxdb:1.3.5 "/entrypoint.sh -c..." 3 hours ago Up 3 hours 0.0.0.0:8086->8086/tcp localhost_influxdb_1
获取并启动Prometheus提供的Remote Storage Adapter:
go get github.com/prometheus/prometheus/documentation/examples/remote_storage/remote_storage_adapter
获取remote_storage_adapter源码后,go会自动把相关的源码编译成可执行文件,并且保存在$GOPATH/bin/目录下。
启动remote_storage_adapter并且设置Influxdb相关的认证信息:
INFLUXDB_PW=prom $GOPATH/bin/remote_storage_adapter -influxdb-url=http://localhost:8086 -influxdb.username=prom -influxdb.database=prometheus -influxdb.retention-policy=autogen
修改prometheus.yml添加Remote Storage相关的配置内容:
remote_write:
- url: "http://localhost:9201/write"
remote_read:
- url: "http://localhost:9201/read"
重新启动Prometheus能够获取数据后,登录到influxdb容器,并验证数据写入。如下所示,当数据能够正常写入Influxdb后可以看到Prometheus相关的指标。
docker exec -it 795d0ead87a1 influx
Connected to http://localhost:8086 version 1.3.5
InfluxDB shell version: 1.3.5
> auth
username: prom
password:
> use prometheus
> SHOW MEASUREMENTS
name: measurements
name
----
go_gc_duration_seconds
go_gc_duration_seconds_count
go_gc_duration_seconds_sum
go_goroutines
go_info
go_memstats_alloc_bytes
go_memstats_alloc_bytes_total
go_memstats_buck_hash_sys_bytes
go_memstats_frees_total
go_memstats_gc_cpu_fraction
go_memstats_gc_sys_bytes
go_memstats_heap_alloc_bytes
go_memstats_heap_idle_bytes
当数据写入成功后,停止Prometheus服务。同时删除Prometheus的data目录,模拟Promthues数据丢失的情况后重启Prometheus。打开Prometheus UI如果配置正常,Prometheus可以正常查询到本地存储以删除的历史数据记录。
联邦集群
对于大部分监控规模而言,我们只需要在每一个数据中心(例如:EC2可用区,Kubernetes集群)安装一个Prometheus Server实例,就可以在各个数据中心处理上千规模的集群。同时将Prometheus Server部署到不同的数据中心可以避免网络配置的复杂性。
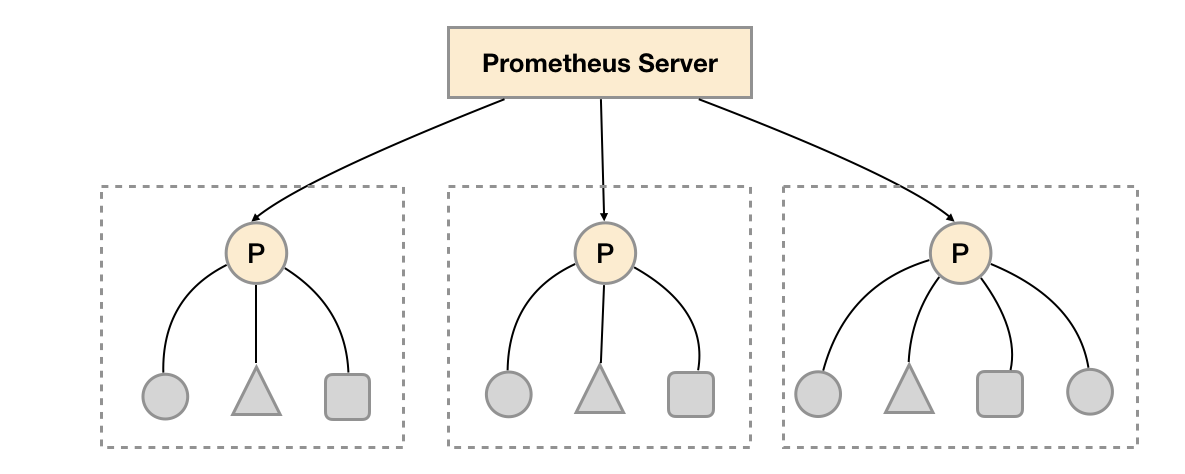
如上图所示,在每个数据中心部署单独的Prometheus Server,用于采集当前数据中心监控数据。并由一个中心的Prometheus Server负责聚合多个数据中心的监控数据。这一特性在Promthues中称为联邦集群。
联邦集群的核心在于每一个Prometheus Server都包含额一个用于获取当前实例中监控样本的接口/federate。对于中心Prometheus Server而言,无论是从其他的Prometheus实例还是Exporter实例中获取数据实际上并没有任何差异。
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.77.11:9090'
- '192.168.77.12:9090'
为了有效的减少不必要的时间序列,通过params参数可以用于指定只获取某些时间序列的样本数据,例如
"http://192.168.77.11:9090/federate?match[]={job%3D"prometheus"}&match[]={__name__%3D~"job%3A.*"}&match[]={__name__%3D~"node.*"}"
通过URL中的match[]参数指定我们可以指定需要获取的时间序列。match[]参数必须是一个瞬时向量选择器,例如up或者{job=”api-server”}。配置多个match[]参数,用于获取多组时间序列的监控数据。
horbor_labels配置true可以确保当采集到的监控指标冲突时,能够自动忽略冲突的监控数据。如果为false时,prometheus会自动将冲突的标签替换为”exported_“的形式。
功能分区
联邦集群的特性可以帮助用户根据不同的监控规模对Promthues部署架构进行调整。例如如下所示,可以在各个数据中心中部署多个Prometheus Server实例。每一个Prometheus Server实例只负责采集当前数据中心中的一部分任务(Job),例如可以将不同的监控任
务分离到不同的Prometheus实例当中,再有中心Prometheus实例进行聚合。
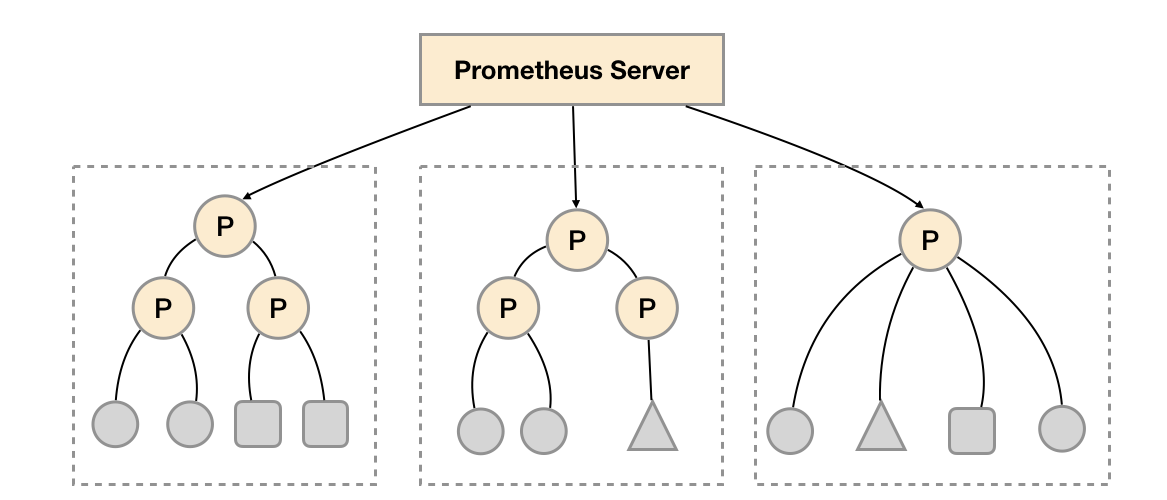
功能分区,即通过联邦集群的特性在任务级别对Prometheus采集任务进行划分,以支持规模的扩展。