参考链接:https://www.makcyun.top/web_scraping_withpython2.html
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from multiprocessing.pool import Pool
import pandas as pd
import requests
from sqlalchemy import create_engine
# 数据库相关信息
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'top500'
USERNAME = 'root'
PASSWORD = 'root'
SQLALCHEMY_DATABASE_URI = "mysql+mysqlconnector://{username}:{password}@{host}:{port}/{db}?charset=utf8mb4".format(
username=USERNAME,
password=PASSWORD,
host=HOSTNAME,
port=PORT,
db=DATABASE)
SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLALCHEMT_ENCODING = 'utf8mb4'
engine = create_engine(SQLALCHEMY_DATABASE_URI, echo=True)
# 获取网页收据
def get_one_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
# 保存到csv文件
def save_csv(html):
dataframe = pd.read_html(html)
tb = dataframe[0].drop([0]) # 获取网页数据中的第一个表格数据,然后再去掉第一个表格数据中的的第一行(去掉的话csv文件中没有列名,不去掉的话多次写入列名)
# tb.columns = ['rank', 'site', 'system', 'cores', 'rmax', 'rpeak', 'power'] # 重命名列名
tb.to_csv(r'top500.csv', mode='a', encoding='utf_8_sig', index=True, header=False) #
def save_mysql(html):
dataframe = pd.read_html(html)
tb = dataframe[0].drop([0])
tb.columns = ['rank', 'site', 'system', 'cores', 'rmax', 'rpeak', 'power']
try:
tb.to_sql('top500', con=engine, if_exists='append', index=False) # 需要事先建好top500数据表,并注意字段名称跟数据列名一一对应,字段值的长度要足够
print('success')
except:
print('fail')
def main(offset):
url = 'https://www.top500.org/list/2018/11/?page=' + str(offset)
html = get_one_page(url)
# save_csv(html)
save_mysql(html)
if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(1, 6)])
csv文件效果:

csv文件待优化的地方:加上列名
mysql效果:
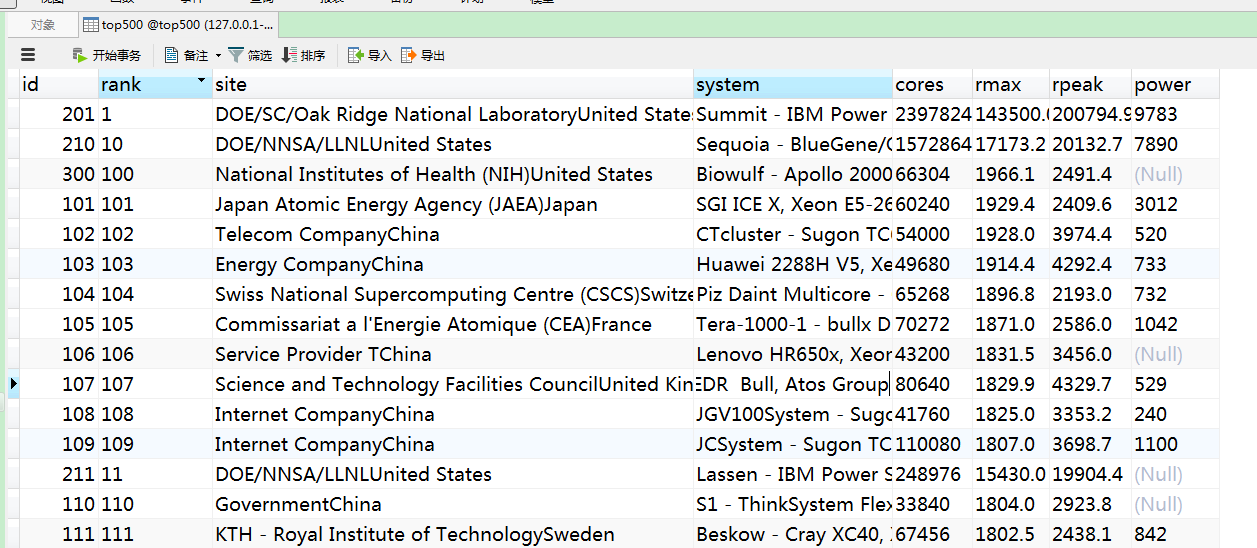
问题:
1.不论是csv文件还是mysql表格数据,根据rank字段进行排序,竟然排序的不怎么准确
2.site字段的最后部分数据是国家,这个需要想办法给剥离出来,再弄一列数据展示