参考链接:https://www.makcyun.top/web_scraping_withpython3.html
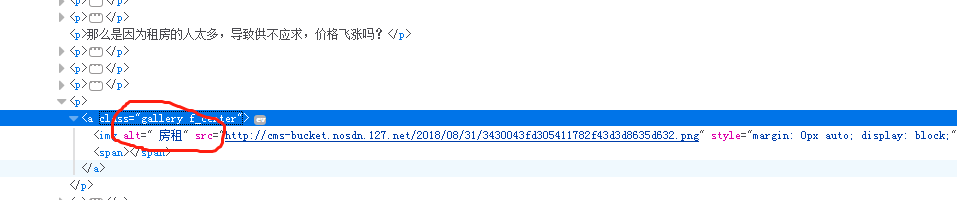
该网页其实有16张图片,但是因为页面数据中某处多个空白,导致参考链接中的方式只有15张图片,并且亲测有些方式能用,有些方式不能用,特此记录一下
正常显示:

不正常显示:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import random
import re
import requests
from bs4 import BeautifulSoup
from lxml import etree
from pyquery import PyQuery as pq
from requests import RequestException
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
}
def get_one_page():
url = 'http://data.163.com/18/0901/01/DQJ3D0D9000181IU.html'
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except RequestException:
print('网页请求失败')
return None
### 如下是解析网页数据的5中方式
# 正则表达式
def parse_one_page1(html):
pattern = re.compile('<img alt=".*?租" src="(.*?)"', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'url': item
}
# Xpath语法 # 使用这个('*//p//img[@alt = "房租"]/@src') 则结果只有15条,因为有个alt参数中房租前面有空格
def parse_one_page2(html):
parse = etree.HTML(html)
items = parse.xpath('*//img[@style="margin: 0px auto; display: block;" ]/@src')
for item in items:
yield {
'url': item
}
# CSS选择器,结果有8条,还有待研究
def parse_one_page3(html):
soup = BeautifulSoup(html, 'lxml')
items = soup.select('p a img')
# print(items)
for item in items:
yield {
'url': item['src']
}
# Beautiful Soup + find_all函数提取 结果有8条,还有待研究
def parse_one_page4(html):
soup = BeautifulSoup(html, 'lxml')
item = soup.find_all(attrs={'width': '100%', 'style': 'margin: 0px auto; display: block;'})
print(item)
for i in range(len(item)):
url = item[i].attrs['src']
yield {
'url': url
}
# PyQuery
def parse_one_page5(html):
data = pq(html)
data2 = data('p>a>img')
for item in data2.items():
yield {
'url': item.attr('src')
}
def download_thumb(url, name):
print(url, name)
try:
response = requests.get(url)
with open(name + '.jpg', 'wb') as f:
f.write(response.content)
except RequestException as e:
print(e)
pass
def main():
html = get_one_page()
items = parse_one_page5(html)
for item in items:
# print(item['url'])
download_thumb(item['url'], str(random.randint(1, 1000)))
if __name__ == '__main__':
main()
注:下载保存图片的函数还能再优化一下,不过懒得弄了,直接上随机数,哈哈