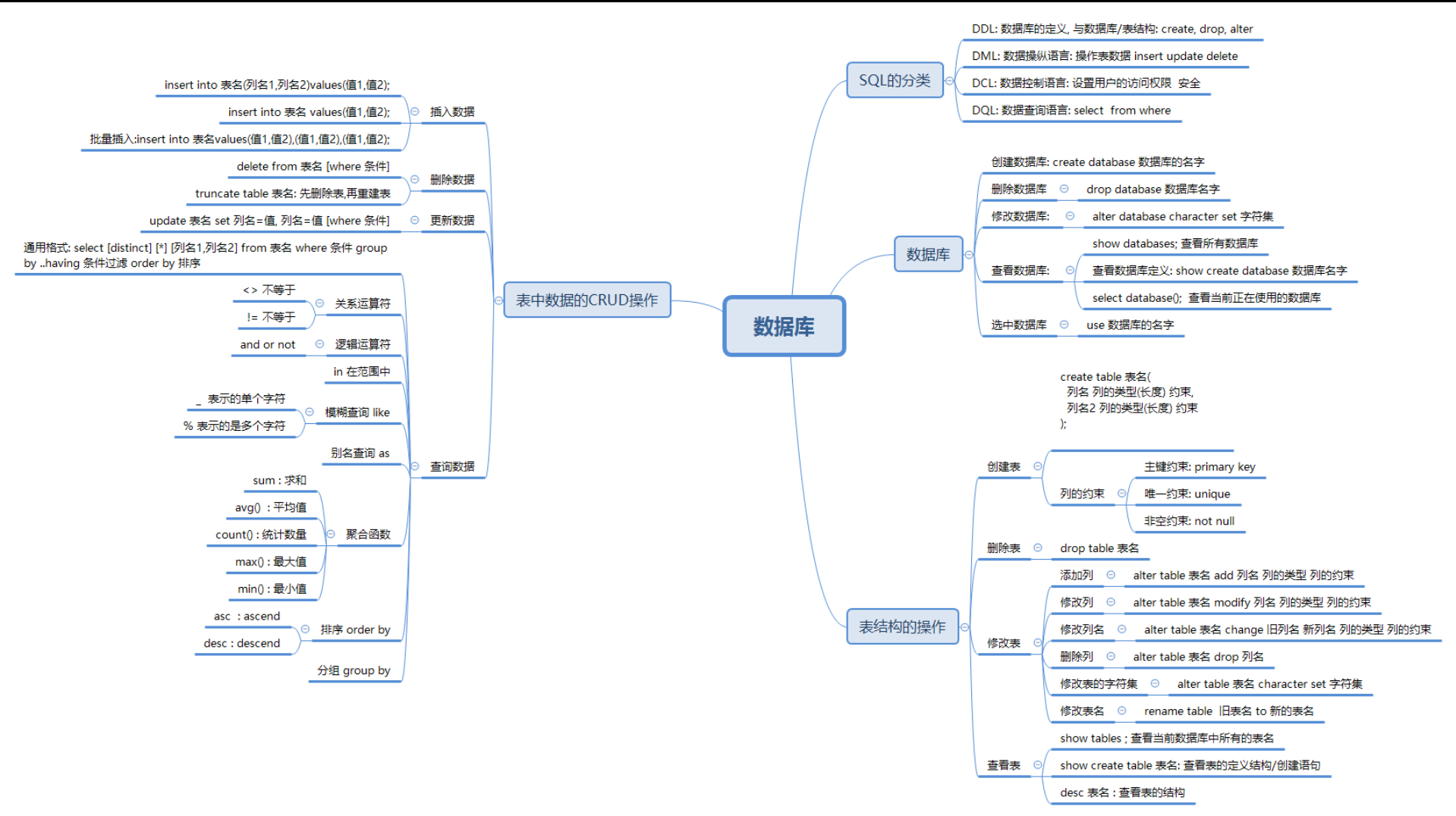

1 数据库操作sql练习 2 一、数据库的创建: 3 1、创建一个名称为mydb1的数据库 4 create database mydb1; 5 2、创建一个使用utf8字符集的mydb2数据库。 6 create database mydb2 character set utf8; 7 3、创建一个使用utf8字符集,并带比较规则的mydb3数据库。 8 create database mydb3 character set utf8 collate utf8_general_ci; 9 二、数据库的修改: 10 修改mydb2字符集为gbk; 11 alter database mydb2 character set gbk; 12 三、数据库的删除: 13 删除数据库mydb3。 14 drop database mydb3; 15 四、数据库查看: 16 查看所有数据库。 17 show databases; 18 查看数据库mydb1的字符集 19 show create database mydb1; 20 ----------------------------------------------- 21 数据库中表操作的sql练习 22 一、创建表 23 1、创建一张员工表employee 24 字段 类型 25 id 整形 26 name 字符型 27 gender 字符型 28 birthday 日期型 29 entry_date 日期型 30 job 字符型 31 salary 小数型 32 resume 文本 33 2、创建一张员工表employee2 34 字段 类型 35 id 整形 36 name 字符型 37 gender 字符型 38 birthday 日期型 39 entry_date 日期型 40 job 字符型 41 salary 小数型 42 resume 文本 43 要求:把id 设置成主键,并且自动增长。name不允许为空。 44 45 create table employee (id int primary key auto_increment, 46 name varchar(20) not null, 47 gender varchar(10), 48 birthday date, 49 entry_date date, 50 job varchar(30), 51 salary double, 52 resume text 53 ); 54 55 二、删除表 56 1、删除employee2表 57 drop table employee; 58 三、数据表的结构的修改: 59 1、在上面员工表的基本上增加一个image列。 60 alter table employee add image varchr(20); 61 2、修改job列,使其长度为60。 62 alter table employee modify job varchar(60); 63 3、删除gender列。 64 alter table employee drop gender; 65 4、表名改为user。 66 rename table employee to user; 67 5、修改表的字符集为utf8 68 alter table user character set utf8; 69 6、列名name修改为username 70 alter table user change name username varchar(20) not null; 71 四、查看表结构 72 1、查看数据库内的所有表 73 show tables; 74 2、查看employee的建表语句 75 show create table employee; 76 3、查看employee的表结构 77 desc employee; 78 ---------------------------------------------------- 79 表记录的操作 80 一、插入语句 ---insert 81 1、向employee中插入三个员工信息,要求员工姓名分别是zs,ls,wangwu 82 二、更新语句 ---update 83 1、将所有员工薪水修改为5000元。 84 update employee set salary=5000 ; 85 2、将姓名为’zs’的员工薪水修改为3000元。 86 update employee set salary=3000 where name='zs'; 87 3、将姓名为’ls’的员工薪水修改为4000元,job改为ccc。 88 update employee set salary=3000,job='ccc' where name='ls'; 89 4、将wangwu的薪水在原有基础上增加1000元。 90 update employee set salary=salary+1000 where name='wangwu'; 91 92 三、删除语句 ---delete 93 1、删除表中名称为’zs’的记录。 94 delete from employee where name='ls'; 95 2、删除表中所有记录。 96 delete from employee; 97 四、查询语句 ---select 98 create table exam( 99 id int primary key auto_increment, 100 name varchar(20) not null, 101 chinese double, 102 math double, 103 english double 104 ); 105 insert into exam values(null,'关羽',85,76,70); 106 insert into exam values(null,'张飞',70,75,70); 107 insert into exam values(null,'赵云',90,65,95); 108 insert into exam values(null,'刘备',97,50,50); 109 insert into exam values(null,'曹操',90,89,80); 110 insert into exam values(null,'司马懿',90,67,65); 111 练习: 112 1、查询表中所有学生的信息。 113 select * from exam; 114 2、查询表中所有学生的姓名和对应的英语成绩。 115 select name,english from exam; 116 3、过滤表中重复数据。 117 118 4、在所有学生分数上加10分特长分。 119 120 5、统计每个学生的总分。 121 select *,chinese+math+english from exam; 122 6、使用别名表示学生分数。 123 select *,chinese+math+english as 总分 from exam; 124 -----使用where子句 125 7、查询姓名为刘备的学生成绩 126 select * from exam where name='刘备'; 127 8、查询英语成绩大于90分的同学 128 select * from exam where english>90; 129 9、查询总分大于200分的所有同学 130 select * from exam where chinese+math+english>200; 131 10、查询英语分数在 80-90之间的同学。 132 select * from exam where english between 80 and 90; 133 select * from exam where english>=80 and english<=90; 134 11、查询数学分数为89,75,91的同学。 135 select * from exam where math=89 or math=75 or math=91; 136 select * from exam where math in(89,75,91); 137 12、查询所有姓刘的学生成绩。 138 select * from exam where name like '刘%'; 139 13、查询所有姓刘两个字的学生成绩。 140 select * from exam where name like '刘_'; 141 14、查询数学分>80并且语文分>80的同学。 142 select * from exam where math>80 and chinese>80; 143 15、查询数学分>80 或者 语文分>80的同学。 144 select * from exam where math>80 or chinese>80; 145 ------使用order by 排序 146 16、对数学成绩排序后输出。 147 select * from exam order by math; 148 17、对总分排序按从高到低的顺序输出 149 select *,chinese+math+english as 总分 from exam order by 总分 desc; 150 select *,chinese+math+english as 总分 from exam order by chinese+math+ 151 english desc; 152 18、对姓刘的学生成绩排序输出 153 select * from exam where name like '刘%' order by math desc; 154 ------使用count(函数) 155 19、统计一个班级共有多少学生? 156 select count(id) from exam; 157 20、统计数学成绩大于或等于90的学生有多少个? 158 select count(math) from exam where math>=90; 159 21、统计总分大于250的人数有多少? 160 select count(id) from exam where chinese+math+english>250; 161 -------使用sum函数 162 22、统计一个班级数学总成绩? 163 selcet * from exam; 164 23、统计一个班级语文、英语、数学各科的总成绩 165 select sum(chinese),sum(math),sum(english) from exam; 166 24、统计一个班级语文、英语、数学的成绩总和 167 select sum(chinese)+sum(math)+sum(english) from exam; 168 25、统计一个班级语文成绩平均分 169 select sum(chinese)/count(id) from exam; 170 --------使用avg函数 171 26、求一个班级数学平均分? 172 select avg(math) from exam; 173 27、求一个班级总分平均分 174 select avg(ifnull(chinese,0))+avg(ifnull(math,0))+avg(ifnull(english,0)) 175 from exam; 176 -------使用max,min函数 177 28、求班级最高分和最低分(数值范围在统计中特别有用) 178 select max(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam; 179 select min(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam; 180 181 create table orders( 182 id int, 183 product varchar(20), 184 price float 185 ); 186 187 insert into orders(id,product,price) values(1,'电视',900); 188 insert into orders(id,product,price) values(2,'洗衣机',100); 189 insert into orders(id,product,price) values(3,'洗衣粉',90); 190 insert into orders(id,product,price) values(4,'桔子',9); 191 insert into orders(id,product,price) values(5,'洗衣粉',90); 192 193 29、查询购买了几类商品,并且每类总价大于100的商品 194 195 select product,sum(price) from orders where price>100 group by product; 196
1 CREATE TABLE emp( 2 empno INT, 3 ename VARCHAR(50), 4 job VARCHAR(50), 5 mgr INT, 6 hiredate DATE, 7 sal DECIMAL(7,2), 8 comm DECIMAL(7,2), 9 deptno INT 10 ) ; 11 12 INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20); 13 INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30); 14 INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30); 15 INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20); 16 INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30); 17 INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30); 18 INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10); 19 INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20); 20 INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10); 21 INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30); 22 INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20); 23 INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30); 24 INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20); 25 INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10); 26 INSERT INTO emp VALUES(7981,'MILLER','CLERK',7788,'1992-01-23',2600,500,20); 27 28 CREATE TABLE dept( 29 deptno INT, 30 dname VARCHAR(14), 31 loc VARCHAR(13) 32 ); 33 34 INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK'); 35 INSERT INTO dept VALUES(20, 'RESEARCH', 'DALLAS'); 36 INSERT INTO dept VALUES(30, 'SALES', 'CHICAGO'); 37 INSERT INTO dept VALUES(40, 'OPERATIONS', 'BOSTON'); 38 -- 单行子查询(> < >= <= = <>) 39 -- 查询出高于10号部门的平均工资的员工信息 40 SELECT * FROM emp WHERE sal >(SELECT AVG(sal) FROM emp WHERE deptno=10 ); 41 -- 多行子查询(in not in any all) 42 -- 查询出比10号部门任何员工薪资高的员工信息 43 SELECT * FROM emp WHERE sal > ANY(SELECT sal FROM emp WHERE deptno=10) AND deptno!=10; 44 -- 多列子查询(实际使用较少) 45 -- 和10号部门同名同工作的员工信息 46 SELECT * FROM emp WHERE (ename,job)IN(SELECT ename,job FROM emp WHERE deptno=10) AND deptno!=10; 47 -- select 后面接子查询 48 -- 获取员工的名字和部门的名字 49 SELECT p.ename,d.dname FROM emp p,dept d WHERE p.deptno=d.deptno; 50 -- from 后面接子查询 51 -- 查询emp表中经理信息 52 SELECT * FROM emp e,(SELECT DISTINCT mgr FROM emp) AS jingli WHERE e.empno=jingli.mgr; 53 -- where 后面接子查询 54 -- 薪资高于10号部门平均工资的所有员工信息 55 SELECT * FROM emp WHERE sal>(SELECT AVG(sal) FROM emp WHERE deptno=10); 56 -- group by 后面接子查询 57 -- 有哪些部门的平均工资高于30号部门的平均工资 58 SELECT deptno, AVG(sal) AS bumen FROM emp GROUP BY deptno HAVING bumen > (SELECT AVG(sal) FROM emp WHERE deptno=30); 59 -- 工资>JONES工资 60 61 SELECT * FROM emp WHERE sal>(SELECT sal FROM emp WHERE ename='JONES'); 62 -- 查询与SCOTT同一个部门的员工 63 SELECT * FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename='SCOTT') AND ename!='SCOTT'; 64 -- 工资高于30号部门所有人的员工信息 65 SELECT * FROM emp WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno=30); 66 -- 查询工作和工资与MARTIN完全相同的员工信息 67 SELECT job,sal FROM emp WHERE ename='MARTIN'; 68 SELECT * FROM emp WHERE (job,sal)IN(SELECT job,sal FROM emp WHERE ename='MARTIN'); 69 -- 有两个以上直接下属的员工信息 70 -- 得出两个以上的经理信息 71 SELECT mgr,COUNT(mgr) FROM emp GROUP BY mgr HAVING COUNT(*) >2; 72 -- 得出两个以上直接下属的员工信息 73 SELECT * FROM emp WHERE empno IN (SELECT mgr FROM emp GROUP BY mgr HAVING COUNT(mgr) >2); 74 -- 老师的方法 75 SELECT * FROM emp e1 WHERE e1.empno IN (SELECT e2.mgr FROM emp e2 GROUP BY e2.mgr HAVING COUNT(*)>2); 76 77 -- 查询员工编号为7788的员工名称,员工工资,部门名称,部门地址 78 SELECT e.*,d.loc FROM emp e,dept d WHERE e.empno=7788 AND e.deptno=d.deptno; 79 -- 1. 查询出高于本部门平均工资的员工信息- 80 SELECT *,AVG(sal) AS 平均工资 FROM emp GROUP BY deptno; 81 SELECT * FROM emp e WHERE sal > (SELECT AVG(sal) AS 平均工资 FROM emp d GROUP BY deptno HAVING e.deptno=d.deptno); 82 -- 方式二: 83 -- SELECT * FROM emp e1 WHERE e1.sal > (SELECT AVG(e2.sal) FROM emp e2 WHERE e1.deptno=e2.deptno GROUP BY e2.deptno); 84 -- 列出达拉斯加工作的人中,比纽约平均工资高的人 85 SELECT AVG(sal) FROM emp e INNER JOIN dept d ON e.deptno=d.deptno WHERE d.loc='NEW YORK'; 86 87 SELECT * FROM emp e INNER JOIN dept d ON e.deptno=d.deptno WHERE d.loc='DALLAS' 88 AND sal>(SELECT AVG(sal) FROM emp e INNER JOIN dept d ON e.deptno=d.deptno WHERE d.loc='NEW YORK'); 89 -- 方法二 90 SELECT * FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc='DALLAS') 91 AND sal > (SELECT AVG(sal) FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc='NEW YORK')); 92 -- 查询7369员工编号,姓名,经理编号和经理姓名 93 SELECT mgr FROM emp WHERE empno=7369; 94 SELECT ename FROM emp WHERE empno =(SELECT mgr FROM emp WHERE empno=7369); 95 96 SELECT empno,ename,(SELECT mgr FROM emp WHERE empno=7369) AS 经理编号 97 ,(SELECT ename FROM emp WHERE empno =(SELECT mgr FROM emp WHERE empno=7369)) AS 经理姓名 FROM emp WHERE empno=7369; 98 99 SELECT e1.empno,e1.ename,e1.mgr,mgrtable.ename FROM emp e1,emp mgrtable WHERE e1.mgr = mgrtable.empno AND e1.empno=7369; 100 -- 查询出各个部门薪水最高的员工所有信息 101 SELECT * FROM emp WHERE sal=MAX(sal) GROUP BY deptno; 102 103 SELECT * FROM emp e WHERE sal = (SELECT MAX(sal) AS 最高薪水 FROM emp e2 WHERE e.deptno=e2.deptno GROUP BY deptno ); 104 105 -- SELECT * FROM emp e1 WHERE e1.sal = (SELECT MAX(sal) FROM emp e2 WHERE e1.deptno = e2.deptno GROUP BY deptno); 106 107 -- 面试题 108 CREATE TABLE test( 109 NAME CHAR(20), 110 kecheng CHAR(20), 111 fenshu CHAR(20) 112 ); 113 114 INSERT INTO test VALUES 115 ('张三','语文',81), 116 ('张三','数学',75), 117 ('李四','语文',76), 118 ('李四','数学',90), 119 ('王五','语文',81), 120 ('王五','数学',82); 121 122 -- 请用一条Sql语句查处分数大于80的学生 123 SELECT DISTINCT NAME FROM test WHERE fenshu>80;
计算出不同部门不同岗位的最高薪水:
1 select deptno,job,max(sal) as maxsal from emp group by deptno,job;
说明:group by后面可以写多个字段,数据库会分别对这些字段进行分组。
计算除了manager之外的每个工作岗位的最高薪水:
1 select job,max(sal) as maxsal from emp where job <> 'MANAGER' group by job;
说明:先将manager排除,然后进行分组计算。
where后面不能直接使用聚合函数。
正确写法需要使用having来过滤:
1 select job,avg(sal) from emp group by job having avg(sal) > 2000;
注意:能够在where后过滤的数据不要放到having中进行过滤,否则影响SQL询句的执行效率。
where和having区别
- where和having都是为了完成数据的过滤,它们后面都是添加条件;
- where是在 group by之前完成过滤;
- having是在group by之后完成过滤;
select语句总结
一个的SQL语句如下:
1 select 2 xxxx 3 from 4 xxxx 5 where 6 xxxx 7 group by 8 xxxx 9 having 10 xxxx 11 order by 12 xxxx
以上关键字的顺序不能变,严格遵守
以上语句的执行顺序:
- from 将硬盘上的表文件加载到内存
- where:将符合条件的数据筛选出来。生成一张新的临时表
- group by :根据列中的数据种类,将当前临时表划分成若干个新的临时表
- having : 可以过滤掉group by生成的不符合条件的临时表
- select : 对当前临时表进行整列读取
- order by : 对select生成的临时表,进行重新排序,生成新的临时表
- limit : 对最终生成的临时表的数据行,进行截取
使用union合并结果
将查询的结果集合并,合并结果集时查询字段的个数必须一致。
查询出job为MANAGER和SALESMAN的员工:
1 使用union合并结果 2 将查询的结果集合并,合并结果集时查询字段的个数必须一致。 3 4 查询出job为MANAGER和SALESMAN的员工: 5 6 SELECT 7 empno, ename, job 8 FROM 9 emp 10 WHERE 11 job = 'MANAGER' 12 UNION 13 SELECT 14 empno, ename, job 15 FROM 16 emp 17 WHERE 18 job = 'SALESMAN';
找出工资排名在[ 3-9 ]的员工:
1 select ename,sal from emp order by sal desc limit 2,7;
什么是存储引擎
存储引擎是通过采用不同的技术将数据存储在文件或内存中,不同的技术有不同的存储机制,其功能和能力也不同,通过选择不同的技术,可以获得特殊的速度或功能,从而提高应用的性能。存储引擎是MySQL特有的
在不同的业务场景下选择不同的存储引擎,这样能够发挥MySQL的最佳性能。
MySQL存储引擎的分类
使用下面命令可以查看MySQL的存储引擎:
1 show engines;

如上图所示,MySQL中的存储引擎有:
- FEDERATED
- MRG_MYISAM
- MyISAM
- BLACKHOLE
- CSV
- MEMORY
- ARCHIVE
- InnoDB
- PERFORMANCE_SCHEMA
上面是MySQL中的存储引擎,在创建表的时候,可以使用engine指定存储引擎:
1 CREATE TABLE table_name( 2 NO INT 3 )ENGINE = MyISAM;
在创建表时,如果没有指定存储引擎,则使用当前默认的存储引擎。
可以修改表的存储引擎,使用如下命令修改:
1 ALTER TABLE 表名 ENGINE = 存储引擎名称;
查看表使用的存储引擎:
1 show create table emp;
常用的存储引擎
- MyISAM
节省数据库空间,当数据读远大于修改时,可以使用该存储引擎 - InnoDB
支持事务,如果数据修改较多时,可以使用该存储引擎 - MEMORY
存储在内存中,速度快,如果存储非永久性数据时,可以使用该存储引擎
什么是事务
事务的英文是transaction,事务可以保证多个操作原子性,对于数据库来说,事务可以保证批量的DML要么全成功,要么全失败。通常一个事务对应一个完整的业务,例如银行转账。比如银行账户表t_bank:

1001的账户向1002的账户进行转账500元的操作,此时将会执行两条SQL语句:
1 update t_bank set money=500 where account=1001; 2 update t_bank set money=2500 where account=1002;
如果上面的sql语句第一条执行成功了,但是由于某些原因第二条sql语句执行失败了,此时账户1001上的金额变成了500,而账户1002上的金额是2000,这样就不正确了。
为了能够正常的执行业务,上面两条sql语句要么全部执行成功,要么全部执行失败,因为他们是最小的业务单元,不能再进行拆分了。
当第一条sql语句执行结束后,并不会立即修改数据库表中的数据,而是在内存中记录一下,第二条sql语句执行成功后,才会修改数据库表中的数据,如果第二条sql语句执行失败了,则将清空内存中的记录,此时并不会修改数据库表中的数据,要实现这样的功能,就必须使用事务来完成。
事务具有四个特征ACID
- 原子性(Atomicity),事务是最小单元,不可再分;
- 一致性(Consistency),事务要求所有的DML语句操作的时候,必须保证同时成功或同时失败;
- 隔离性(Isolation),一个事务不会影响其他事务的执行;
- 持久性(Durability),在事务完成之后,该事务对数据库所作的更改将持久地保存在数据库中,并不会被回滚;
MySQL事务的提交和回滚
MySQL中默认情况下,事务是自动提交的,当执行一条DML语句时,就开启并且自动提交了事务。可以通过下面的语句查看事务是否是自动提交的:
1 show variables like '%commit%';
如果想要关闭MySQL事务的自动提交,可以使用下面语句手动开启事务:
1 start transaction;
为了方便演示提交和回滚,先初始化一些数据:
1 create table t_bank( 2 account int(10) primary key, 3 money int(15) 4 ); 5 6 insert into t_bank values 7 (1001,1000), 8 (1002,2000);
手动开启事务:
1 start transaction;
执行下面语句:
1 update t_bank set money=500 where account=1001; 2 update t_bank set money=2500 where account=1002;
执行查询操作:
1 select * from t_bank;
数据已改变。

重新开启一个MySQL连接,执行查询操作:
1 select * from t_bank;
因为是新开启的MySQL连接,所以查询结果中money字段的数据并未改变,说明上面的操作还没有修改数据库中的字段值。

回到之前的连接中,输入:
1 rollback;
此时事务将会回滚,清空内存中的记录,不会修改数据库中的字段值。
再次执行查询操作:
1 select * from t_bank;
数据并未改变。
上面输入
rollback;
命令,数据库会执行回滚操作,如果想要提交事务,则输入命令:
1 commit;
事务的隔离级别
- read uncommitted 读未提交
事务A和事务B,事务A未提交的数据,事务B可以读取,这里读取到的数据叫做“脏数据”,该级别最低,一般只是理论上存在,数据库的默认隔离级别都高于该级别。 - read committed 读已提交
事务A和事务B,事务A提交的数据,事务B才可读取到,换句话说:对方事务提交之后的数据,当前事务才可读取到,可以避免读取“脏数据”,但是改级别会有“不可重复读”的问题,事务B读取一条数据,当事务A修改这条数据并提交后,事务B再读取这条数据时,数据发生了变化,即事务B每次读取的数据有可能不一致,这种情况叫做“不可重复读”。 - repeatable read 重复读
MySQL默认的隔离级别是重复读,该级别可以达到“重复读”的效果,但是会有“幻读”的问题,即事务A读取数据,此时事务B修改了这条数据,但是事务A读取的还是之前的旧数据的内容,这样就出现了幻读。 - serializable 串行化
事务A和事务B,事务A在操作数据库表中数据的时候,事务B只能排队等待,这样保证了同一个时间点上只有一个事务操作数据库,该级别可以解决“幻读”的问题。但是这种级别一般很少使用,因为吞吐量太低,用户体验不好。

查看当前会话的隔离级别:
1 select @@tx_isolation;
索引的作用
索引相当于一本字典目录,能够提高数据库的查询效率,表中每一个字段都可添加索引。主键会自动添加索引,在查询时,如果能通过主键查询的尽量使用主键查询,效率高。
MySQL数据库表中的检索方式有两种:
- 全表扫描(效率低)
例如:select * from emp where ename = ‘KING';如果ename字段没有添加索引的话,就会发生全表扫描。 - 通过索引检索
什么情况下适合添加索引
- 该字段数据量庞大;
- 该字段很少的DML操作(由于索引也需要维护,DML操作多的话,也影响检索效率);
- 该字段经常出现在where条件中;
注意:实际开发中会根据项目需求等综合因素来做调整,添加索引并不能保证一定能够提升检索效率,索引添加不当也有可能会导致效率降低。
使用索引
创建索引
语法:
1 create index 索引名 on 表名(列名);
示例:
1 create index dept_dname_index on dept(dname);
查看索引
语法:
1 show index from 表名;
示例:
1 show index from dept;
删除索引
语法:
1 drop index 索引名 on 表名;
示例:
1 drop index dept_dname_index on dept;
视图
视图其实就是一个查询结果,视图的作用可以隐藏表的实现细节。
创建视图
语法:
1 create view 视图名称 as 查询语句;
示例,将emp表中的empno、ename、sal作为视图展示:
1 create view e_info as select empno,ename,sal from emp;
使用视图:
1 select * from e_info;
修改视图
语法:
1 alter view 视图名称 as 查询语句
示例:
1 alter view e_info as select ename,job from emp;
删除视图
语法:
1 drop view if exists 视图名称;
示例:
1 drop view if exists e_info;
数据库的导出和导入
导出命令,在命令提示符下:
1 mysqldump -u root -p monkey1024 > d:/init.sql
上面的monkey1024是要导出的数据库的名称。
导入sql脚本,在命令提示符(管理员权限)下登录成功后,输入下面内容:
1 source d:/init.sql
即source后写上sql文件的目录地址。