- 请求进程,内核缓存区,设备I/O
请求进程无法直接访问设备I/O,而是通过内核缓冲区提交请求数据,等数据就绪后,数据从设备缓冲区提交至进程空间
请求进程把数据提交给内核缓存空间需要等待,内核把数据复制给设备I/O,直到数据就绪,还需要等待,这些等待过程大致可以分为五种模式
- blocking I/O----阻塞式I/O
- NON blocking I/O----非阻塞式I/O
- I/O multiplexing----I/O多路复用
- 信号驱动I/O
- 异步I/O
一个进程要处理两个I/O就必须复用,负责完成不了处理,一个进程处理两个链接,处理多个文件描述符,处理多个请求;一个进程处理一个请求时也得需要I/O多路复用,因为可能涉及本地交互式输入(本地磁盘I/O),
网络交互式输入(网络I/O)
所谓阻塞:任务完成前只能等待
非阻塞:任务完成前,可以接着干别的事情
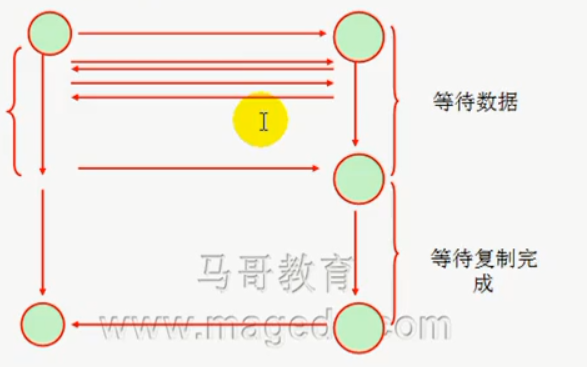
异步非阻塞(上图)数据从设备I/O复制到内核缓存的过程中,请求处于非阻塞状态,不断轮询内核缓存空间数据是否就绪,实际上降低了性能,尚不如同步阻塞I/O

所谓异步同步指的是对结果是否就绪的了解程度-----等待请求直到就绪谓之同步(一直监控并等待请求结果就绪;也称之闲等),不知道何时就绪,不断轮询是否就绪谓之异步(忙等)
- 异步阻塞
从设备I/O复制数据到内核缓存阶段是阻塞的(我们姑且谓之数据准备阶段),从内核缓存复制数据到用户进程空间也是阻塞的(我们姑且谓之数据复制阶段),之所以谓之异步。是因为准备阶段结束后,我们可选
择阻塞等待数据进入复制阶段,或者干脆待会儿再说,先去处理别的请求。
- 事件驱动I/O
在数据准备阶段,数据就绪后,向进程发起通知,获取数据,隔一段通知一次----谓之水平触发。只进行一次通知,谓之边缘触发,显然边缘触发性能更优。这种通知其实是一种回调机制。(回调类似于留了个联系方式)
;本质是一种I/O复用---event driven I/O事件驱动I/O。
数据就绪后,无需切换线程 epoll /dev/poll kqueue 这三种模型专司事件驱动I/O的处理。
这类I/O的工作特点是,一个线程,内部维持多个连接(每个连接可以独立请求),一旦其中某个就绪,会发生阻塞,把数据从内核缓存复制回进程空间。
一种更高效的机制是:设备I/O把数据映射到内核缓存空间,省略了数据复制的工作----这类机制称之为内存映射机制!(MMAP)
- 异步I/O
工作特点:数据准备和数据复制阶段都不阻塞。通过回调机制,当数据完成从内核缓存到进程空间的复制后,通知请求进程,nginx支持磁盘异步I/O(而不是网络I/O,一次典型的请求包含网络I/O和磁盘I/O),真正的
异步实现起来相当复杂,nginx支持了AIO(异步I/O,MMAP,事件驱动
nginx不依赖于一个线程响应一个请求,取而代之的是事件驱动(和异步)的架构,这样一来他处理的并发连接数非常可观。
nginx比起Apache:
Apache
mpm
prefork 一个进程处理一个请求最多1024
worker一个线程响应一个请求,一个进程多个线程,多进程,在linux规范下,其实比起prefork,仅仅是降低了线程切换的开销
event基于事件驱动
Apache的特性是大而全,功能丰富,但基于事件驱动方面性能逊于nginx。
nginx最常见的功能还是反向代理,基于事件驱动的特性(一个线程处理多个请求,一旦挂掉,全都玩儿完),而基于进程的响应则稳定的多,把Apache作为webserver
- 信号I/O
数据复制阶段完成后向进程发起通知
- I/O多路复用
- 一个典型的网站架构

如果是论坛一类的网站,还可以添加文件上传服务器,上传类型只允许文件,例如ftp服务器上传文件,web服务器下载文件
静态文件服务器响应一般很快,动态内容则不然,以一个4G内存,2颗CPU的主机为例,响应1000个左右动态请求,静态每秒响应5000个5-10K大小的图片,这种性能取决于带宽和磁盘I/O;
所以,为了加快响应请求,可以把不曾修改的内容存为缓存,并添加缓存服务器,可以过滤掉一部分请求,缓存没有的,转发到后台服务器。假如有5万个并发访问,处理每个访问用2秒......那么一天下来可处理的请求十分可观(可能达到20亿个)一天=86400秒,当然这只是理论计算,带宽的实际性能才是观念。
尽管如此,后台MYSQL服务器仍旧繁忙。
- 架构中的mysql服务器
通常,针对mysql的请求中,读-写的比例达到5:1到10:1,在不使用连接池的情况下,mysql服务器大概能处理2000个请求,实际上到了1000个左右的请求,性能就开始大幅下降,因为不同于web请求,一个类似于
select * from的操作就会请求大量的数据;如果读的需求很大,尤其是并发访问,导致大量的磁盘I/O,mysql带有缓存机制,但是缓存机制的特点是不断的分配内存,回收内存带来的开销十分浩繁,mysql服务器
既要响应读请求,又要管理缓存,依旧压力山大。所以除了增加mysql读服务器,分担读的请求以外,还应该部署一台主机用于执行负载均衡算法,分担读压力;除此以外,对于热门查询,还可以在应用程序服务器后方
memocache等nosql数据库缓存查询结果
对于php这样的程序语言,在4.0以后会编译成opcode,所以常用命令可以通过xcache缓存到应用程序服务器,memocache不能共享缓存数据,也有一种思路是用PHP的fastcgi实现一个服务器
静态内容----静态服务器
动态-----缓存服务器诸如varnish,varnish通过lvs服务器把请求分摊到应用服务器上
- 架构中对于动态服务的解决方案
假设每个应用服务器可以处理500个请求,那么这个架构理论上最多可以处理2000并发,假设有10000并发请求,且varnish缓存命中率很低,那么可以在负载均衡服务器(LVS)前添加队列服务器,队列服务器可以接收
这10000个请求,并且把其中2000个分发给应用程序服务器,等待空闲时机,在分发剩下的请求,这类队列服务器有些响亮的名字例如 RabbitMq,ZeroMq
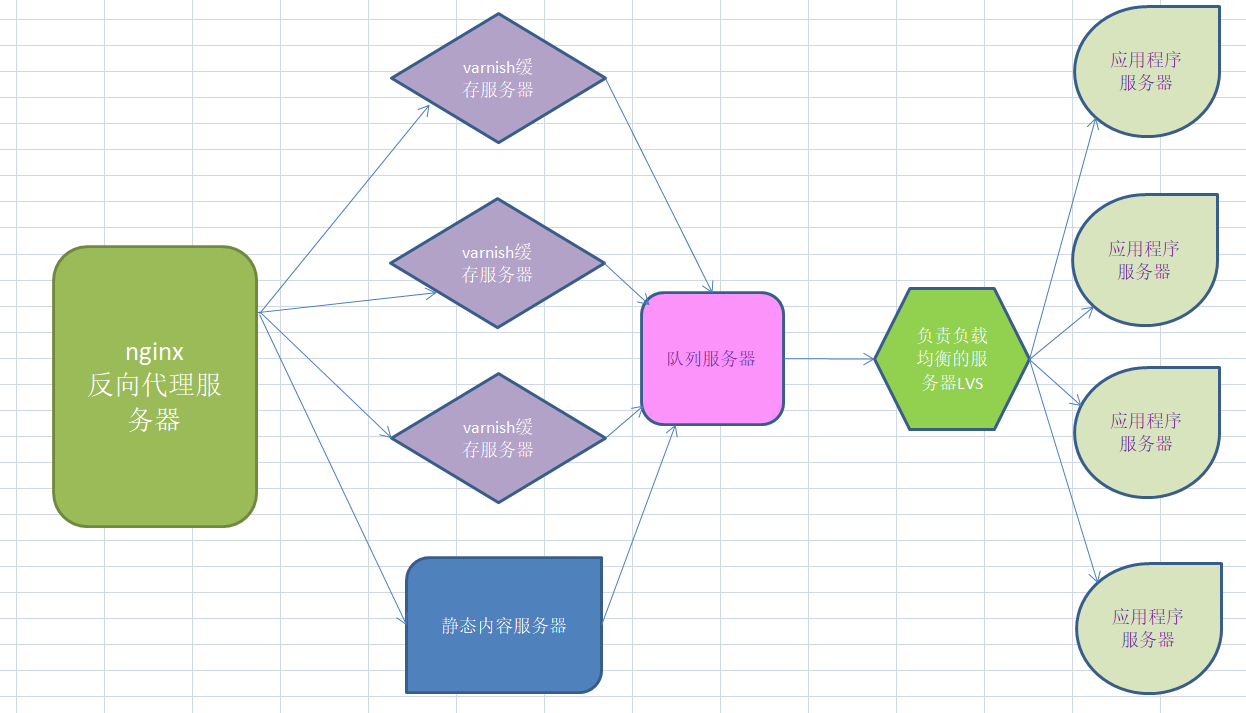
- 架构中对于静态内容的解决方案
以淘宝为例,每天商家上传的图片可能多达几十G,因此数据的膨胀显而易见,对于这些图片的请求也并非易事,例如在几百G的硬盘中去查找一个几十K的图片,解决方案是增加静态文件服务器,并且对请求频繁的数据设
置缓存----也就是用varnish服务器缓存静态文件,然后用LVS服务器负载均衡分摊请求到静态文件服务器
尽管如此,在淘宝抢购的业务场景下,这一体系仍面临考验,所以提高缓存命中率是重中之重,缓存本质就是静态文件,这样我们就可以沿用地理法则,根据用户的地理位置,启用智能DNS解析,在每一个大区(华北,华东,华南,中原,西部......)家门口建立varnish集群,分担访问压力;另外mysql服务器分区方案也要足够完善,据说抢购时mysql每秒处理5万个事务(2013年前后数据),事务其实是一种写操作,显然,单纯依赖mysql已经不行了,因为抢购行为涉及到对库存数量的实时更新,操作都发生在工作在内存的nosql上---这一架构即构成了CDN
redis的计数器在这种场景下,较为常用。既支持快速响应又支持持久化。
- 日志分析
面对这样一个复杂的架构,对用户行为进行分析就用到了日志,不妨把日志存入到一个独立的mysql服务器当中,当然这个服务器的磁盘I/O能力要足够好,,然后定期的把日志数据导出到NFS(文件共享)服务器集群,
运行一个并行程序加以处理,分析,我们就不难得出和web请求相关的数据,例如用户访问量,某种商品的销售情况,不一而足,例如淘宝这样的网站一天产生的数据可能多达上百G,所以就用到了Hadoop并行处理平台,
Hadoop依赖于两部式异步,性能受限于短板(处理耗时较长的那个文件),所以对于实时数据分析并不好,日志这种非结构化数据,最后的归宿是文件系统,并进行全量提取分析(用并行处理平台),实时的读写,就用
nosql
- 对架构本身的总结
这样的架构,导致了主机的增多,把系统直接建立在物理硬件上不一定总是合理的。还有一个方案是把所有的主机进行集群,搭建一个云平台。在上面按照职责建立多个虚拟机,这样利用一些备份机制,即使物理及其出现
问题,也能在最短时间内得到解决
对于建立在物理机上的系统,即使出了问题,也能通过软件手段把文件系统迁移到运行良好的主机上
对于虚拟机,势必用到共享存储,并利用存储监控平台,在虚拟机启动时,分配存储资源(虚拟磁盘)
Hadoop别放在虚拟机上,因为虚拟机的I/O能力无法满足,当然对于一个页面的读取,尽可以放在虚拟机上
云服务:ias pas sas mysql可以作为sas