https://vjudge.net/problem/UVA-1599
题目
找出无向图从起点到终点最短的路,所有路的长度都是1,每条路有一个颜色,多解要求找出字典序最小的解
题解
(20210721注:这是我以前写的垃圾文章,可能有很多错……)
点击查看尝试一次BFS的做法,但是是假的,当时还非常高兴
错误思路:
想起之前做HDU 3567也纠结了两天,还是需要记下
先看有向,如果从1到43,要求路径最短很简单,记录父节点从末尾推路径就可以,但要求字典序最小就有点麻烦
字典序小的条件是开始小,或者开始相等后面小
即:$(a_1, a_2, dots , a_k)$的字典序小于$(b_1, b_2, dots , b_k)$的字典序的条件是:[exists i>0 quad forall 0<j<i, a_j=b_j 且 a_i<b_i]
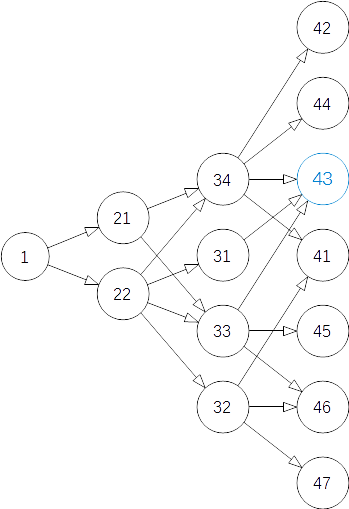
边权都是1,用bfs可以求出最短路,可以把整个图分成几层,肯定不会往回走……
要求字典序最小,需要考虑多个节点都指向一个节点的时候到底选两个中的哪一个
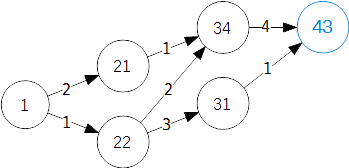
比如都到34,如果选字典序小的(1),那么结果就是2 1,比选(2)的结果1 2的字典序大
都到43,如果选字典序小的,结果是1 3 1,选字典序大的,结果是2 1 4
想下原因发现多个节点都指向一个节点的时候选字典序小的只能保证末尾的选择是最小的,而字典序要求开头最小
因此我们可以倒过来,从43开始bfs
但仍然有个问题……
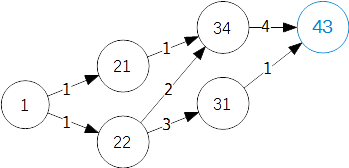
按上面的策略,可能得到的有1 1 4和1 2 4两种,如何排除第二个答案呢
因为前面的相等,只有后面那个字典序小才能使整个路径字典序小
可以在34走的时候优先走字典序小的34->21,等搜索到2x层的时候会先在21搜索,那么1就会和21连接
在22搜索的时候边的字典序相等,那么就不用连接了
如果在1前面添加一些节点,那么这个策略是否还能找出字典序最小的路径呢
可以证明:若$(a_1, a_2, dots , a_k)$的字典序小于$(b_1, b_2, dots , b_k)$的字典序,那么$(c_1,c_2,dots,c_{k'},a_1, a_2, dots , a_k)$的字典序小于$(c_1,c_2,dots,c_{k'},b_1, b_2, dots , b_k)$= =|||
因此继续使用这个策略就好了
即:
1.倒过来走
2.优先走字典序小的
3.多个节点相遇选字典序小的……
(语文不好)
时间复杂度约为$O(n+nlog n)$
题目给的是无向图,那么只需要把每条边看成两条有向边就可以了
AC代码1(140ms)
#include<bits/stdc++.h> using namespace std; #define REP(i,x,y) for(register int i=(x); i<(y); i++) #define REPE(i,x,y) for(register int i=(x); i<=(y); i++) #ifdef sahdsg #define DBG(a,...) printf(a, ##__VA_ARGS__) #else #define DBG(a,...) (void)0 #endifdefine MAXN 100007
typedef pair<int,int> pii;
vector<pii> E[MAXN];
int n,m;
int c[MAXN], dis[MAXN];
int fa[MAXN];
int ans[MAXN], ansi;inline bool cmp(pii &a, pii &b) {
return a.second<b.second;
}void bfs() {
// memset(c,0,sizeof c);
memset(dis,0x3f,sizeof dis);
queue<int> q;
q.push(n);
dis[n]=0;
while(!q.empty()) {
int now = q.front(); q.pop();
REP(ub,0,E[now].size()) {
int i=E[now][ub].first;
int nc=E[now][ub].second;
if(dis[i]>dis[now]+1) {
dis[i]=dis[now]+1;
c[i]=nc; //DBG("%d-%d", i, nc); fa[i]=now; q.push(i); } else if(dis[i]==dis[now]+1) { if(c[i]>nc) { c[i]=nc; fa[i]=now; // DBG("%d-%d", i, nc);
}
}
}
}
ansi=0;
int now = 1;
int cnt=0;
while(now!=n) {
//DBG("```%d-%d ",now, c[now]);
cnt++;
ans[ansi++]=c[now];
now=fa[now];} printf("%d ", cnt); bool fi =false; REP(i,0,ansi) {if(fi)putchar(' ');else fi=true; printf("%d", ans[i]);} putchar(' ');}
int main() {
#ifdef sahdsg
freopen("in.txt","r",stdin);
#endifwhile(~scanf("%d%d", &n, &m)) { REPE(i,1,n) E[i].clear(); while(0<m--) { int a,b,c; scanf("%d%d%d", &a, &b, &c); if(a==b) continue; E[a].push_back(pii(b,c)); E[b].push_back(pii(a,c)); } REPE(i,1,n) sort(E[i].begin(), E[i].end(), cmp); bfs(); } return 0;
}
AC代码2
也可以到节点再排序,可以减少一些不需要的排序(110ms)
紫书上还写了另外一种方法:
从终点bfs求出所有节点到终点的距离,然后从起点bfs选使距离-1的路径,多个路径选字典序最小的
这样选肯定是最短的路,并且符合字典序小的条件= =
复杂度约为$O(n+n)$,比前面两种快,大概是90ms……但编程复杂度较大……
如果再加各种玄学优化大概可以到50ms以下吧……
(20210721)AC代码3,单次BFS
简单的思路就是每次优先扩展路径最短、字典序最小的点,如果都相同就需要保持时间顺序
手动模拟一次两个序列从后往前比较就知道了……
#include<iostream>
#include<queue>
#include<cstring>
#include<vector>
#include<algorithm>
using namespace std;
const int MAXN = 100007;
const int MAXM = 200007;
typedef pair<int,int> pii;
vector<pii> E[MAXN];
struct node {
int wei_zhi;
int yan_se;
int ju_li;
int shi_jian;
bool operator<(const node&r) const {
return !(ju_li<r.ju_li || (ju_li == r.ju_li && yan_se < r.yan_se) || (ju_li == r.ju_li && yan_se == r.yan_se && shi_jian < r.shi_jian));
}
node(){}
node(int wei_zhi, int yan_se, int ju_li, int ti):wei_zhi(wei_zhi), yan_se(yan_se), ju_li(ju_li), shi_jian(ti) {}
};
int dis[MAXN], pcol[MAXN];
int fa[MAXN];
int ans[MAXN], ansn;
int main() {
ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
int n,m;
while(cin >> n >> m) {
int ti=0;
memset(dis+1, 0x3f, sizeof(int)*n);
memset(pcol+1, 0x3f, sizeof(int)*n);
while(0<m--) {
int a, b, c; cin >> a >> b >> c;
E[a].push_back(pii(c,b));
E[b].push_back(pii(c,a));
}
for(int i=1; i<=n; i++) sort(E[i].begin(), E[i].end());
priority_queue<node> q;
q.push(node(n,0,0, ti++)); dis[n]=0;
while(!q.empty()) {
node o = q.top(); q.pop();
for(size_t i=0; i<E[o.wei_zhi].size(); i++) {
int t=E[o.wei_zhi][i].second, tc=E[o.wei_zhi][i].first;
if(dis[o.wei_zhi]+1>dis[t]) continue;
else if(dis[o.wei_zhi]+1==dis[t] && tc>=pcol[t]) continue;
dis[t]=dis[o.wei_zhi]+1;
pcol[t]=tc;
fa[t]=o.wei_zhi;
q.push(node(t, tc, dis[t], ti++));
}
}
int now=1; ansn=0;
while(now!=n) {
ans[ansn++]=pcol[now];
now=fa[now];
}
printf("%d
", ansn);
for(int i=0; i<ansn; i++) {
printf("%d", ans[i]);
if(i+1<ansn) putchar(' ');
}
putchar('
');
for(int i=1; i<=n; i++) E[i].clear();
}
}