一、pom
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<!-- log4j 1.2.17 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
二、回忆hive如何worldcount?
链接:https://www.cnblogs.com/blogyuhan/p/9269057.html
关键:使用explode把文本切成数组,再从数组中count(1)并group by!
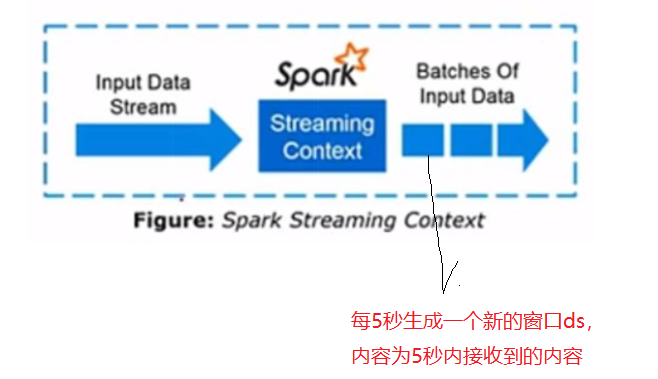
三、使用sparkStreaming统计文本
1-1 使用reduceByKey
1)下载netcat,并打开端口:
yum install nmap-ncat.x86_64 nc -l 1234 # 暴露1234端口给你监控
2)
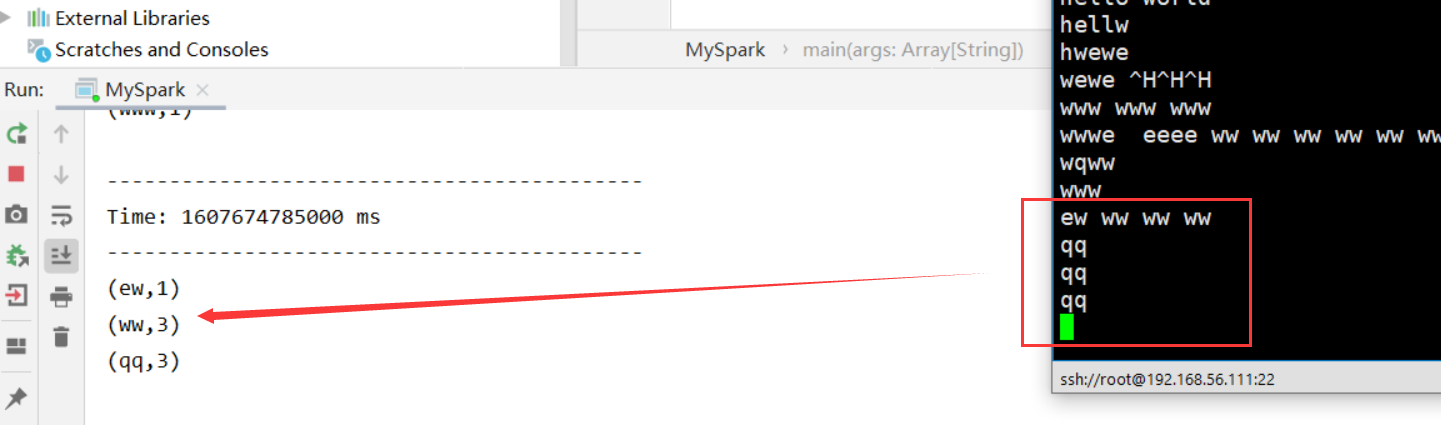
import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} object MySpark { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("app") val sc = SparkContext.getOrCreate(conf) val ssc = new StreamingContext(sc, Seconds(5)) // 窗口,5秒一个 val ds = ssc.socketTextStream("192.168.56.111", 1234) val res = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) res.print() // 启动容器 ssc.start() ssc.awaitTermination() // 永远别停 } }
结果:
2-1 使用 "根据key更新状态",统计类型为Int

import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object MySpark { val updateFunc =(it:Iterator[(String,Seq[Int],Option[Int])])=>{ it.map(x=>{ (x._1,x._2.sum+x._3.getOrElse(0)) }) } def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("app") val sc = SparkContext.getOrCreate(conf) val ssc = new StreamingContext(sc, Seconds(5)) // 窗口,5秒一个 val ds = ssc.socketTextStream("192.168.56.111", 1234) // val res = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) //当使用updateStateByKey这个算子必须设置setCheckpointDir sc.setCheckpointDir("D:/cks") //计算wordcount 累计 val res = ds.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(sc.defaultParallelism), true) res.print() // 启动容器 ssc.start() ssc.awaitTermination() // 永远别停 } }
结果:
(www,9)
(aaa,11) 会进行累加
2-2 统计类型为自定义样例类 map((_,Userinfos(1,"zc",2)))
(_,Userinfos(1,"zc",2))变成(_,Int)
case class Userinfos(userid:Int,username:String,age:Int) object MySpark { val updateFunc: Iterator[(String, Seq[Userinfos], Option[Int])] => Iterator[(String, Int)] = (it:Iterator[(String,Seq[Userinfos],Option[Int])])=>{ it.map(x=>{ (x._1,x._2.map(u=>u.age).sum+x._3.getOrElse(0)) }) }
(_,Userinfos(1,"zc",2)) => (_,Userinfos(1,"zc",sum))
case class Userinfos(userid:Int,username:String,age:Int) object MySpark { val obj = Userinfos(0,"",0) val updateFunc = (it:Iterator[(String,Seq[Userinfos],Option[Userinfos])])=>{ it.map(x=>{ (x._1,Userinfos(1,"xc",x._2.map(u=>u.age).sum+x._3.getOrElse(obj).age)) }) }
2-3 统计类型为(Int,String,Int)
// 把seq元组变成seq(int).sum+...
(x._1,x._2.map(u=>u._3).sum+x._3.getOrElse((1,"",0))._3)
模式匹配 case (x,y是Seq,z是Option)
(x,(y.map(u=>u.3).sum)+z.getOrElse((1,"",0)))._3))