一、上传文件
hdfs dfs -mkdir -p /party/data hdfs dfs -put /opt/data/event_data/*.csv /party/data
二、Data Exploration
【数据探索:数据有没有毛病,保证质量】

开启spark
./spark-shell
1.去头的两种方法
## rdd去头 val rdd = spark.sparkContext.textFile("hdfs://192.168.56.111:9000/party/data/users.csv").cache() val head = rdd.first(); rdd.filter(x=>x!=head).foreach(println(_)) ## df去头 val dfUsers = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/users.csv").cache() dfUsers.show(false)
2.去重user_id
## 去重user_id import org.apache.spark.sql.expressions.Window import spark.implicits._ val wnd = Window.partitionBy("user_id").orderBy(desc("user_id")) dfUsers.select($"user_id",row_number().over(wnd).as("rank")) .filter("rank=1").show(false)
3.birthday是否符合格式
=> 正则匹配过滤null+用均值填充null => 为了保证正态分布
.filter("friends_1 is not null").cache() // 另写作:filter($"friends_1".isNotNull)
方法1:crossJoin(一列) => 自动多加一列
when-otherwise
import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import spark.implicits._ // 1920-2020 val test = udf{ (year:String)=>{ val reg = "(19[2-9][0-9])|(20[0-2][0-9])" year.matches(reg) } } // when-otherwise val df1 = dfUsers.filter(test($"birthyear")).agg(floor(avg($"birthyear")).as("avgyear")) dfUsers.crossJoin(df1).withColumn("birthyear",when(test($"birthyear"),$"birthyear").otherwise($"avgyear")).show()
方法2:利用cast转型时none自动转为null,avg时自动跳过null
val dfUsers = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/users.csv").cache()
import org.apache.spark.sql.types._
import spark.implicits._
// 把birthday转成 数字or null => 过滤null+不实数据,求出avg
val dfuser1 = dfUsers.withColumn("birthyear_",$"birthyear".cast(IntegerType)).filter($"birthyear_".isNotNull && $"birthyear_" > lit(1920))
val dfavg = dfuser1.select(avg("birthyear_").cast(IntegerType).as("avg_year"))
dfavg.show
// 将null 和 不实数据 => 填补成avg数据
val dfFinalUser = dfUsers.withColumn("birthyear",$"birthyear".cast(IntegerType)).crossJoin(dfavg).withColumn("birthyear",when($"birthyear".isNull or $"birthyear" < lit(1920),$"avg_year").otherwise($"birthyear")).drop("avg_year")
dfFinalUser.show
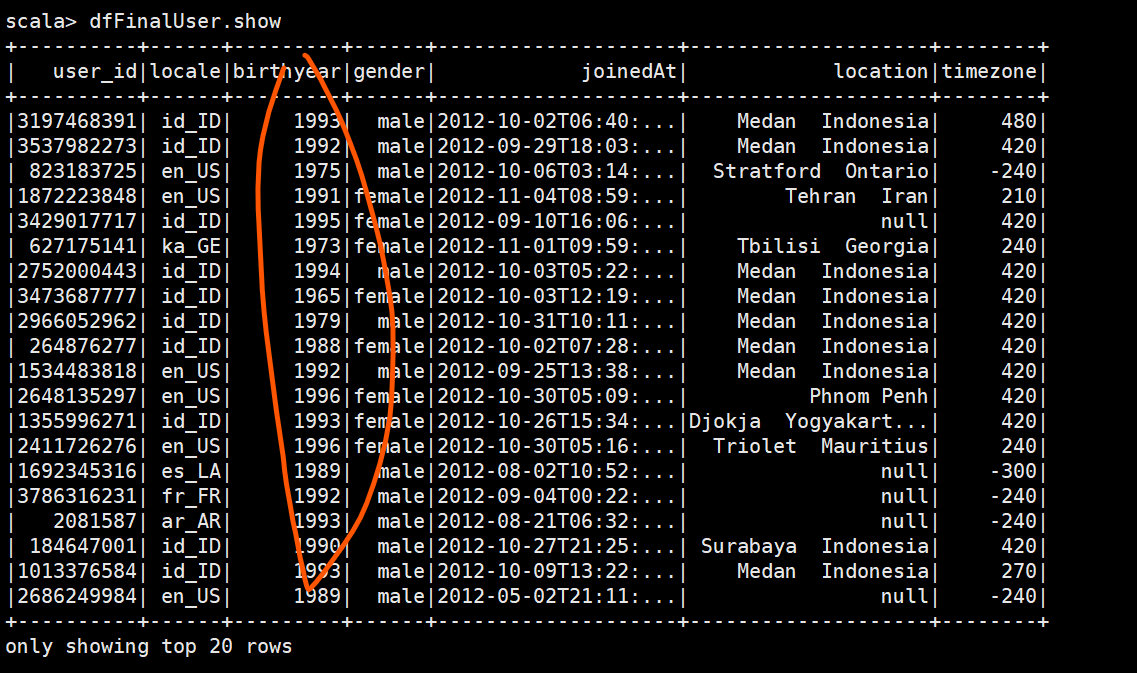
4.gender => 只能 “male/female/unknown”
// 查看有哪些分类 dfUsers.select("gender").distinct.show // (如何查出null值?) 正确: dfUsers.filter("gender is null ").show() 错误:可能是留下""的,不等同于null,所以查不出来 dfUsers.filter("gender!= 'male' and gender!='female' ").show() // 使用when-otherwise转分类 val myuser = dfUsers.withColumn("gender",when($"gender".isNull,"unknown").otherwise($"gender")) // 验证是否改分类成功 myuser.select("gender").distinct.show
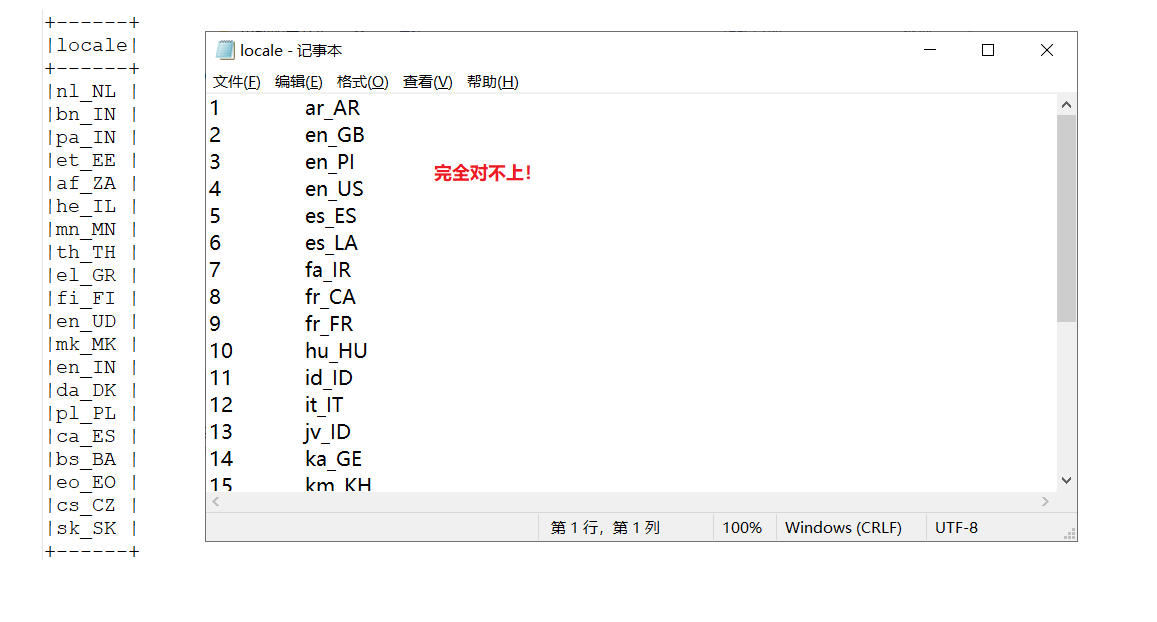
5. 验证locale和文件一一对应
【使用主表(目标表)left join 从表 => 看null值】
外连接查询结果 = 内连接结果+主表中有而从表没有的记录
//方法一:适用于两表列名称相同 val rdd1 = sc.textFile("hdfs://192.168.56.111:9000/party/data/locale.txt") val df1 = rdd1.map(x=>{ val strs = x.split(" ") (strs(0),strs(1)) }).toDF("id","locale") dfUsers .join(df1,Seq("locale"),"left") .filter("id is null") .select($"locale").distinct .show(false) // 方法二:适用于两边列名不一样 val rdd1 = sc.textFile("hdfs://192.168.56.111:9000/party/data/locale.txt") val df1 = rdd1.map(x=>{ val strs = x.split(" ") (strs(0),strs(1)) }).toDF("id","localeName") dfUsers .alias("u").join(df1.alias("f"),$"u.locale" === $"f.localeName","left") .filter("id is null") .select($"locale").distinct .show(false)

6.ETL每个环节都要验证count数目正确
val events = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/events.csv")
events.count
res25: Long = 3137972
7.没有举办方的活动(left join)
filter(“xxx is null ”) 需要先.withColumn("xxx",$"xxx".cast(对应的Type)) => 把None 转化为 null才能判断出来!
(一)是否需要写withColumn("xxx",$"xxx".cast(对应的Type))?
=> 1. 如果需求是distinct count:是否需要值为null的记录数?
如果需要null的记录 => 不需要;(none和null都会变成1个记录)
如果要去除null的记录 => withColumn转成null后用filter过滤null的值(否则无法过滤none的值)
=> 2.如果需求是”null转均值“:需要
注意:转Type的时候要注意是Integer还是Long
(二) 两种left join的区别(结合9的图):
方法1:适用于判断字段相同
方法2:适用于判断字段不同
events.select($"user_id",$"event_id") .join(dfUsers,Seq("user_id"),"left") .filter("user_id is not null and locale is null")
.select($"event_id").distinct.count
8.哪个用户举办的活动最多(分组count)
events.groupBy($"user_id").agg(count("event_id").alias("num")).orderBy($"num".desc).show()
9.多少event中host的user_id 不在users.csv里面(left join) 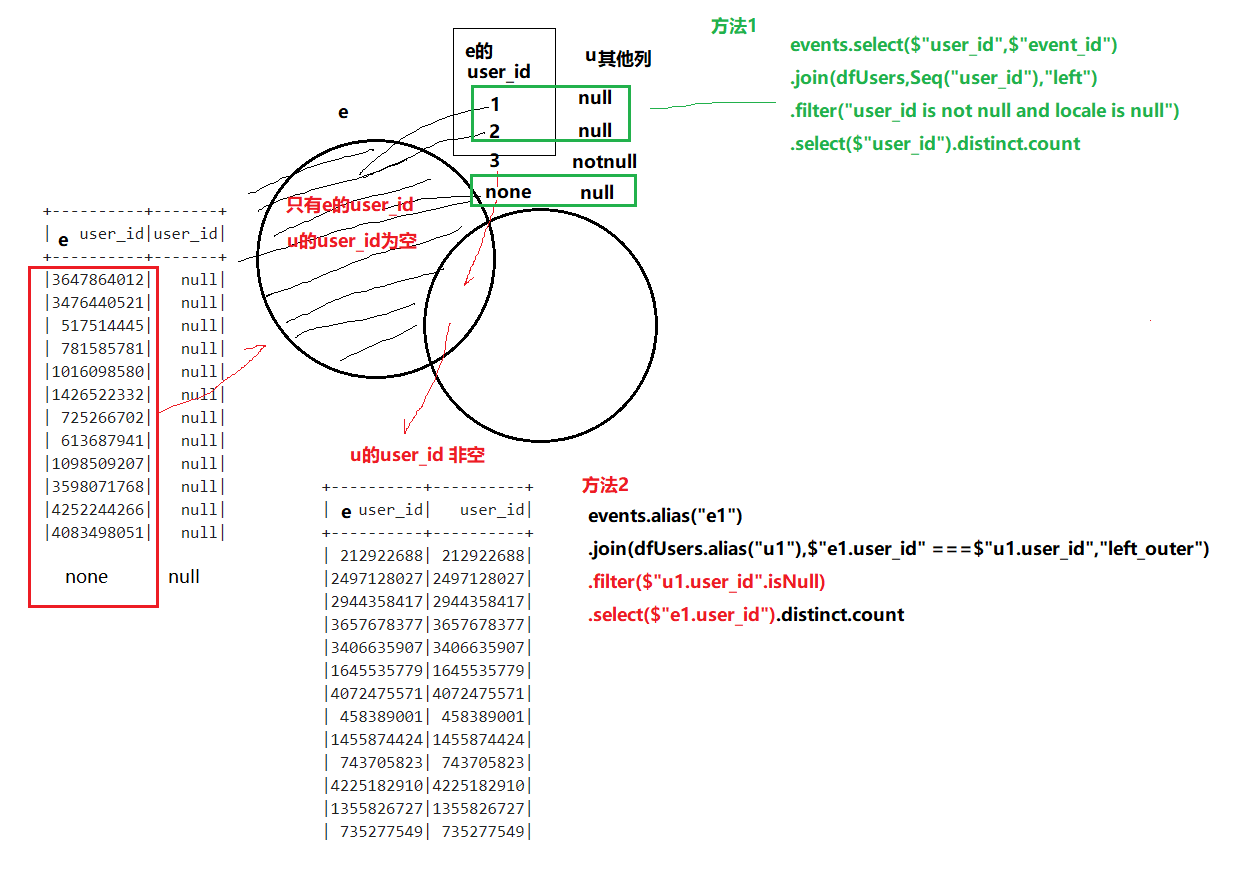
events.alias("e1").join(dfUsers.alias("u1"),$"e1.user_id" === $"u1.user_id","left_outer").filter($"u1.user_id".isNull).select($"e1.user_id").distinct.count
等同于
events.select($"user_id",$"event_id")
//.withColumn("user_id",$"user_id".cast(IntegerType)) 此举有误 .join(dfUsers,Seq("user_id"),"left") .filter("user_id is not null and locale is null") .select($"user_id").distinct.count
关于灰色字段为什么加上去就错,因为
=> 应该是LongType,转成Int失败会转成null

10.把 user 和 friends 的关系表 => 转成一一对应的(行转列lateral view explode)
见:https://www.cnblogs.com/sabertobih/p/13589760.html
11.friend_id 非空的记录数
distinct 会把所有null变成1个
val f1 = friends.select($"user".alias("user_id"),explode(split($"friends"," ")).alias("friends_1")) .filter("friends_1 is not null") f1.distinct.count

12.表结构转换(多个行转列合并)
实现需求如下:
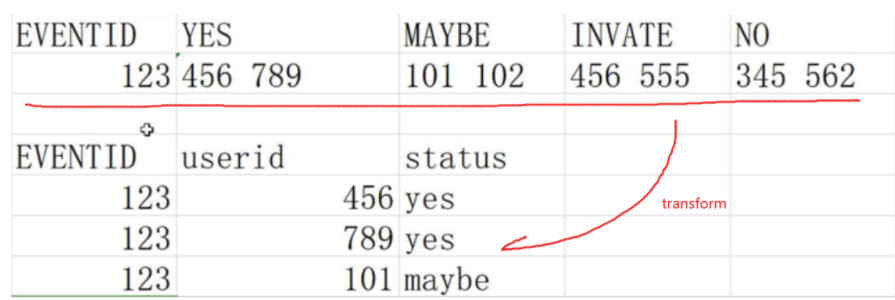
方法1:spark sql
val dfeventAttendees = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/event_attendees.csv").cache() dfeventAttendees.createOrReplaceTempView("eventAttendees") val dfyes = spark.sql(""" select event,userid,"yes" as type from eventAttendees lateral view explode(split(yes,' '))userid as userid """) val dfinvited = spark.sql(""" select event,userid,"invited" as type from eventAttendees lateral view explode(split(invited,' '))userid as userid """) val dfmaybe = spark.sql(""" select event,userid,"maybe" as type from eventAttendees lateral view explode(split(maybe,' '))userid as userid """) val dfno = spark.sql(""" select event,userid,"no" as type from eventAttendees lateral view explode(split(no,' '))userid as userid """) dfyes.union(dfinvited).union(dfmaybe).union(dfno).filter("userid is not null").distinct.count
>>> 11245008
或者直接写在一条大sql中,每一个加distinct 然后 union all 然后整体 where userid is not null
方法2:spark sql API
val yes = df.select($"event_id",explode(split($"yes"," ")).alias("user_id"),lit("yes").alias("status")) // 省略其他 yes.union(dfinvited).union(dfmaybe).union(dfno).filter($"user_id".isNotNull).distinct.count
方法3:rdd
注意用rdd分割csv有 .map(x=>x.split(",",-1)) 操作。具体见:https://i.cnblogs.com/posts/edit;postId=13706382
rdd过滤数组中空字符串: .filter(!_.trim.equals("")
// 先去首行,再map割
val rddpre = sc.textFile("hdfs://192.168.56.111:9000/party/data/event_attendees.csv") val head = rddpre.first() val rdd = rddpre.filter(x=>x!=head)
.map(x=>x.split(",",-1)).cache
val rdd1 = rdd.flatMap(x=>x(1).split(" ").filter(!_.trim.equals("")).map(y=>(x(0),y,"yes")))
val rdd2 = rdd.flatMap(x=>x(2).split(" ").filter(!_.trim.equals("")).map(y=>(x(0),y,"maybe")))
val rdd3 = rdd.flatMap(x=>x(3).split(" ").filter(!_.trim.equals("")).map(y=>(x(0),y,"invited")))
val rdd4 = rdd.flatMap(x=>x(4).split(" ").filter(!_.trim.equals("")).map(y=>(x(0),y,"no")))
rdd1.union(rdd2).union(rdd3).union(rdd4).distinct.count
13.dfeventAttendees中去除event
val dfeventAttendees = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/event_attendees.csv").cache()
val events = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/events.csv")
dfeventAttendees.alias("e1").join(events.alias("e2"),$"e1.event" === $"e2.event_id","left_outer" ).filter($"e2.event_id".isNull).select($"e1.event").distinct.count
>>> 280
14.users和event举办人重叠(user和event交集)
dfUsers.alias("e1").join(events.alias("e2"),$"e1.user_id" === $"e2.user_id","inner" ).select($"e1.user_id").distinct.count
>>> 569

15. 去重5种方法,选取时间戳最大的行
1)distinct
2)groupby方法,但只能显示user+event列
val train = spark.read.format("csv").option("header","true").load("hdfs://192.168.56.111:9000/party/data/train.csv") train.groupBy("user","event").agg(max(unix_timestamp($"timestamp").as("time")).as("ts")).count >>> 15220
* 如何显示其他列?
3)窗口函数
import org.apache.spark.sql.expressions.Window val wnd = Window.partitionBy($"user",$"event").orderBy($"stime".desc)
// 直接用withColumn,不用select无数列 train2.withColumn("rank",row_number().over(wnd)).filter("rank=1").count >>> 15220
4)优化方法【适用面广】
以下以为时间需要转成timestamp才能用max取最大值,其实直接max(时间)也可以
val train2 = train.select($"user",$"event",$"invited",unix_timestamp($"timestamp").alias("stime"),$"interested",$"not_interested") // select写的不好,改成 => val train2 = train.withColumn("stime",unix_timestamp($"timestamp")) train2.createOrReplaceTempView("train2") spark.sql(""" select count(1) from train2 a where exists( select 1 from ( select max(stime) as stime,user,event from train2 group by user,event )b where b.user = a.user and b.event = a.event and a.stime = b.stime ) """).show >>> 15220
5)独有方法dropDuplicates【最方便】
去重(取第一个),并保留其他列
缺点:没办法决定顺序
train.dropDuplicates("user","event").count
>>> 15220
保留最大时间戳,取第一个(取最大时间戳)
repartition : 根据xx重新分区 + sortWithinPartition : 分区内排序
train.repartition($"user",$"event").sortWithinPartitions($"timestamp".desc).dropDuplicates("user","event").count