一、什么是数据归一化
数据标准化(归一化)处理是数据挖掘的一项基础工作。是将数据按比例缩放,使之落入一个小的特定区间[0,1]
二、作用
- 把数变为(0,1)之间的小数
- 数据无量纲化处理,解决数据的可比性:把有量纲表达式变为无量纲表达式(去除数据的单位限制,将其转化为无量纲的纯数值),便于不同单位或量级的指标能够进行比较和加权。
- 数据同趋化处理,解决不同性质的数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果
三、好处
- 提升模型的收敛速度
- 提升模型的精度
四、归一化方法
一、min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
二、Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
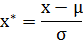
Z-score标准化的sklearn方法:http://blog.csdn.net/u011630575/article/details/79406612