一、项目建立
1.建立maven-quickstart
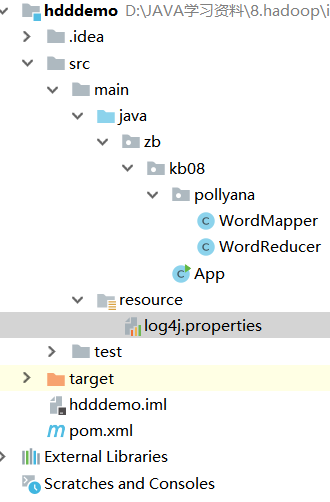
2.目录
3.pom如下:
工具类介绍:
* hadoop commons:第三方连hdfs的工具集,驱动,操纵hdfs标准工具集
* hdfs:对文件inputstream的通用工具集。hdfs是特殊的文件格式,是hadoop的filesystem存储数据方式(NTFS是win为了解决大文件存储=>网络文件存储格式)
hdfs可以容纳任何你想要的格式,而且分布式,随意扩展机器
hive用到,hbase用到(通用)类似io流
* hadoop core:hadoop运行核心
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.6.0-cdh5.14.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
#--------------- 因为maven没提供hadoop仓库,所以手动添加 --------------------------#
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
4.log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/hadoop.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
二、windows环境变量配置
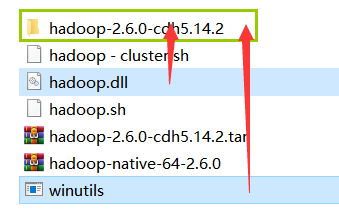
1. 解压:

2. 把winutils和hadoop.dll放进hadoop-2.6的bin目录里!
3.
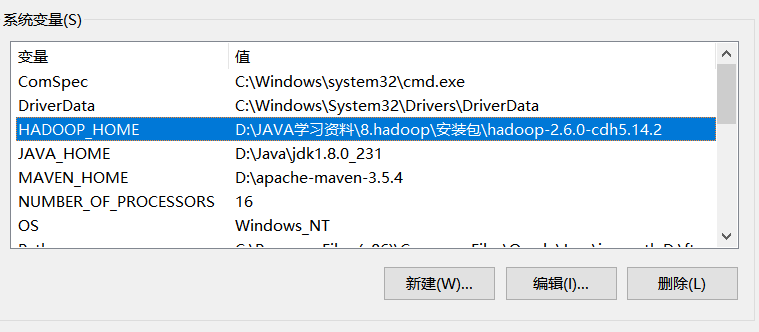
添加系统变量:
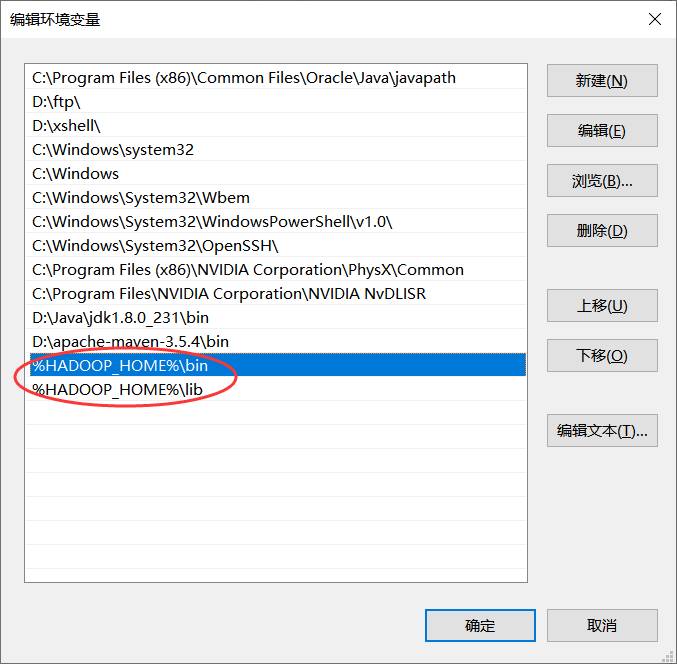
编辑 PATH:
4.配置环境变量后如果已经打开 IDEA,需要重启一下!
三、JAVA代码
1.wordMapper
package zb.kb08.pollyana;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text _key=new Text();
IntWritable _value=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().replaceAll(",|\.|"|\?|!|:|;|\(|\)|-", "").split(" ");
//StringTokenizer tokenizer=StringTokenizer(value.toString().replaceAll("","")," ");
for (String word : words) {
_key.set(word);
context.write(_key,_value);
}
}
}
2.wordReduce
package zb.kb08.pollyana;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
IntWritable value=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
value.set(sum);
context.write(key,value);
}
}
3.AppTest
@Test
public void wordCountPollyanna() throws IOException, ClassNotFoundException, InterruptedException {
final String ip="192.168.56.111",
inputPath="/kb08/data/Pollyanna.txt",outputPath="/tmp/poly"; // outputPath会自动创建
Configuration config=new Configuration();
config.set("fs.defaultFS", MessageFormat.format("hdfs://{0}:9000",ip));
FileSystem fs=FileSystem.get(config);
System.out.println(fs.deleteOnExit(new Path(outputPath)));
//取
Job job=Job.getInstance(config,"pollywordcount");
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//读
FileInputFormat.addInputPath(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
System.out.println(job.waitForCompletion(true));
}
}
四、结果:
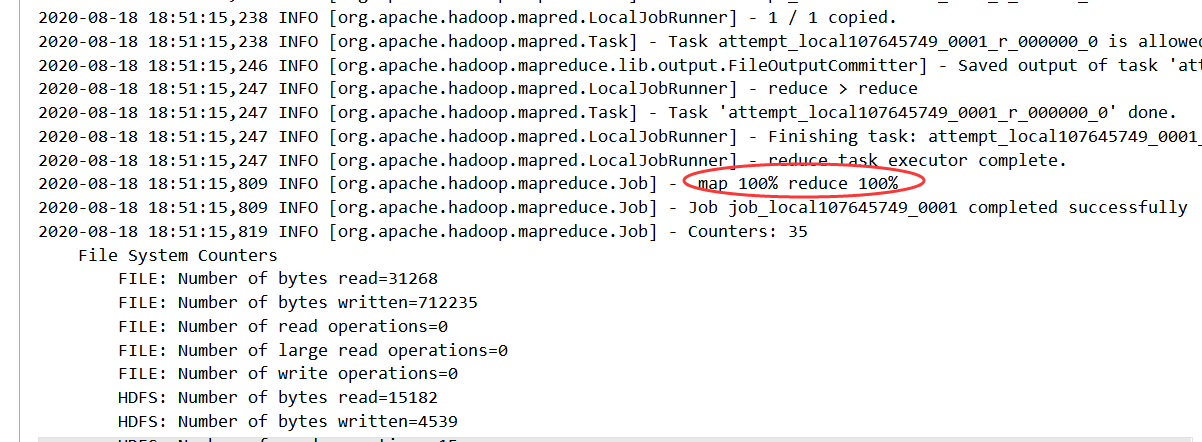
运行成功!
输出文件 /tmp/poly下:part-r-00000
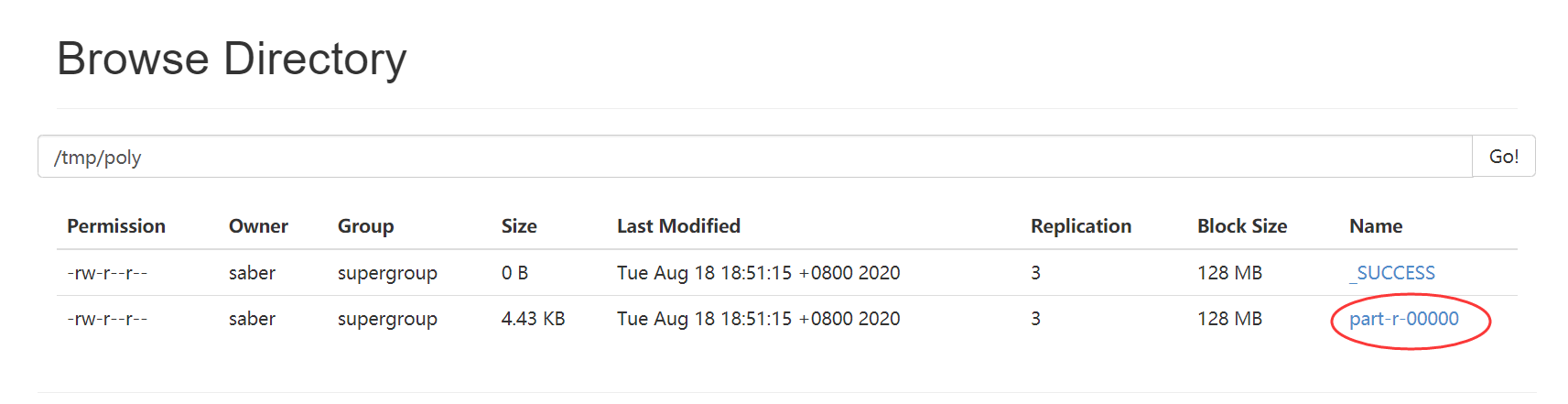
用命令查看结果:
hdfs dfs -cat /tmp/poly/part-r-00000