算法简介:
通过计算待预测样本和已知分类号的训练样本之间的距离来判断该样本属于某个已知分类号的概率。并选取概率最大的分类号来作为待预测样本的分类号
懒惰分类算法,其模型的建立直到待预测实例进行预测时才开始。
KNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
本质上,KNN算法就是用距离来衡量样本之间的相似度
算法图示:
从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别。
算法涉及3个主要因素:
1) 训练数据集
2) 距离或相似度的计算衡量
3) k的大小
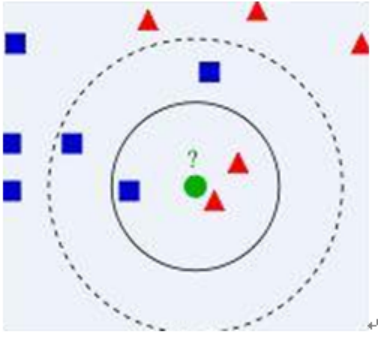
算法描述
1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中
2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类
3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别
算法要点
计算步骤
计算步骤如下:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
相似度的衡量
距离越近应该意味着这两个点属于一个分类的可能性越大。但距离不能代表一切,有些数据的相似度衡量并不适合用距离
相似度衡量方法:空间上有欧氏距离,路径上有曼哈顿距离,国际象棋上的一致范数:切比雪夫距离等,还有夹角余弦等。
(简单应用中,一般使用欧氏距离,但对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适)
类别的判定
简单投票法:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
K值的选取
选定训练集和对应的测试机,然后选取不同的k值,把其中错误率最低的k作为分类的k值,当有新的训练集更新时,我们再运行模型,不断迭代更新。一般来说k是不超过20的整数。k<sqrt(样本数)
一般使用交叉验证的方式
算法不足之处
样本不平衡容易导致结果错误
如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
改善方法:对此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
计算量较大
因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
改善方法:事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
该方法比较适用于样本容量比较大的类域的分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
性能改进:
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
已经有一些方法提高计算的效率,例如压缩训练样本量等,方法有浓缩技术、编辑技术等