5种基础数据结构: string(字符串), list(列表) , set(集合), hash(哈希), zset(有序集合)。
Redis所有的数据结构都是唯一的 key字符串作为名称,然后通过这个唯一key值来获取相应的value数据。
不同类型的数据结构的差异就在于value的结构不一样。
String(字符串)
Redis的字符串是动态字符串,可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式
来减少内存的频繁分配。 需要注意: 字符串最大长度为 512M
键值对

批量键值对
可以批量对多个字符串进行读写,节省网络耗时开销。

过期和 set命令扩展
可以对key 设置过期时间,到点自动删除,这个功能常用来控制缓存的失效时间。
不过这个【自动删除】机制比较复杂,之后会详细探讨。

计数
如果value值是一个整数,还可以对它进行自增操作。自增是有范围的,它的范围是
signed long 的最大最小值,超过了这个值,Redis会报错。

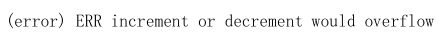
字符串是由多个字节组成,每个字节又是由8个bit组成,如此便可以将一个字符串看成
很多bit的组合,这便是bitmap[位图] 数据结构(后面会详细探讨。)
list(列表)
Redis的列表相当于Java语言里面的 LinkedList,注意它是链表而不是数组。这意味着
list的插入和删除操作非常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n),这点让人非常意外。
当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
Redis的列表结构常用来做异步队列使用。将需要延后的任务结构体序列化成字符串塞进
Redis的列表,另一个线程从这个列表中轮询数据进行处理。 (讲道理,真正会选择MQ处理)
右边进左边出:队列

右边进右边出: 栈

慢操作
lindex相当于Java链表的 get(int index)方法,他需要对链表进行遍历,性能随着参数index
增大而变差。ltrim 和字面上的含义不太一样,个人觉得它叫 lretain(保留) 更适合一些,因为
ltrim 跟的两个参数 start_index 和 end_index 定义了一个区间,在这个区间内的值,ltrim要保留,区间之外
统统砍掉。我们可以通过ltrim来实现一个定长的链表,这一点非常有用。index可以为复数,index=-1表示倒数
第一个元素,同样index=-2表示倒数第二个元素。

快速列表

如果再深入一点,会发现 Redis底层存储的还不是一个简单的linkedlist, 而是称之为快速链表 quicklist的一个结构。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着
一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针
空间太大,会比较浪费空间,而且会加重内存的碎片化。比如 这个列表里存的只是int类型的数据