什么是网页下载器?
一、网页下载器是爬虫的核心组件
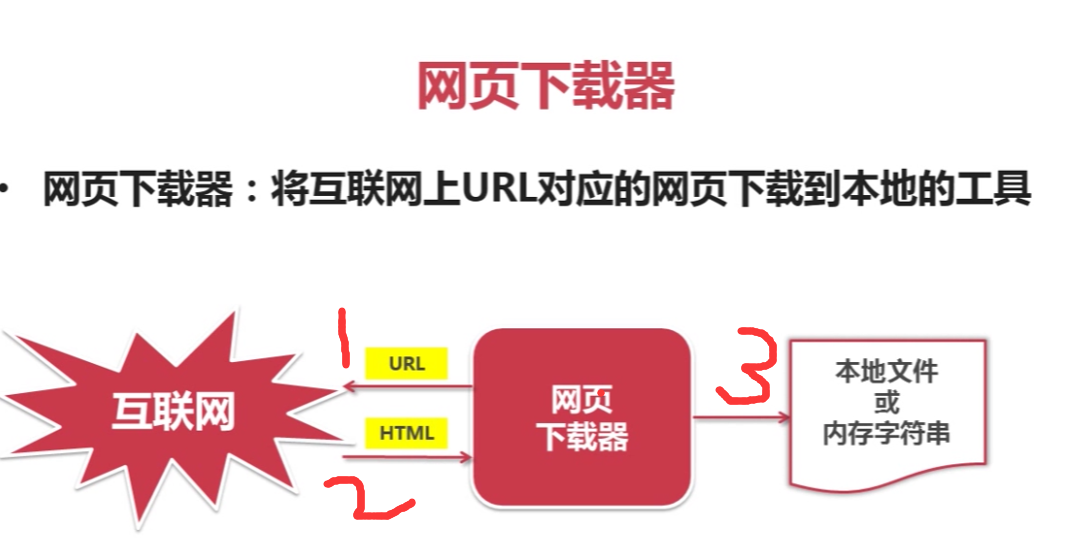
二、常用的python网页下载器有urlilib2基础模块和requests第三方插件两种
urllib2支持功能:1.支持直接url下载;2.支持向网页直接输入的数据;3.支持需要登陆网页的cookie处理;4.需要代理访问的代理处理
三、urllib2的三种下载方法
方法一.直接下载法
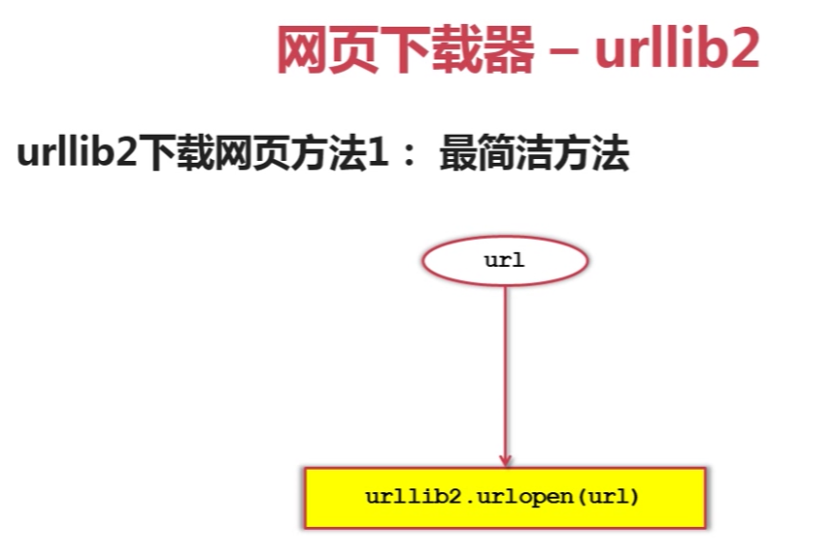
相应代码如下:
#-*-coding:utf-8-*- #调用urllib2模块 import urllib2 #直接请求 response=urllib2.urlopen("http://www.baidu.com") #获取状态码,如果是200表示成功 print response.getcode() #读取爬取得内容 print response.read()
方法2:添加data和http
data:即用户需要输入的数据
http-header:主要是为了提交http的头信息
将url、data、header三个参数传递给urllib2的Request类,生成一个request对象,接着再使用urllib2中的urlopen方法,以request作为参数发送网页请求

相应代码如下:


1 #coding=utf-8 2 import urllib2 3 4 #创建Request对象 5 request= urllib2.Request("所要爬取的url") 6 7 #添加数据a=1 8 request.add_data('a','1') 9 10 #添加http的header 11 request.add_header('User-Agent','Mozilla/5.0') 12 13 #发送请求获取结果 14 response= urllib2.urlopen(request) 15 16 print response.getcode() 17 18 print response.read()
方法三、添加特殊情境的处理器
有些网页需要登录才能访问,需要添加cookie进行处理,这里使用HTTPCookieProcessor
需代理才能访问的使用:ProxyHandler
使用https加密协议的网页:HTTPSHandler
有的url相互自动的跳转关系:HTTPRedirectHandler
将这些handler传送给urllib2的build_opener(handler)方法来创建opener对象,在传送给install_opener(opener),之后urllib2就具有了这些场景的处理能力

代码如下:cookie增强处理
1 #-*-coding:utf-8-*- 2 3 #引入urllib2和cookielib模块 4 import urllib2,cookielib 5 6 #创建cookie容器,来存储cookie的数据 7 cj=cookielib.CookieJar() 8 9 #创建一个opener,然后使用urllib2的HTTPCookieProcessor以cj的cookiejar作为参数生成一个handler,再将此handler传给build_opener方法生成一个opener对象 10 opener = urlib2.build_opener(urllib2.HTTPCookieProcessor(cj)) 11 12 #然后给urllib2安装opener来增强他的处理器 13 urllib2.install_opener(opener) 14 15 #使用带有cookie的urllib2 访问网页,实现网页的爬取 16 response = urllib2.urlopen("http://www.baidu.com")