无论是数组还是链表,其对数据的查询表现都比较无力,要想知道一个元素是否在数组或链表中,只能从前向后挨个对比。出现这个问题的根源在于,没有办法直接根据一个元素找到它存储的位置,而哈希表就是解决查询问题的一种方案。
哈希表与Hash函数
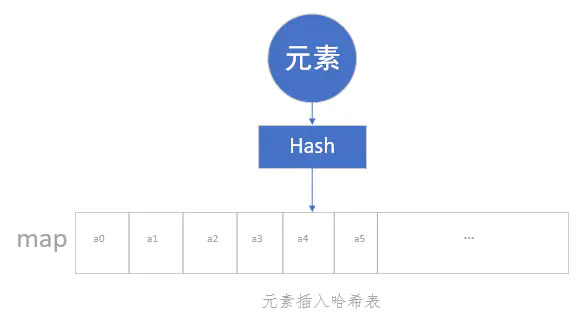
哈希表就是通过关键字来获取数据的一种数据结构,它通过把关键字映射为表中的位置来获取元素,这种映射主要是使用Hash函数。
Hash函数,实际上是建立起key值与int值映射关系的函数。而哈希表,就是一个数组,只是其元素不是按照数组的规则排列的。任何一个元素要放进哈希表中,都必须先通过Hash函数获取到一个int数值,这个数值经过处理后将作为它的存放位置,然后这个元素才能放进哈希表中。
可以发现,数组与哈希表的操作不同之处主要在于,前者是直接插入,后者需要通过Hash函数计算后再插入。

哈希碰撞
Hash函数所做的事,就是无论什么对象,都根据一个规则映射为一个int值。被转换的对象有无数种可能,但是int的值是有限的,它只有232个,这样一来,必然会有不同的对象,映射得到相同的int值,这就是所谓的哈希碰撞。发生碰撞之后,就要把不同的元素插入到相同的位置,这时候单纯的使用一维数组已经无法满足需求了。
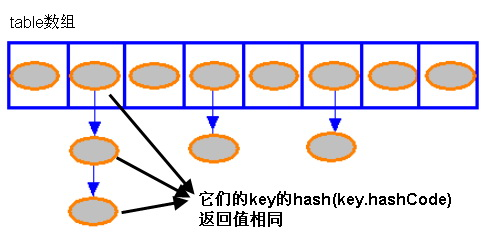
解决哈希碰撞的方法
链表法
将相同hash值的对象组织成一个链表放在hash值对应的槽位(Jdk1.8之前)
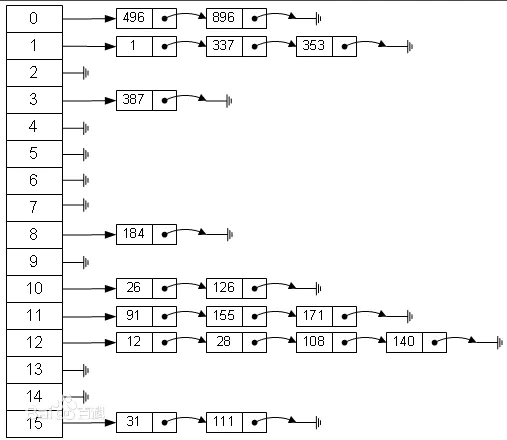
红黑树
当链表长度超过8使用红黑树(Jdk1.8).
哈希表的优缺点
哈希表是一种优化存储的思想,具体存储元素的依然是其他的数据结构。设计良好的哈希表,能同时兼备数组与链表的优点,它能在插入和查找时都具备良好的性能。然后设计不好的哈希表,可能出现较多的哈希碰撞,导致链表过长,从而使得哈希表更像一个链表。还有当数据量很大时,为房子链表过长,就需要对数组进行扩容,这时涉及到了数组的拷贝,其对性能的影响比较严重。