一、NoSQL与Redis
1、什么是NoSQL?
NoSQL=Not Only SQL ,泛指非关系型数据库。随着互联网的兴起,传统的关系型数据库已经暴露了很多问题,NoSQL数据库的产生就是为了解决超大规模数据带来的应用难题。
2、NoSQL有哪些优势
1>. 易扩展
NoSQL数据库种类繁多,但都有一个共同特点就是去掉了关系型数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展能力。
2>.高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库结构简单。一般MySQL使用Query Cache,每次表的更新Cache就失败,是一种大粒度的Cache,性能不高,而NoSQL是记录级的,是一种细粒度的Cache。
3、NoSQL数据库的四大分类
- KV键值 memcache redis
- 文档型数据库 mongoDB
- 列式存储 HBase
- 图关系数据库 Neo4J
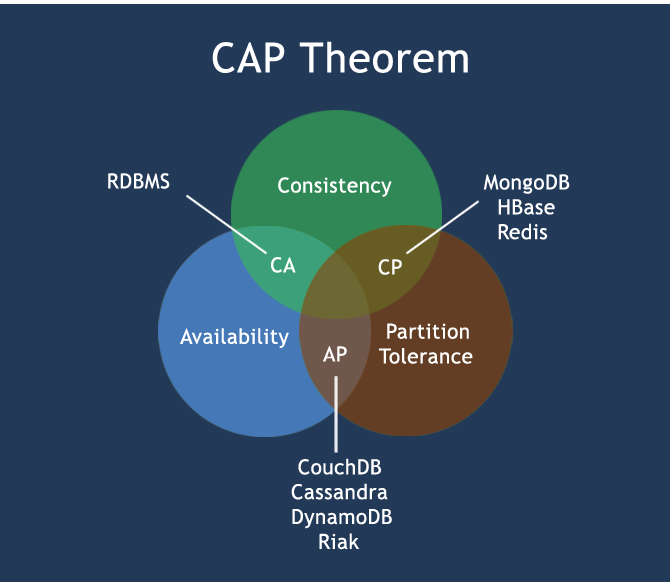
4、分布式存储系统的CAP原则
C:Consistency 强一致性
A:Availability 高可用性
P:Partition tolerance 分区容错性
CAP理论是指在分布式存储系统中,最多只能实现上面两点,而由于当前的网络问题肯定会出现延迟丢包等问题,所以分区容错性是必须要保证的,我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
5、什么是Redis
Redis即 Remote Dictionary Server(远程字典服务器),是一个开源的高性能Key/Value式分布式内存数据库,是当前最热门的NoSQL数据库之一。
Redis支持数据的持久化,可将内存数据保存到磁盘中,重启时可再次加载
Redis不仅仅支持简单的Key-Value类型的数据,同时还支持list,set,zset,hash等数据类型
Redis支持主从模式的数据备份
6、如何安装?
1>下载 wget http://download.redis.io/releases/redis-5.0.3.tar.gz
2>解压 tar zxvf redis-5.0.3.tar.gz
3>make & make install
4>启动 ./redis-server [redis.conf路径]
5>关闭 ./redis-cli shutdown
7、使用前需要了解的基础知识
- 默认16个数据库,下标从零开始,默认使用零号库,select命令切换数据库
- dbsize 查看当前数据库key的数量
- flushdb 清空当前库
- flushall 清空所有库
- 默认端口6379
二、Redis的数据类型
Redis命令参考 http://redisdoc.com/
0、Key(键)

1、String(字符串)
string是redis最基本的类型,一个key对应一个value。string类型是二进制安全的,可以包含任何数据如jpg图片或序列化对象。一个redis字符串的value最大512M
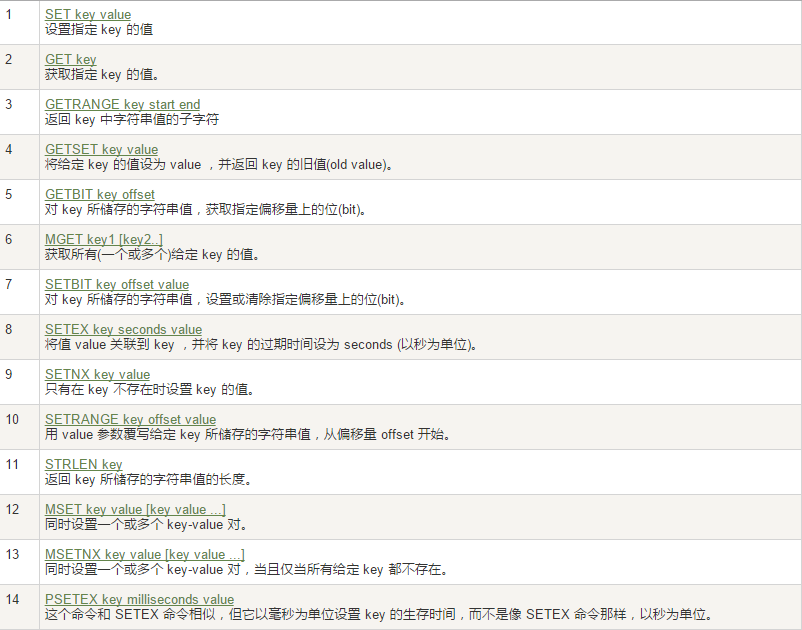
2、List(列表)
list是简单的字符串列表,底层采用链表实现,可以添加一个元素到列表的头部或者尾部。
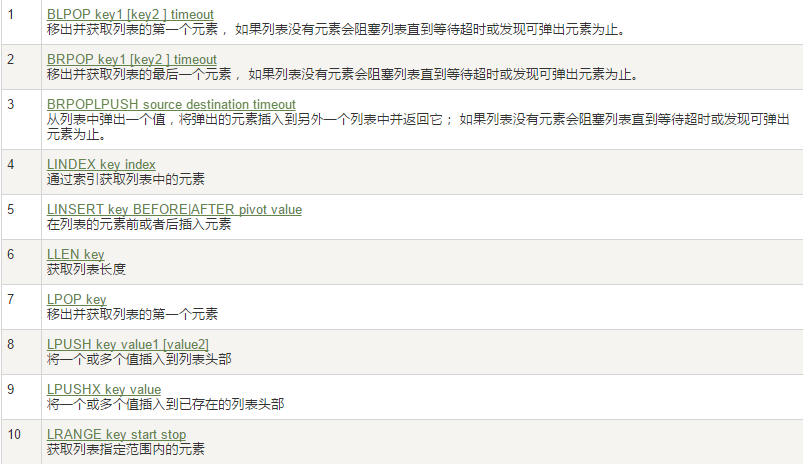
3、Set(集合)
Set是string类型的无序集合,它是通过HashTable来实现的。
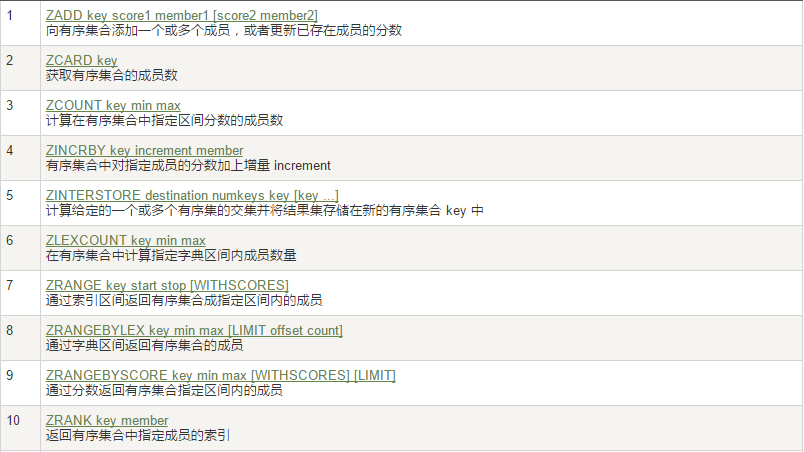
4、Zset(有序集合)
Zset每个元素都会关联一个double类型的分数,通过分数进行从小到大的排序,zset成员是唯一的但是分数可以重复。
5、Hash(哈希)
Hash是一个键值对集合,是一个string类型的filed和value的映射表,hash特别适合存储对象。

三、解析配置文件 redis.conf
1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
3. 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
4. 绑定的主机地址
bind 127.0.0.1
5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
8. 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
11. 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
12. 指定本地数据库存放目录
dir ./
13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
14. 当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
requirepass foobared
16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
19. 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
20. 指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折衷,默认值)
appendfsync everysec
21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
四、Redis的持久化
1.RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘,恢复时直接将快照文件读到内存中。Redis会通过Fork复制一个与当前进程一样的进程。新进程的所有数据都和原进程一样,并作为原进程的子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化的文件。整个过程中主进程是不进行任何IO操作的,这就确保了极高的性能。如果要进行大规模的数据恢复,且对数据恢复的完成性不是很敏感,那RDB方式比AOF方式更加的高效。RDB的缺点就是最后一次持久化后的数据可能丢失。
1>RDB的配置
save <seconds> <changes>
给定时间范围内发生给定次数的写操作将会出发RDB,示例
#save 900 1
#save 300 10
#save 60 10000
stop-writes-on-bgsave-error yes 后台备份出错就停止redis写操作,如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制
rdbcompression yes 对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能
rdbchecksum yes 在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
dbfilename 文件名称
dir 工作目录
2>如何触发RDB
- 配置文件中默认的快照配置
- save/bgsave命令 save时全部阻塞,bgsave通过lastsave命令获取最后一次成功执行快照的时间
- 执行flushall命令 dump文件里面是空的,无意义
RDB的缺点
1.Fork时内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
2.redis意外down机,最后一次备份之后的数据将会丢失
2.AOF
以日志的形式来记录每个操作,读操作不记录,redis启动之初会读取这个文件重新构建数据。
1>AOF的配置
appendonly no aof开关
appendfilename 文件名称
appendfsync
always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
everysec:出厂默认推荐,异步操作,每秒记录 如果一秒内宕机,有数据丢失
no : ...
no-appendfsync-on-rewrite
auto-aof-rewrite-min-size 64m 最小触发的文件大小
auto-aof-rewrite-percentage 100 文件大小翻倍时触发
2>AOF的恢复
redis-check-aof --fix 恢复写坏的AOF
3>Rewrite
AOF文件持续增长超过所设定的阈值时,会fork出一条新进程来将文件重写,只保留可恢复数据的最小指令集,可使用命令bgrewriteaof手动触发。
重写AOF文件的操作,并没有读取旧的AOF,而是和快照相似,将整个内存中的数据库内容用命令的方式重写了一个新的AOF文件。
AOF的缺点
相同数据集的数据而言aof文件要远大于rdb,恢复速度慢于rdb,aof运行效率要慢于rdb
五、Redis的事务
可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入
1.常用命令
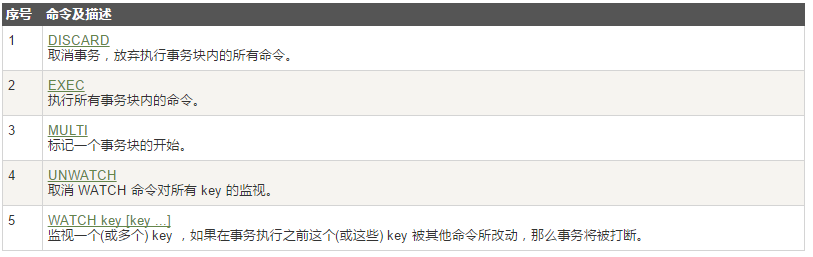
2.使用方式
开启:以MULTI开始一个事务
入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
执行:由EXEC命令触发事务
3.redis事务的特性
单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行
不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
六、Redis的发布订阅
是进程间的一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
可以一次性订阅多个,SUBSCRIBE c1 c2 c3 通配符*, PSUBSCRIBE new*
消息发布,PUBLISH c2 hello-redis

七、Redis主从复制
1.如何配置
从库配置:slaveof 主库IP 主库端口 每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
2.配置方式
1>一主二仆
一个Master两个Slave
2>薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻master的写压力
3.反客为主
1>手动执行 slaveof no one 使当前数据库停止与其他数据库的同步,转成主数据库
2>哨兵模式(sentinel)
配置sentinel.conf sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1
启动哨兵 redis-sentinel sentinel.conf