import threading,time def run(): time.sleep(3)#停3秒 print('哈哈哈') for i in range(5):#串行,1个1个执行,共用时15秒 run() for i in range(5): t=threading.Thread(target=run)#实例化了一个线程;#并发,共用时3秒 t.start()
import threading,time,requests urls={ 'besttest':'http://www.besttest.cn', 'nn':'http://www.nnzhp.cn', 'dsx':'http://www.imdsx.cn', 'cc':'http://www.cc-na.cn', 'alin':'http://www.limlhome.cn/blog/' } def down_html(file_name,url):#定义一个下载函数 res=requests.get(url).content open(file_name+'.html','wb').write(res)#wb代表二进制 #1、串行 # start_time=time.time() # for k,v in urls.items(): # down_html(k,v) # end_time=time.time() # runtime=end_time-start_time # print('下载一共花了%s'%runtime) #1、并行 start_time=time.time() for k,v in urls.items(): t=threading.Thread(target=down_html,args=(k,v))#多线程函数如果传参的知必须得用args t.start() end_time=time.time() runtime=end_time-start_time print('下载一共花了%s'%runtime)
#并行的时候用这个执行时花费时间只有0.01秒,肯定是不对的,这是因为运行的是主线程的时间,而不包括下面5个子线程的时间;
进程里面默认有一个线程,这个线程叫做主线程,主线程的作用是运行代码,下面启动的都是子线程;主线程把5个线程启动,在继续向下执行;
#串行 # start_time=time.time() # for k,v in urls.items(): # t=threading.Thread(target=down_html,args=(k,v))#多线程函数如果传参的知必须得用args # t.start() # t.join()#主线程等待子线程执行结束 # end_time=time.time() # runtime=end_time-start_time # print('下载一共花了%s'%runtime) #等待t.join如果在循环里面等待,又变成串行了 # def run(): # time.sleep(3) # print('哈哈哈') # start_time=time.time() # threads=[] #存放启动的5个线程 # for i in range(5): # t=threading.Thread(target=run) # t.start() # threads.append(t) # for t in threads:#主线程循环等待5个子线程结束 # t.join() # end_time=time.time() # runtime=end_time-start_time # print('下载一共花了%s'%runtime) #1、并行 start_time=time.time() threads = [] # 存放启动的5个线程 for k,v in urls.items(): t=threading.Thread(target=down_html,args=(k,v))#多线程函数如果传参的知必须得用args t.start() threads.append(t) for t in threads: t.join() end_time=time.time() runtime=end_time-start_time print('下载一共花了%s'%runtime)
打印每个线程的用时
def down_html(file_name,url):#定义一个下载函数 start_time=time.time() res=requests.get(url).content open(file_name+'.html','wb').write(res)#wb代表二进制 end_time=time.time() runtime=end_time-start_time print(runtime,url) start_time=time.time() threads = [] # 存放启动的5个线程 for k,v in urls.items(): t=threading.Thread(target=down_html,args=(k,v))#多线程函数如果传参的知必须得用args t.start() threads.append(t) for t in threads: t.join() end_time=time.time() runtime=end_time-start_time print('下载一共花了%s'%runtime)
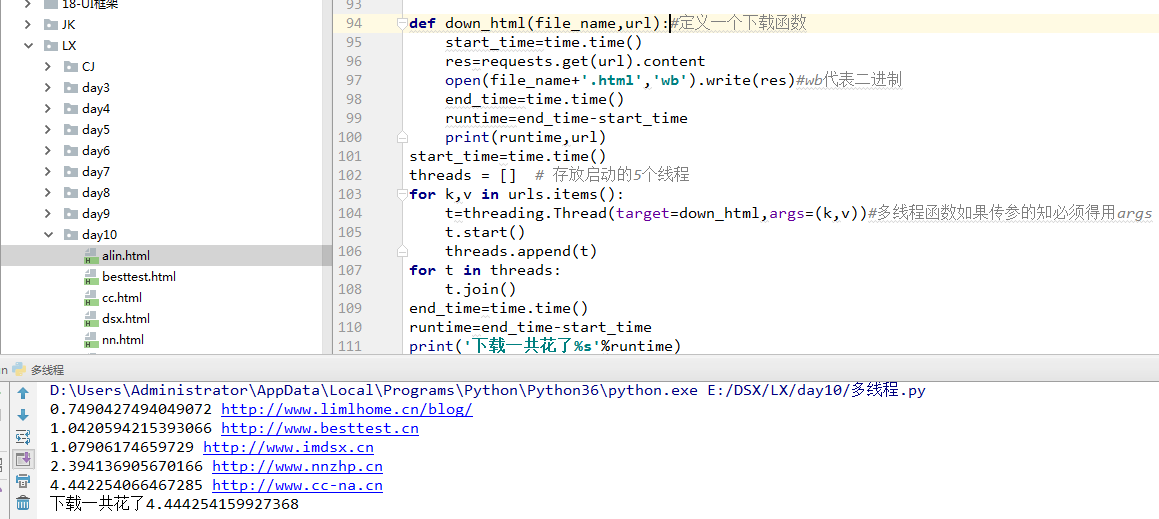
优化
def down_html(file_name,url): start_time=time.time() res=requests.get(url).content open(file_name+'html','wb').write(res) end_time=time.time() run_time=end_time-start_time data[url]=run_time threads=[] start_time=time.time() for k,v in urls.items(): t=threading.Thread(target=down_html,args=(k,v))#多线程函数如果传参的知必须得用args t.start() threads.append(t) for t in threads: t.join() end_time=time.time() runtime=end_time-start_time print(data,'下载一共花了%s'%runtime)

为什么存在串行比并行快的情况:电脑CPU是几核,只能同时运行几个线程;所有的性能测试工具都不是实际意义上的并发,因为CPU处理的速度特别快;我们感觉不到
但是python的多线程只能利用1个CPU的核心;所以很多人说python的多线程不好,很鸡肋;GIL:全局解释器锁;利用多核CPU时,需要把数据放在每一个CPU的核心上,担心分一个CPU处理完的数据和原来的数据不一样;所以就设计了一个全局解释器锁的东西;保证数据不会乱;电脑CPU核数在多,也只能利用1个CPU