http://azkaban.github.io/azkaban/docs/2.5/
There is no reason why MySQL was chosen except that it is a widely used DB. We are looking to implement compatibility with other DB's, although the search requirement on historically running jobs benefits from a relational data store.
【solve the problem of Hadoop job dependencies】
Azkaban was implemented at LinkedIn to solve the problem of Hadoop job dependencies. We had jobs that needed to run in order, from ETL jobs to data analytics products.
Initially a single server solution, with the increased number of Hadoop users over the years, Azkaban has evolved to be a more robust solution.
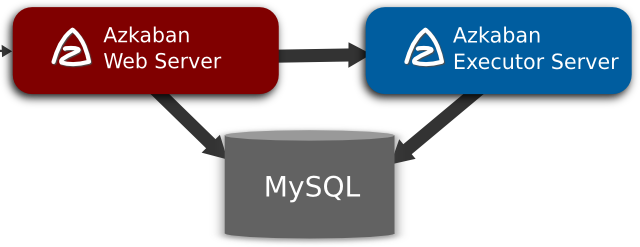
Azkaban consists of 3 key components:
- Relational Database (MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
Relational Database (MySQL)
Azkaban uses MySQL to store much of its state. Both the AzkabanWebServer and the AzkabanExecutorServer access the DB.
How does AzkabanWebServer use the DB?
The web server uses the db for the following reasons:
- Project Management - The projects, the permissions on the projects as well as the uploaded files.
- Executing Flow State - Keep track of executing flows and which Executor is running them.
- Previous Flow/Jobs - Search through previous executions of jobs and flows as well as access their log files.
- Scheduler - Keeps the state of the scheduled jobs.
- SLA - Keeps all the sla rules
How does the AzkabanExecutorServer use the DB?
The executor server uses the db for the following reasons:
- Access the project - Retrieves project files from the db.
- Executing Flows/Jobs - Retrieves and updates data for flows and that are executing
- Logs - Stores the output logs for jobs and flows into the db.
- Interflow dependency - If a flow is running on a different executor, it will take state from the DB.
There is no reason why MySQL was chosen except that it is a widely used DB. We are looking to implement compatibility with other DB's, although the search requirement on historically running jobs benefits from a relational data store.
AzkabanWebServer
The AzkabanWebServer is the main manager to all of Azkaban. It handles project management, authentication, scheduler, and monitoring of executions. It also serves as the web user interface.
Using Azkaban is easy. Azkaban uses *.job key-value property files to define individual tasks in a work flow, and the _dependencies_ property to define the dependency chain of the jobs. These job files and associated code can be archived into a *.zip and uploaded through the web server through the Azkaban UI or through curl.
AzkabanExecutorServer
Previous versions of Azkaban had both the AzkabanWebServer and the AzkabanExecutorServer features in a single server. The Executor has since been separated into its own server. There were several reasons for splitting these services: we will soon be able to scale the number of executions and fall back on operating Executors if one fails. Also, we are able to roll our upgrades of Azkaban with minimal impact on the users. As Azkaban's usage grew, we found that upgrading Azkaban became increasingly more difficult as all times of the day became 'peak'.
【 no cyclical dependencies detected】
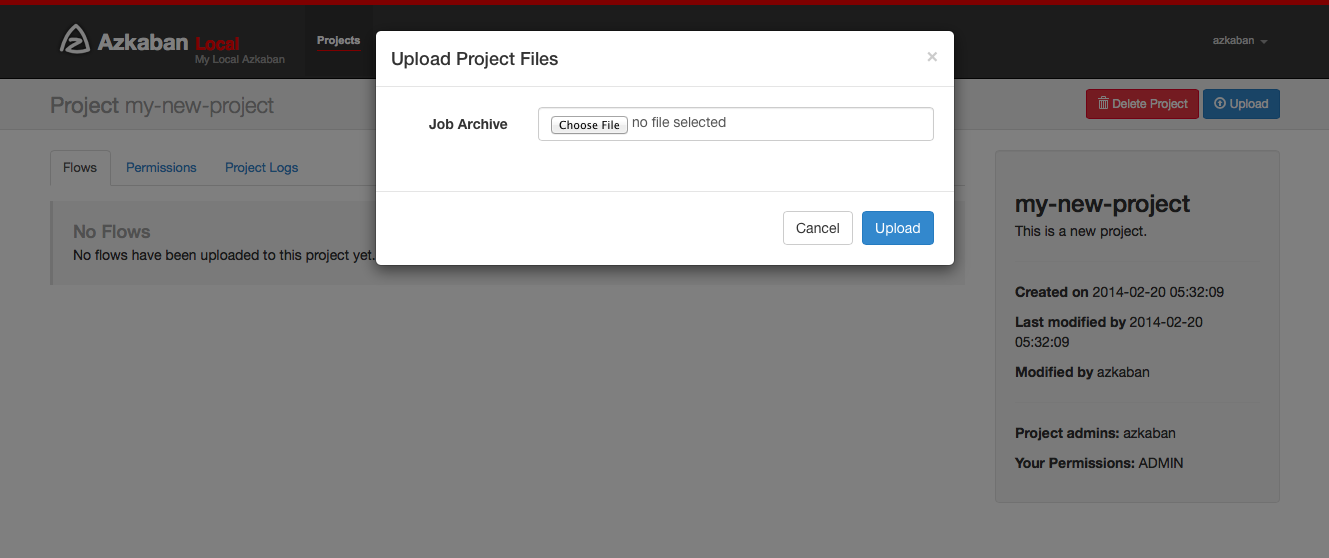
Select the archive file of your workflow files that you want to upload. Currently Azkaban only supports *.zip files. The zip should contain the *.job files and any files needed to run your jobs. Job names must be unique in a project.
Azkaban will validate the contents of the zip to make sure that dependencies are met and that there's no cyclical dependencies detected. If it finds any invalid flows, the upload will fail.
Uploads overwrite all files in the project. Any changes made to jobs will be wiped out after a new zip file is uploaded.
After a successful upload, you should see all of your flows listed on the screen.
http://oozie.apache.org/
Apache Oozie Workflow Scheduler for Hadoop
Overview
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions.
Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availability.
Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).
Oozie is a scalable, reliable and extensible system.