zh.wikipedia.org/wiki/Bagging算法
Bagging算法 (英语:Bootstrap aggregating,引导聚集算法),又称装袋算法,是机器学习领域的一种团体学习算法。最初由Leo Breiman于1994年提出。Bagging算法可与其他分类、回归算法结合,提高其准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生。
给定一个大小为




http://machine-learning.martinsewell.com/ensembles/bagging/
【bootstrap samples 放回抽样 random samples with replacement】
Bagging (Breiman, 1996), a name derived from “bootstrap aggregation”, was the first effective method of ensemble learning and is one of the simplest methods of arching [1]. The meta-algorithm, which is a special case of the model averaging, was originally designed for classification and is usually applied to decision tree models, but it can be used with any type of model for classification or regression. The method uses multiple versions of a training set by using the bootstrap, i.e. sampling with replacement. Each of these data sets is used to train a different model. The outputs of the models are combined by averaging (in case of regression) or voting (in case of classification) to create a single output. Bagging is only effective when using unstable (i.e. a small change in the training set can cause a significant change in the model) nonlinear models.
https://www.packtpub.com/mapt/book/big_data_and_business_intelligence/9781787128576/7/ch07lvl1sec46/bagging--building-an-ensemble-of-classifiers-from-bootstrap-samples

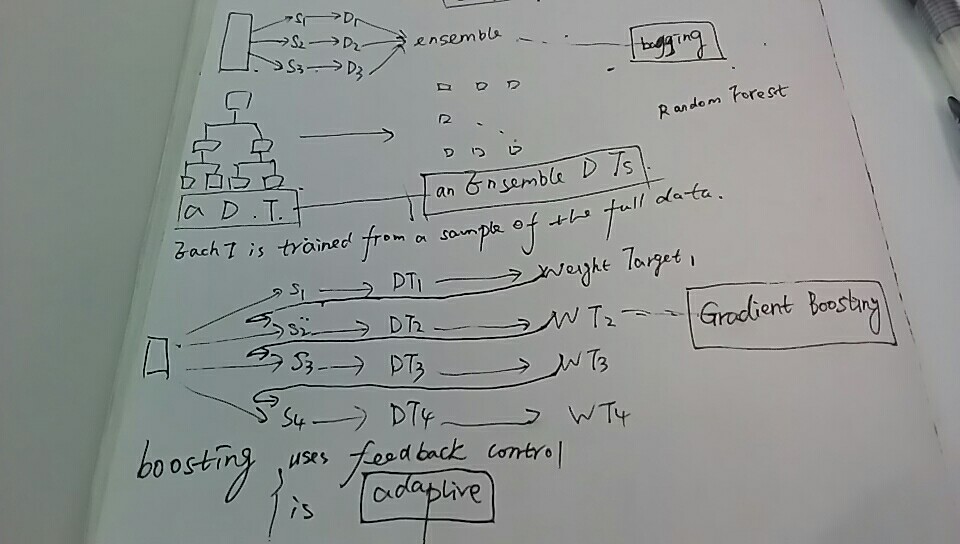
Bagging is an ensemble learning technique that is closely related to the MajorityVoteClassifier that we implemented in the previous section, as illustrated in the following diagram:
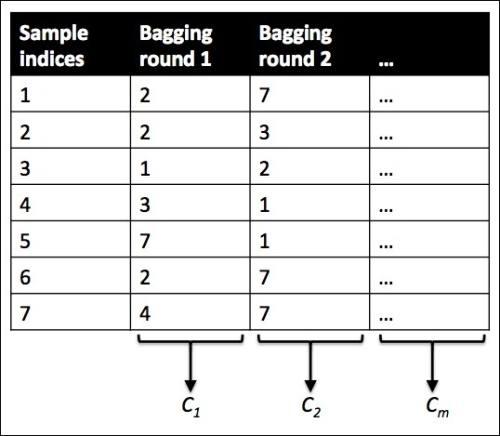
However, instead of using the same training set to fit the individual classifiers in the ensemble, we draw bootstrap samples (random samples with replacement) from the initial training set, which is why bagging is also known as bootstrap aggregating. To provide a more concrete example of how bootstrapping works, let's consider the example shown in the following figure. Here, we have seven different training instances (denoted as indices 1-7) that are sampled randomly with replacement in each round of bagging. Each bootstrap sample is then used to fit a classifier , which is most typically an unpruned decision tree:
, which is most typically an unpruned decision tree:
【LOWESS (locally weighted scatterplot smoothing) 局部散点加权平滑】
LOESS and LOWESS thus build on "classical" methods, such as linear and nonlinear least squares regression. They address situations in which the classical procedures do not perform well or cannot be effectively applied without undue labor. LOESS combines much of the simplicity of linear least squares regression with the flexibility of nonlinear regression. It does this by fitting simple models to localized subsets of the data to build up a function that describes the deterministic part of the variation in the data, point by point. In fact, one of the chief attractions of this method is that the data analyst is not required to specify a global function of any form to fit a model to the data, only to fit segments of the data.
【用局部数据去逐点拟合局部--不用全局函数拟合模型--局部问题局部解决】
http://www.richardafolabi.com/blog/non-technical-introduction-to-random-forest-and-gradient-boosting-in-machine-learning.html



【A collective wisdom of many is likely more accurate than any one. Wisdom of the crowd – Aristotle, 300BC-】
bagging
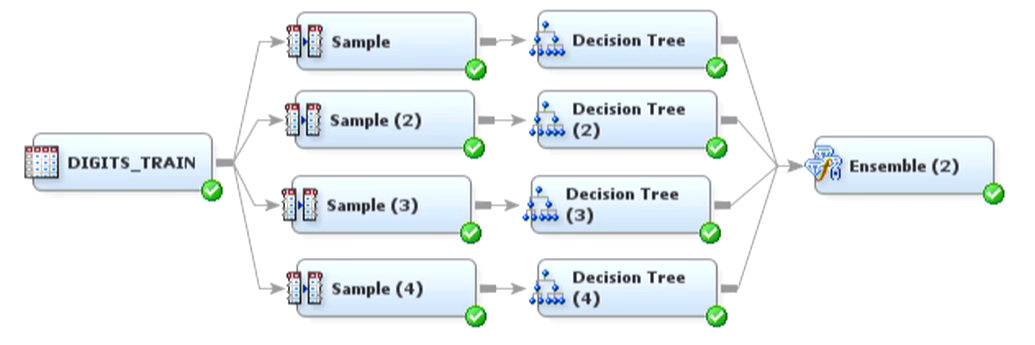
gradient boosting

- Ensemble model are great for producing robust, highly optimized and improved models.
- Random Forest and Gradient Boosting are Ensembled-Based algorithms
- Random Forest uses Bagging technique while Gradient Boosting uses Boosting technique.
- Bagging uses multiple random data sampling for modeling while Boosting uses iterative refinement for modeling.
- Ensemble models are not easy to interpret and they often work like a little back box.
- Multiple algorithms must be minimally used to that the prediction system can be reasonably tractable.