COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION
To provide cache consistency on an SMP, the data cache often supports a protocol
known as MESI. For MESI, the data cache includes two status bits per tag, so that
each line can be in one of four states:
• Modified: The line in the cache has been modified (different from main
memory) and is available only in this cache.
• Exclusive: The line in the cache is the same as that in main memory and is not
present in any other cache.
• Shared: The line in the cache is the same as that in main memory and may be
present in another cache.
• Invalid: The line in the cache does not contain valid data.
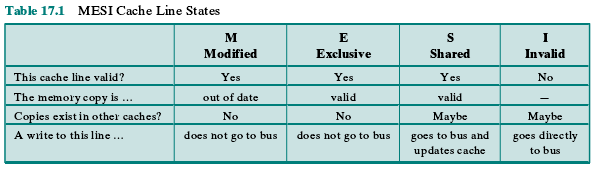
Table 17.1 summarizes the meaning of the four states. Figure 17.6 displays a
state diagram for the MESI protocol. Keep in mind that each line of the cache has
its own state bits and therefore its own realization of the state diagram. Figure 17.6a
shows the transitions that occur due to actions initiated by the processor attached
to this cache. Figure 17.6b shows the transitions that occur due to events that are
snooped on the common bus. This presentation of separate state diagrams for proces-
sor-initiated and bus-initiated actions helps to clarify the logic of the MESI protocol.

At any time a cache line is in a single state. If the next event is from the attached
processor, then the transition is dictated by Figure 17.6a and if the next event is
from the bus, the transition is dictated by Figure 17.6b. Let us look at these transi-
tions in more detail.
READ
MISS When a read miss occurs in the local cache, the processor initiates a
memory read to read the line of main memory containing the missing address. The
processor inserts a signal on the bus that alerts all other processor/cache units to
snoop the transaction. There are a number of possible outcomes:
• If one other cache has a clean (unmodified since read from memory) copy of
the line in the exclusive state, it returns a signal indicating that it shares this
line. The responding processor then transitions the state of its copy from ex-
clusive to shared, and the initiating processor reads the line from main mem-
ory and transitions the line in its cache from invalid to shared.
• If one or more caches have a clean copy of the line in the shared state, each of
them signals that it shares the line. The initiating processor reads the line and
transitions the line in its cache from invalid to shared.
• If one other cache has a modified copy of the line, then that cache blocks the
memory read and provides the line to the requesting cache over the shared
bus. The responding cache then changes its line from modified to shared.
1
The
line sent to the requesting cache is also received and processed by the memory
controller, which stores the block in memory.
• If no other cache has a copy of the line (clean or modified), then no signals are
returned. The initiating processor reads the line and transitions the line in its
cache from invalid to exclusive.
READ
HIT When a read hit occurs on a line currently in the local cache, the
processor simply reads the required item. There is no state change: The state
remains modified, shared, or exclusive.
WRITE
MISS When a write miss occurs in the local cache, the processor initiates a
memory read to read the line of main memory containing the missing address. For
this purpose, the processor issues a signal on the bus that means read-with-intent-
to-modify (RWITM). When the line is loaded, it is immediately marked modified.
With respect to other caches, two possible scenarios precede the loading of the line
of data.
First, some other cache may have a modified copy of this line (state = modify).
In this case, the alerted processor signals the initiating processor that another proc-
essor has a modified copy of the line. The initiating processor surrenders the bus
and waits. The other processor gains access to the bus, writes the modified cache
line back to main memory, and transitions the state of the cache line to invalid
(because the initiating processor is going to modify this line). Subsequently, the
initiating processor will again issue a signal to the bus of RWITM and then read
the line from main memory, modify the line in the cache, and mark the line in the
modified state.
The second scenario is that no other cache has a modified copy of the requested
line. In this case, no signal is returned, and the initiating processor proceeds to read
in the line and modify it. Meanwhile, if one or more caches have a clean copy of the
line in the shared state, each cache invalidates its copy of the line, and if one cache
has a clean copy of the line in the exclusive state, it invalidates its copy of the line.
WRITE
HIT When a write hit occurs on a line currently in the local cache, the effect
depends on the current state of that line in the local cache:
• Shared: Before performing the update, the processor must gain exclusive own-
ership of the line. The processor signals its intent on the bus. Each processor
that has a shared copy of the line in its cache transitions the sector from shared
to invalid. The initiating processor then performs the update and transitions
its copy of the line from shared to modified.
• Exclusive: The processor already has exclusive control of this line, and so it
simply performs the update and transitions its copy of the line from exclusive
to modified.
• Modified: The processor already has exclusive control of this line and has the
line marked as modified, and so it simply performs the update.
L1-L2
CACHE
CONSISTENCY We have so far described cache coherency protocols
in terms of the cooperate activity among caches connected to the same bus or
other SMP interconnection facility. Typically, these caches are L2 caches, and each
processor also has an L1 cache that does not connect directly to the bus and that
therefore cannot engage in a snoopy protocol. Thus, some scheme is needed to
maintain data integrity across both levels of cache and across all caches in the SMP
configuration.
The strategy is to extend the MESI protocol (or any cache coherence proto-
col) to the L1 caches. Thus, each line in the L1 cache includes bits to indicate the
state. In essence, the objective is the following: for any line that is present in both an
L2 cache and its corresponding L1 cache, the L1 line state should track the state of
the L2 line. A simple means of doing this is to adopt the write-through policy in the
L1 cache; in this case the write through is to the L2 cache and not to the memory.
The L1 write-through policy forces any modification to an L1 line out to the L2
cache and therefore makes it visible to other L2 caches. The use of the L1 write-
through policy requires that the L1 content must be a subset of the L2 content. This
in turn suggests that the associativity of the L2 cache should be equal to or greater
than that of the L1 associativity. The L1 write-through policy is used in the IBM
S/390 SMP.
If the L1 cache has a write-back policy, the relationship between the two caches
is more complex. There are several approaches to maintaining coherence. For
example, the approach used on the Pentium II is described in detail in [SHAN05].