哪些值可以被取地址,哪些值不可以被取地址?
Go问答101 - Go语言101(通俗版Go白皮书) https://gfw.go101.org/article/unofficial-faq.html#unaddressable-values
cannot take the address of C
package main
import "fmt"
func main() {
var B bool
B=true
fmt.Println(&B)
const C=3
fmt.Println(&C)
fmt.Println(34)
}
左值和右值
C++中左值和右值的理解 - 知乎 https://zhuanlan.zhihu.com/p/240833006
程序的数据段、代码段、堆栈段、BSS段
左值和右值的概念
C++中左值(lvalue)和右值(rvalue)是比较基础的概念,虽然平常几乎用不到,但C++11之后变得十分重要,它是理解 move/forward 等新语义的基础。
左值与右值这两个概念是从 C 中传承而来的,左值指既能够出现在等号左边,也能出现在等号右边的变量;右值则是只能出现在等号右边的变量。
int a; // a 为左值
a = 3; // 3 为右值
- 左值是可寻址的变量,有持久性;
- 右值一般是不可寻址的常量,或在表达式求值过程中创建的无名临时对象,短暂性的。
左值和右值主要的区别之一是左值可以被修改,而右值不能。
C++左值和右值(详解版) http://c.biancheng.net/view/1510.html
前面讲过,引用是一个变量,它引用其他变量的内存位置。例如,来看以下代码:
int x = 34;
int &lRef = x;
在该代码中,标识符 IRef 就是一个引用。在声明中,引用是通过 & 符号来指示的,它出现在类型与变量的标识符之间,这种类型的引用称为左值引用。
可以将左值看作是一个关联了名称的内存位置,允许程序的其他部分来访问它。在这里,我们将 "名称" 解释为任何可用于访问内存位置的表达式。所以,如果 arr 是一个数组,那么 arr[1] 和 *(arr+1) 都将被视为相同内存位置的“名称”。
相对而言,右值则是一个临时值,它不能被程序的其他部分访问。为了说明这些概念,请看以下程序段:
- int square(int a)
- {
- return a * a;
- }
- int main()
- {
- int x = 0; // 1
- x = 12; // 2
- cout << x << endl; // 3
- x = square(5); // 4
- cout << x << endl; // 5
- return 0;
- }
在该程序中,x 是一个左值,这是因为 x 代表一个内存位置,它可以被程序的其他部分访问,例如上面注释的第 2、3、4 和 5 行。
而表达式 square(5) 却是一个右值,因为它代表了一个由编译器创建的临时内存位置,以保存由函数返回的值。该内存位置仅被访问一次,也就是在第 4 行赋值语句的右侧。在此之后,它就会立即被删除,再也不能被访问了。
对于包含右值的内存位置来说,其本质就是:它虽然没有名称,但是可以从程序的其他部分访问到它。
C++11 引入了右值引用的概念,以表示一个本应没有名称的临时对象。右值引用的声明与左值引用类似,但是它使用的是 2 个 & 符号(&&),以下代码使用了右值引用打印了两次 5 的平方:
- int && rRef = square(5);
- cout << rRef << endl;
- cout << rRef << endl;
有意思的是,声明一个右值引用,给一个临时内存位置分配一个名称,这使得程序的其他部分访问该内存位置成为了可能,并且可以将这个临时位置变成一个左值。
右值引用不能约束到左值上,所以,以下代码将无法编译:
int x = 0;
int && rRefX = x;
再来看以下初始化语句:
int && rRef1 = square(5);
在初始化完成之后,这个包含值 square(5) 的内存位置有了一个名称,即 rRef1,所以 rRef1 本身变成了一个左值。这意味着后面的这个初始化语句将不会编译:
int && rRef2 = rRef1;
究其原因,就是右侧的 rRef1 不再是一个右值。综上所述,临时对象最多可以有一个左值引用指向它。如果函数有一个临时对象的左值引用,则可以确认,程序的其他部分都不能访问相同的对象。
1 代码区
存放 CPU 执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。另外,代码区还规划了局部变量的相关信息。
总结:你所写的所有代码都会放入到代码区中,代码区的特点是共享和只读。
2 全局区
全局区中主要存放的数据有:全局变量、静态变量、常量(如字符串常量)
全局区的叫法有很多:全局区、静态区、数据区、全局静态区、静态全局区
这部分可以细分为data区和bss区
2.1 data区
data区里主要存放的是已经初始化的全局变量、静态变量和常量
2.2 bss区
bss区主要存放的是未初始化的全局变量、静态变量,这些未初始化的数据在程序执行前会自动被系统初始化为0或者NULL
2.3 常量区
常量区是全局区中划分的一个小区域,里面存放的是常量,如const修饰的全局变量、字符串常量等
在VS下运行结果如下:


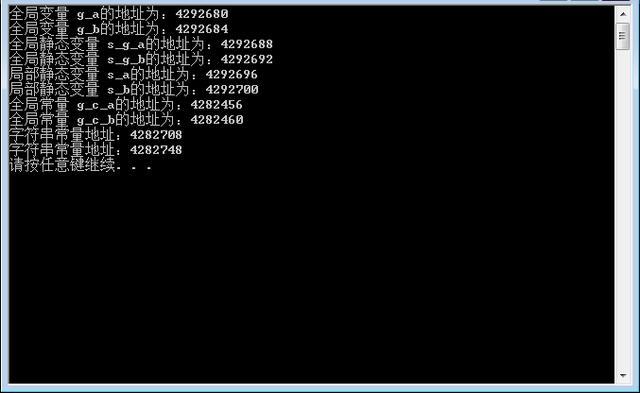
总结:全局区存放的是全局变量、静态变量和常量
在程序运行后由产生了两个区域,栈区和堆区
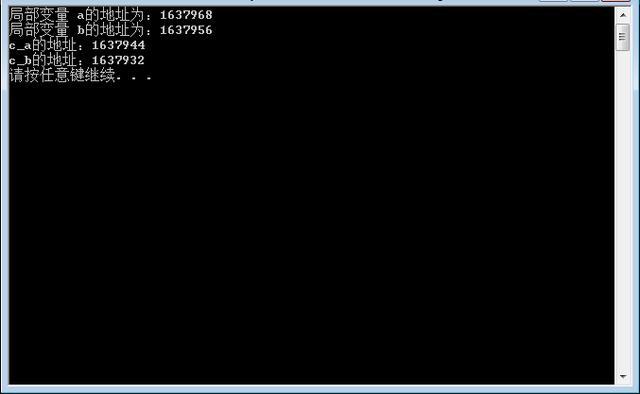
3 栈区(stack)
栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
vs运行效果如下

4 堆区(heap)
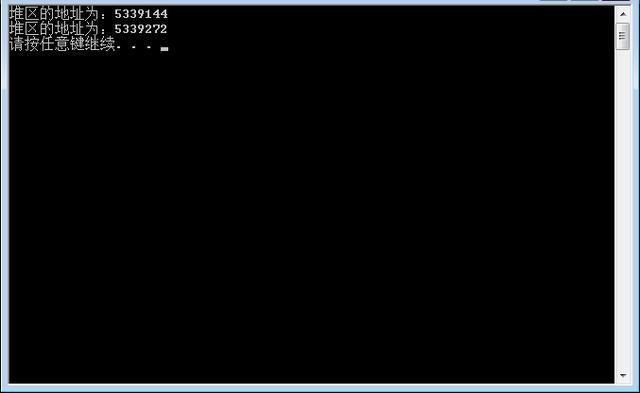
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
vs运行效果如下:

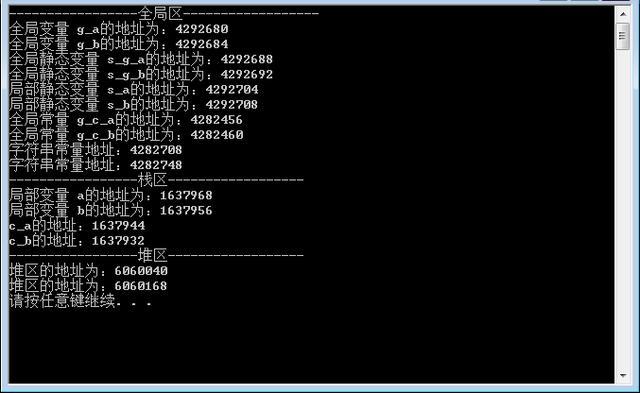
当我们把几个案例放在一起执行,就可以看到内存将每个区域划分的很有条理。每个区域互不干涉,区域中的数据地址也是非常接近的
取地址运算符“&”为什么不能施加在常量和表达式上面? - 知乎 https://www.zhihu.com/question/354485036