相信有很多人收这个问题的困扰,如果你想一次性在pandas.DataFrame里添加几列,或者在指定的位置添加一列,都会很苦恼找不到简便的方法;可以用到的函数有df.reindex, pd.concat
我们来看一个例子:
df 是一个DataFrame, 如果你只想在df的后面添加一列,可以用下面的方法:

但是如果你想一次性添加两列级以上,你可能会用通样的办法
df[['D','E']] == None ,结果报错如下:

所以接下来我想介绍两种认为比较简便的方法
(1)第一个方法是利用pd.concat 在DataFrame后面添加两列,这种方法的缺点是不能指定位置
pd.concat([df, pd.DataFrame(columns=list('DE'))])

(2)第二种方法是利用 reindex来重排和增加列名df.reindex(columns=list('ABCDE'))
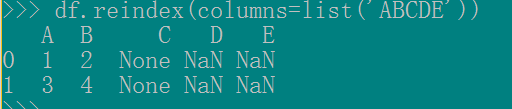
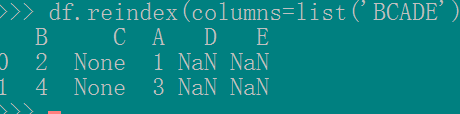
这种方法,你可以改变各列的相对位置,且保留原始列的数值,比如df.reindex(columns=list('BCADE'))
reindex 还有 fill_value 选项,可以填充NaN,例子如下df.reindex(columns=list('ABCDE'), fill_value=0)
当然这里举的例子比较简单,在实际运用中,列名可能都比较长,都敲出来肯定不方便,所以我们需要更强大的方法,运用到 list.insert的方法list.insert(index, obj)
参数
index -- 对象obj需要插入的索引位置。
obj -- 要插入列表中的对象。
先获取原列名集合, 赋值给新变量(这个很重要,具体原因我也不知道为啥), 然后 insert
col_name = df.columns.tolist() col_name.insert(1,'D') df.reindex(columns=col_name) Out[92]: A D B C 01 NaNNoneNone 13 NaNNoneNone 或者不用数字索引,直接在某列前面或后面插入,利用 list.index的方法 col_name = df.columns.tolist() col_name.insert(col_name.index('B'),'D')# 在 B 列前面插入 df.reindex(columns=col_name) Out[93]: A D B C 01 NaNNoneNone 13 NaNNoneNone col_name = df.columns.tolist() col_name.insert(col_name.index('B')+1,'D') # 在 B 列后面插入 df.reindex(columns=col_name) Out[96]: A B D C 01None NaNNone 13None NaNNone
转自:http://www.th7.cn/Program/Python/201708/1216328.shtml