机器学习入门介绍
学习并整理从 Machine learning basics
机器学习是一种数据科学技术,它允许计算机使用现有的数据来预测未来的行为、结果和趋势。使用机器学习,不需要为计算机显式编程而让它自己学习。
机器学习的预测可以使应用程序和设备更加智能化。当你网上购物时,机器学习会帮你根据所购买的产品推荐你可能喜欢的其他产品。当您的信用卡被刷卡时,机器学习将交易与交易数据库进行比较,并帮助检测欺诈行为。当你的真空吸尘器机器人清洁房间时,机器学习有助于它决定是否完成了工作。
- 介绍1 :数据科学可以解答的5个问题
- 介绍2 :怎么准备数据
- 介绍3 :怎么提出问题
- 介绍4 :使用模型预测答案
- 介绍5 :学习他人成果
数据科学可以解答的问题
数据科学只可解答以下五种问题:
以上每个问题都由一系列的机器学习方法(称为算法)回答。
将算法视为配方,数据视为材料, 算法告知如何组合以及混合数据以获取答案。 计算机如同搅拌机, 它们可快速完成算法的大部分繁琐工作。
问题1:是A还是B?使用分类算法
是A还是B使用二元分类算法,对于任何仅有两种可能答案的问题很有用。 例如:
- 此轮胎是否会在下一千英里中出现故障:是或否?
- 以下哪种方案可吸引更多顾客:5美元优惠券或25%折扣?
此问题还可进行扩展为两个以上的选项:这是 A、B、C 还是 D,等等。这称为多元分类,对于有多个或数千个可能的答案时很有用。 多元分类选择可能性最大的那个答案。
问题2:这是否很奇怪?使用异常检测算法

如果你有信用卡,那么已从异常检测中获益。 信用卡公司会分析购买模式去提醒用户可能的被欺诈行为。 “异常”消费可能是在一家通常不会去购物的商店购物时,或着购买非常昂贵的物品。此问题在很多方面都很有用。 例如:
- 如果汽车上配有压力表,可能会想知道:此压力表读数是否正常?
- 如果正在监控 Internet,就会想知道:此消息是否是来自 internet 的典型消息?
异常检测标志意外或异常事件或行为。 它会提供在何处查找问题的线索。
问题3:多少?使用回归算法

回归算法进行数字预测,例如:
- 下周二的气温是多少?
- 第四季度销售额有多少?
它们可帮助回答任何寻求数字答案的问题。
问题4:怎么组织?使用聚类分析算法

有时希望了解数据集的结构 - 组织方式为何? 对于此问题,并没有已经知道结果的示例。
可通过多种方法梳理出数据结构。 其中一种方法就是聚类分析。 为方便解释,该方法将数据分成多个自然“群”。
使用聚类分析,不会存在正确答案。
聚类分析问题的常见示例有:
- 哪些观众喜欢同类型的电影?
- 哪些打印机型号出现故障的方式相同?
通过了解数据的组织方式,可以更好地了解并预测行为和事件。
问题5:应该做什么?使用强化学习算法

强化学习的灵感来自于老鼠和人类的大脑对惩罚和奖励的反应。 这些算法从结果中学习,并决定下一步操作。
通常,强化学习适用于自动系统,这些自动系统需要在没有人工指导的情况下做出大量小决策。
算法总是用于回答此类问题:(通常指计算机或机器人)应采取何种操作。 示例如下:
- 如果是房子的温度控制系统:调整温度或保持其原温度?
- 如果是自动驾驶汽车:黄灯时,刹车或加速?
- 对于机器人吸尘器:继续吸尘或返回充电站?
强化学习算法在执行过程中收集数据,从试验和错误中学习。
准备数据
必须先提供一些优质原材料(数据)供数据科学分析,它才能提供你所需的答案。就像做披萨一样,制作前准备的原料越好,最终的产品也会越好。
数据要素:
数据是否相关?

左侧表格列出了在波士顿酒吧外测试的七个人的血液酒精含量、红袜队最后一场比赛的击球率以及最近的便利店中的牛奶价格。
此数据完全准确。 唯一的问题是它们不相关。 这些数字之间没有明显的关系。
然后观察右侧的表。这一次,我们测量了每个人的体重以及他们饮酒的量。
现在,每行中的数字彼此相关。如果提供体重和喝的玛格丽塔数量,便可猜测血液酒精含量。
数据是否连贯?

以下是一些关于汉堡质量的相关数据:烤制的温度、肉饼的重量和以及在用户评价等级。
但请注意左侧表中的空白处。其实大多数数据集都缺少某些值。这样的空白很常见,是可以解决的。
但是如果值缺失过多,就很难找出烤制温度和肉饼重量之间存在的关系。
但是,右侧表数据很完整,是连贯数据的示例。
数据是否精确?
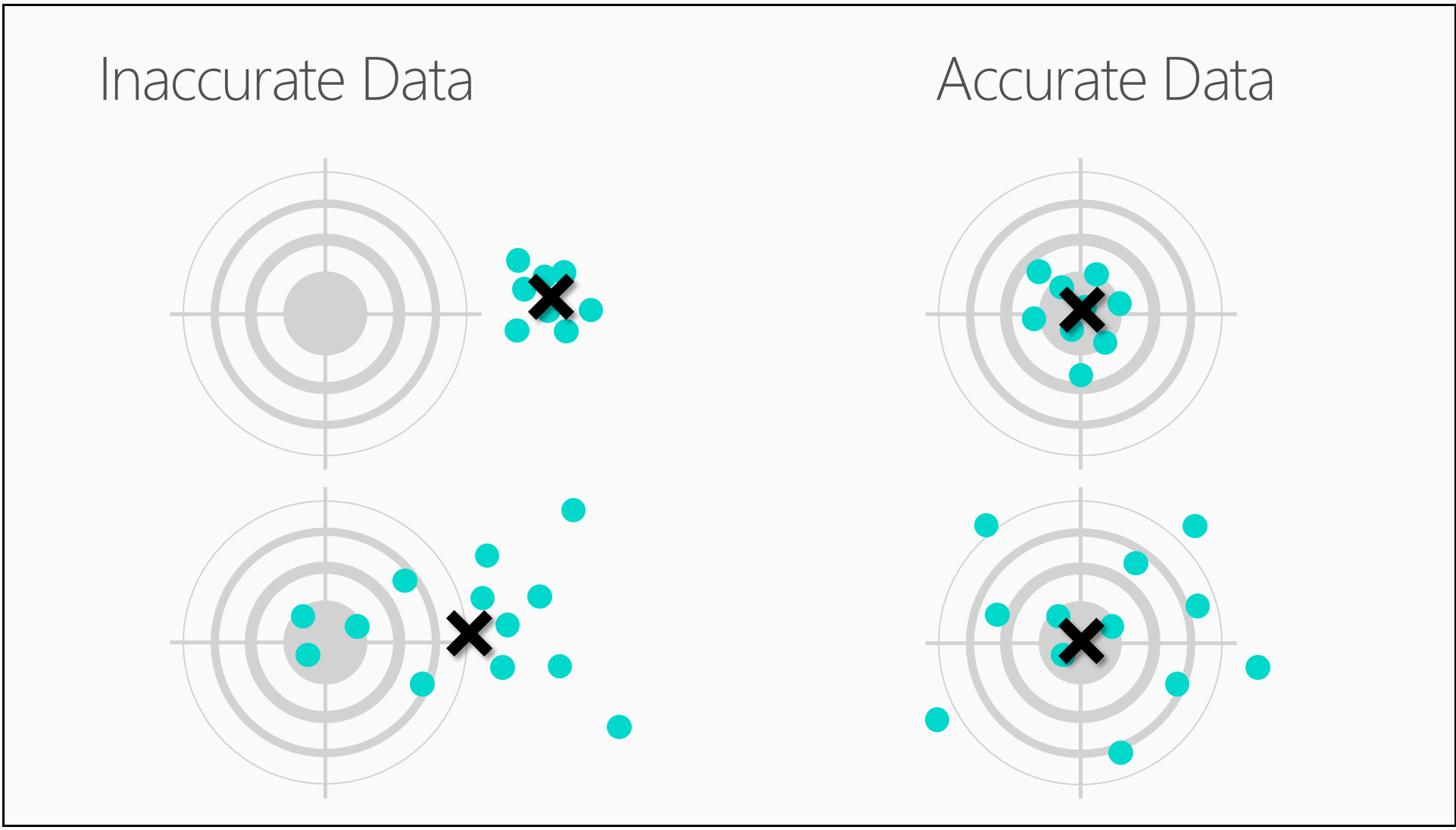
以上是四个要命中的靶子。
看看右上角的靶子。在靶心附近有一组紧密聚集的数据。当然,这是准确的。奇怪的是,在数据科学中,右下方靶子所呈现的数据也被视为准确数据。
如果标出这些箭支的中心点,会发现它非常靠近靶心。箭支分散在靶子四周,因此认为其不精确。但它们都是以靶心为中心围绕分布,所以认为其是准确的。
现在看看左上方靶子。这里的箭射得很近,在这个靶子上,箭支击中的点非常集中,形成一个紧密集聚的组。它们是非常精确的,但因其中心远离靶心,所以他们所反应的数据是错误数据。左下方靶子中的箭支是错误且不精确的。 这名弓箭手需多加练习。
数据是否足够?

将表中的每个数据点视为画作中的每一笔触。如果只有少许几笔,则这幅画会模糊,很难分辨它是什么。
添加的笔触越多,画的轮廓就越清晰。
随着添加的数据增多,图片变得更为清晰,可以进行一些更具体的判断。
有了相关、连贯、准确且充足的数据,就有了进行优质数据科学分析所需的全部要素。
提出问题
提出清晰具体的问题。
如果问它一个模糊的问题,比如“我的股票接下来如何?”,它可能会回答,“价格会改变”。这是一个正确的答案,但不是非常有帮助。
但是,如果提出一个清晰具体的问题,如“下周,我的股票售价如何?”,它便只能给出具体的回答,并预测售价。
示例答案
制定问题时,检查数据中是否有示例答案。
如果问题是“下周,我的股票售价如何?”,则必须确保数据包括股票价格历史记录。
如果问题是“车队中的那辆车会首先出现故障?”,则必须确保数据包括以前故障的相关信息。
这些示例答案被称为目标数据,若没有目标数据,则无法回答问题。
重新制定问题
问题“此数据是 A 还是 B?”,预测事物类别。若要回答此问题,请使用分类算法。
问题“多少?” 或着“数量?” 可对量进行预测。若要回答此问题,请使用回归算法。
若要了解如何转换这些问题,让我们来看看这个问题:“读者最感兴趣的是哪个新闻故事?” 这要求从多种可能性中预测某个单一选择 - 换句话说,“这是 A 还是 B 或 C 或 D?” - 这将使用分类算法。
但是,如果将问题改写为“读者对该列表中每个故事的感兴趣度为多少?”,则这个问题可能更容易回答。 现在,可以给每篇文章一个分数,并可轻松确定最高分的文章。 这是将分类问题改写为回归问题。
可以通过重新制定问题,从而使用能提供最佳答案的算法。
使用简单模型预测答案
假如我们想预测一个1.35 克拉的钻石的价格。我首先来到珠宝店,并记下当场所有钻石的价格和重量(以克拉为单位)。 然后绘制一个坐标,X轴为重量,Y轴为价格。接下来绘制数据并将其转换为散点图。连接数据点绘制模型并使用模型找出答案。

我们完成了需要聘请数据科学家才能完成的工作,完成方法仅是通过绘制:
- 提出可使用数据回答的问题
- 使用线性回归构建模型
- 进行预测,并借助置信区间完成
而且没有使用数学计算或计算机。
现在假设我们有更多信息,例如钻石的切割、颜色差异(钻石的颜色与白色的接近程度)、钻石中杂质量...那么我们会有更多列。
在这种情况下,数学计算就很有用。
如果有两个以上的列,则很难在纸上描点。数学计算能使线或平面与数据很好地对应。
此外,如果不是只有少量钻石,而是有两千颗或两百万颗,那么使用计算机能更快完成此工作。
学习他人成果
Microsoft 拥有一项基于云的服务,名为 Azure 机器学习工作室,可以免费进行试用。
它提供了一个工作区,可在其中使用不同的机器学习算法进行试验。
此服务的一部分被称为 Azure AI 库。 它包含资源,包括 Azure 机器学习试验或模型(由用户生成并贡献给他人使用)的集合。 这些试验是利用他人的想法和工作成果,开始自己的解决方案的绝佳方式。