1、前言
ansj人名识别会用到两个字典,分别是:person/asian_name_freq.data、person/person.dic。
1.1、asian_name_freq.data
这是一个二进制文件,序列化了一个Map对象。该对象的key为词,value是大小为3的数组。例如:
罗=[[644, 40], [2048, 140, 74], [19, 28, 39, 29]]
value数组各元素分别是大小为2、3、4的数组,分别表示在2字姓名、3字姓名、4字姓名中第1-2,1-3,1-4位置出现的频率(为叙述简单,本文不考虑复姓的情况)。
也就是说,“罗”出现在二字姓名首位的频率是644,末位是40;出现在三字姓名首位的频率是2048,中间是140,末位是74;出现在四字姓名首位的频率是19。
事实上,该Map的key可以是单字,也可能是个词,例如:
高中=[[13, 2], [0, 0, 0], [0, 0, 0, 0]]
这也就意味着,“高中”出现在三字姓名前两个位置(比如“高中伟”)的频率是13,出现在三字姓名后两个位置(比如“王高中”)的频率是2。
1.2、person.dic
该字典存储了人名的上下文环境,分为三类:
11-人名的下文、12-两个中国人名之间的成分、13-可拆分为姓名的词(例如“超生”这个词,“超”字可能会和前词组成姓名)。
这三类词,都会对名字的识别带来争议。
1.3、何时触发人名识别
对于Term类的一个实例term,如果term.termNatures().personAttr.flag为true,那就说明该term可能是人名的开头,就会触发人名识别。
其中,personAttr是PersonNatureAttr(人名标注类)的实例。
在PersonAttrLibrary.init2()中加载asian_name_freq.data文件时,会调用PersonNatureAttr.setlocFreq(int[][] ints)对term的姓名词频进行赋值,代码如下:
public void setlocFreq(int[][] ints) {
for (int i = 0; i < ints.length; i++) {
if (ints[i][0] > 0) {
flag = true;
break ;
}
}
locFreq = ints;
}
如果term可以是四字姓名或者三字姓名或者二字姓名的首字(一般情况下,这就是姓氏),personAttr.flag就会被设置为true。
例如,“罗”可以是姓名首字,“高中”也可以是姓名的开头,这两个词都会触发人名识别。再如,
颖=[[0, 351], [0, 712, 1071], [0, 1, 5, 13]],
说明“颖”不能是姓名的开头,不会触发人名识别。
也就是说,遇到可以是姓名开头的词(一般是姓氏),才会触发人名识别。
这会有一个问题,比如“这里有关天培的壮烈”这句话,人名识别之前的分词结果是:
[这里/r, null, 有关/vn, null, 天/q, 培/v, 的/uj, 壮烈/a, null, 末##末],
“有关”不能是姓名开头,导致识别不出“关天培”。
2、具体实现
ansj人名识别是以基于角色标注的中国人名自动识别研究为理论指导的,但与其又有不同。
2.1识别出可能的人名
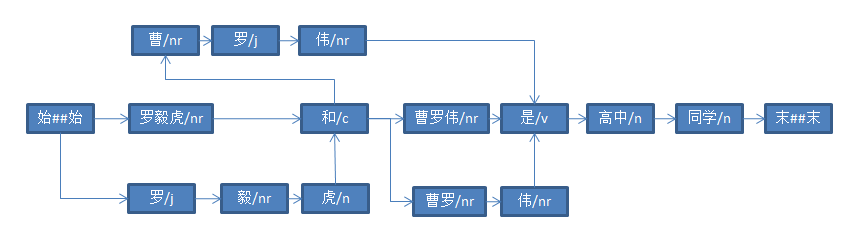
以“罗毅虎和曹罗伟是高中同学”为例:
Result terms = ToAnalysis.parse("罗毅虎和曹罗伟是高中同学");
System.out.println("分词结果:" + terms);
由于“罗”是姓氏,触发人名识别,首先判断“罗毅虎和”这个四字名有没存在的可能性。
“和”出现在四字姓名第四个位置的频率为0,所以不认可“罗毅虎和”这个四字姓名。
然后判断“罗毅虎”这个三字姓名是否可能存在,当然这是可能的。
接下来,程序并没有去判断“罗毅”这个二字名是否存在,因为“罗毅虎”是无争议的人名。所谓无争议,是指这个人名中的,没有person.dic字典里面的词。“曹罗伟”就是个有争议的人名,因为“伟”字存在于person.dic,“伟”可能是人名的下文环境,因为还要识别出“曹罗”这个二字名,随后会比较“曹罗伟”和“曹罗”哪个在此处更适合做人名。
“曹罗”也是个无争议的人名,识别出来后,会直接跳过“曹罗”,从“伟”开始识别下一个人名。因此不会识别出“罗伟”这个人名。
最终识别出了“罗毅虎”、“曹罗伟”、“曹罗”三个人名,如下图所示:
2.2、计算人名概率的一些理论基础
要想判断“曹罗伟”和“曹罗”哪个在此处更适合做人名,当然要计算二者存在的概率。
在谈到ansj的计算方法之前,我们先共同学习一下基于角色标注的中国人名自动识别研究这篇论文。(强烈建议读了这篇论文再往下看)
该论文将人名识别问题转化为了,对人名构成角色进行标注的问题。(详见论文的2.1、2.2)
我们要求解最终标注结果$T^{#}=arg_{T}\,max\,P(T|W)$
论文中并不是直接求解$P(T|W)$,而是通过Bayes公式间接求解:
$P(T|W) = P(T)P(W|T)/P(W)$
没有直接求解,无非就是因为$P(T|W)$直接求解比较困难,或者根本无法直接求解。
我们先来看$P(t_{i}|w_{i})$是指:Token序列中的$w_{i}$,角色是$t_{i}$的概率。例如,对于人名识别前的Token序列:
[罗/j, 毅/nr, 虎/n, 和/c, 曹/nr, 罗/j, 伟/nr, 是/v, 高中/n, null, 同学/n, null, 末##末]
$P(t_{i}|w_{i})$可以是指,“曹”这个$w_{i}$,角色是“三字姓名姓氏”的概率。
在大规模语料库训练的前提下,我们可以得到:
$P(t_{i}|w_{i})approx C(t_{i},w_{i})/C(w_{i})$
其中,$C(t_{i},w_{i})$指角色$t_{i}$中出现$w_{i}$的次数,$C(w_{i})$是$w_{i}$出现的次数。
以ansj为例,直接求解$P(T|W)$会有两个问题:
(1)、$C(w_{i})$是从大规模预料中统计出来,并保存在core词库中的,对该核心词库的整理,与人名识别无关,例如:
32599 罗 170307 -1 2 {j=25, nr=3, q=0, v=0}
而$C(t_{i},w_{i})$是为了人名识别,根据大规模的人名统计出来,并保存在asian_name_freq.data中的,例如
罗:[[644, 40], [2048, 140, 74], [19, 28, 39, 29]]
这两个数据是从两种完全不同的语料的中统计出来的,导致$C(t_{i},w_{i})$远大于$C(w_{i})$,这样算出来的$P(t_{i}|w_{i})$远大于1,显然是不对的。
(2)、假如$P(t_{i}|w_{i})$和$P(t_{i-1}|w_{i-1})$之间是相互独立的事件,那么可以用连乘的方式求得联合概率,即:
$P(T|W)=prod_{i=0}^{m}P(t_{i}|w_{i})$
但二者显然不是相互独立是事件。比如,对于一个$w_{i}$“明”,如果$w_{i-1}$的角色是姓氏,那么$w_{i}$是人名的概率自然会高一些。
值得一提的是,$P(w_{i}|t_{i})$和$P(w_{i-1}|t_{i-1})$之间是相互独立的事件。
$P(w_{i}|t_{i})$是指角色为$t_{i}$的Token集合中$w_{i}$的概率。
例如:
$P(w_{i-1}|t_{i-1})$可以是:角色为“姓氏”的集合中“罗”的概率;
$P(w_{i}|t_{i})$可以是:角色为“双名的首字”的集合中“毅”的概率。
这二者之间是独立的。
论文中提到,$P(W)$是一个常数。这确实是一个常数。并且,我们已经在现有核心词库(core.dic)的基础上,算得了这个数值。这正是上一节所讨论的内容。
2.3、计算人名概率
以下讨论的是ansj的人名算法。
(1)、首先不考虑上下文,计算人名的概率
在这里ansj并没有使用论文中的方法,而是另辟蹊径。遇到姓氏后就断定这可能是个人名,然后开始计算概率。事先统计好了二字姓名、三字姓名、四字姓名在所有人名中所占的比例,存放在AsianPersonRecognition类中的FACTORY属性。
FACTORY = { 0.16271366224044456, 0.8060521860870434, 0.031234151672511947 }
例如,遇到一个姓氏时,假设这是一个三字姓名,然后计算概率,此时这三个字的角色已经确定(第一个字是姓氏,第二个字是名字首位,第三个字是名字末位)。
P(该三字人名概率)= P(三字人名所占比例) * $prod_{i=0}^{3}P(w_{i}|t_{i})$
上面已经提到,
$P(t_{i}|w_{i})approx C(t_{i},w_{i})/C(w_{i})$
从而有:
$-ln\,P(t_{i}|w_{i})approx ln\,C(t_{i},w_{i}) - ln\,C(w_{i})$
计算$-ln\,P(t_{i}|w_{i})$的代码,位于AsianPersonRecognition.nameFind(int offe, int beginFreq, int size):
allFreq += Math.log(term.termNatures().allFreq + 1); allFreq += -Math.log((freq));
但问题是,$C(w_{i})$ 和$C(t_{i},w_{i})$的统计来自不同的语料,所以这里的算法是没有理论依据的。
2.4、构造最短路径
计算完概率后,就可以使用Viterbi算法来求解最短路径,这与上一节类似。
以“陈颖超生前很和蔼”为例,将会得到以下结果:
[陈颖/nr, null, 超生/v, null, 前/f, 和蔼可亲/i, null, null, null, 末##末]
2.5、人名消歧
在上述例子中,需要对“超生”进行拆分,并且将“超”与之前的人名合并。
代码位于NameFix类的nameAmbiguity(Term[] terms, Forest... forests)方法。
程序不对单字名进行拆分(例如,“陈超生前和蔼可亲”最终分词结果是:[陈/nr, 超生/v, 前/f, 和蔼可亲/i],这是不对的)。
经过人名消歧,将得到如下结果:
[陈颖超/nr, null, null, 生/v, 前/f, 和蔼可亲/i, null, null, null, 末##末]
2.6、用户自定义字典识别
代码是ToAnalysis类中的:
// 用户自定义词典的识别 userDefineRecognition(graph, forests);
在用户自定义字段librarydefault.dic中,是存在“生前”这个词的,经过这一步,会将“生前”进行合并,得到最终结果:
[陈颖超/nr, 生前/t, 和蔼可亲/i]
对于用户自定义词典的识别,打算在下一节进行详细说明。