最近在学习NodeJs。从nodejs语言本身,看了朴灵的《深入浅出NodeJs》,《Node即学即用》。个人感觉朴灵的这本书适合node入门后乃至中级程序员去阅读。而后者则可以完全当做初级入门教材使用。当然我认为最快捷的学习路径是看视频。这里推荐 慕课网的node视频,讲的还是非常不错的。虽然说nodej是Javascript在服务端的一种表现,严格来说算不上说是一种新的语言。连官方也说,其强大的性能来源于google的v8引擎。换句话说,以前Javascript在客户端的浏览器里运行。PC机器为浏览器预留了一大块内存空间,在浏览器建立了一个JavaScript解释器,也就是V8引擎。只是Ryna Dahl把这个引擎移动到了服务端。
了解完这个这个前提之后,就能揭开NodeJs的神秘面纱了。至于NodeJs于JavaScript在表现上有何异同,大家可以去参考相对基础的文章去了解基础知识。如果JavaScript还不太了解,还是建议阅读《JavaScript权威指南》(犀牛书虽然特别大部头,但是读起来特别爽快,就好像Javascipt大牛跟你面对面交流似得,好像他就知道你这里不懂,真是贴心到想哭)。学完了nodejs和一些核心包,以及数据库框架,终于准备动手做一些东西了。在做的过程中也对nodejs有了更深的了解,其中最大的坑也就是nodejs的异步执行,这也是nodejs的最大特点。后来了解到Promise这个Es6的新特性。可以让代码的流程执行的更加清晰明了。
推荐http://www.cnblogs.com/lvdabao/p/es6-promise-1.html
下面是使用nodejs抓取博客园前10页所有的文章标题和文章对应的链接。代码中有详细注释,有问题的可以评论区讨论。
1 var http = require('http'); //引入nodejs的http模块,该模块用于构建http服务和作为HttpClient使用。 2 var promise = require('promise'); //对异步编程进行流程控制,更加符合后端程序员的编程习惯。 3 var cheerio = require('cheerio'); //可以理解为服务端的Jquery。使用方法和客户端一样。 4 5 var url = 'http://www.cnblogs.com/#p'; //要抓取的网址。博客园的页数是通过添加锚点的,后面有拼接 6 7 8 //Promise 在任何情况下都处于以下三种状态中的一种: 9 //未完成(unfulfilled)、已完成(resolved)和拒绝(rejected) 10 //事件已完成则使用成功的callback(resolve)返回自身,失败了则 11 //选择使用callback(reject)来返回失败的自身。 12 13 function getPageList(url){ 14 //return Promise对象 15 return new Promise(function(resolve,reject) { 16 http.get(url,function(res) { 17 var body = ''; 18 19 //当接受到数据的时候,http是执行范围请求的。所以每个范围请求就是一个chunk。 20 res.on('data', function(chunk) { 21 //buffer是一种node处理二进制信息的格式,不必理会。 22 res.setEncoding('utf8'); //设置buffer字符集 23 body += chunk; //拼接buffer 24 }); 25 26 //当整个http请求结束的时候 27 res.on('end', function() { 28 var $ = cheerio.load(body); //将html变为jquery对象。 29 var articleList = $('.post_item'); 30 var articleArr = []; 31 articleList.each(function() { 32 var curEle = $(this); 33 var title = curEle.find('.post_item_body h3').text(); //获取标题 34 var href = curEle.find('.post_item_body h3 a').attr('href'); //文章链接 35 articleArr.push({ 36 title:title, 37 href:href 38 }); 39 40 41 }); 42 43 //成功的状态使用resolve回调函数。 44 resolve(articleArr); 45 46 }); 47 48 //当执行http请求失败的时候,返回错误信息 49 res.on('error', function(e) { 50 reject(e.message); 51 }); 52 53 54 55 }) 56 }) 57 } 58 59 60 //请求博客园前10页的数据。将所有的请求预先放置在集合内。 61 var list = []; 62 for(var i=1;i<=10;i++) { 63 var url = url+i; 64 list.push(getPageList(url)); 65 66 } 67 68 //调用Promise的下面的all方法。参数是一个事件集合。 69 //Promise将会进行异步执行。但是最后的返回时机要根据最耗时的那个请求为标准。 70 //then(),可以接受两个参数(callback).第一个参数是成功(resolved)的回调。 71 //第二个参数是执行上个操作失败(rejected)的回调。 72 Promise 73 .all(list) 74 .then(function(data) { 75 console.dir(data); 76 })
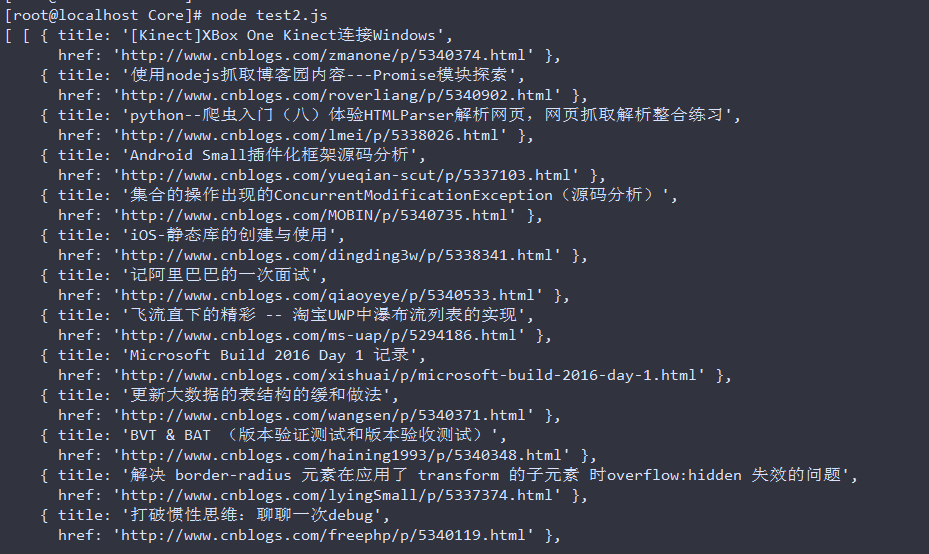
以下是结果:
此前工作繁忙,这段时间空下来了。从今天起,将会陆续介绍nodejs或者是其他方面的东西。