https://blog.csdn.net/wangyangzhizhou/article/details/76651116 共三篇
RNN的模型展开后多个时刻隐层互相连接,而所有循环神经网络都有一个重复的网络模块,RNN的重复网络模块很简单,如下下图,比如只有一个tanh层。

而LSTM的重复网络模块的结构则复杂很多,它实现了三个门计算,即遗忘门、输入门和输出门。每个门负责是事情不一样,遗忘门负责决定保留多少上一时刻的单元状态到当前时刻的单元状态;输入门负责决定保留多少当前时刻的输入到当前时刻的单元状态;输出门负责决定当前时刻的单元状态有多少输出。
每个LSTM包含了三个输入,即上时刻的单元状态、上时刻LSTM的输出和当前时刻输入。

https://blog.csdn.net/thriving_fcl/article/details/73381217
主要参考的论文是Hierarchical Attention Networks for Document Classification。这里的层次Attention网络并不是只含有Attention机制的网络,而是在双向RNN的输出后加了Attention机制,层次表现在对于较长文本的分类,先将词向量通过RNN+Attention表示为句子向量,再将句子向量通过RNN+Attention表示为文档向量。两部分的Attention机制是一样的,这篇博客就不重复说明了。
BIRNN

attention
1. 原来的Encoder–Decoder
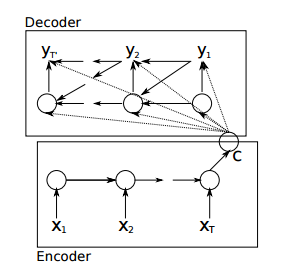
在这个模型中,encoder只将最后一个输出递给了decoder,这样一来,decoder就相当于对输入只知道梗概意思,而无法得到更多输入的细节,比如输入的位置信息。
2. 对齐问题
前面说了,只给我递来最后一个输出,不好;但如果把每个step的输出都传给我,又有一个问题了,怎么对齐?
什么是对齐?比如说英文翻译成中文,假设英文有10个词,对应的中文翻译只有6个词,那么就有了哪些英文词对哪些中文词的问题了嘛。
3. attention机制
https://www.cnblogs.com/shixiangwan/p/7573589.html
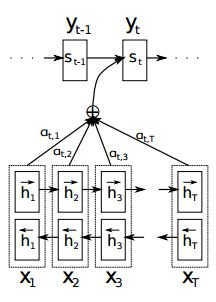
这个g可以用一个小型的神经网络来逼近,它用来计算St−1 、hj这两者的关系分数,如果分数大则说明关注度较高,注意力分布就会更加集中在这个输入单词上,这个函数在文章Neural Machine Translation by Jointly Learning to Align and Translate(2014)中称之为校准模型(alignment model),文中提到这个函数是RNN前馈网络中的一系列参数,在训练过程会训练这些参数。
把四个公式串起来看,这个attention机制可以总结为一句话:当前一步输出St应该对齐哪一步输入,主要取决于前一步输出St−1和这一步输入的encoder结果hj。
(该结论有时表述为只与encoder结果有关)