3.1 概述
内存管理涵盖了许多领域:
- 内存中物理内存页的管理;
- 分配大块内存的伙伴系统;
- 分配小块内存的slab、slub、slob分配器;
- 分配非连续内存块的vmalloc机制;
- 进程的地址空间。
Linux内核一般将虚拟地址空间划分为两部分:底部较大的部分用于用户进程,顶部则用于内核。虽然(在两个用户进程之间)上下文切换期间会改变下半部分,但是虚拟地址空间的内核部分中总是不变【这其实很好理解,内核是系统管理员,不能说因为每换一批游客,景区管理员都得跟着换一批?!】。在IA-32系统上,虚拟地址空间在用户进程和内核之间划分的典型比例是3:1【arm亦是如此,但是我们使用的mips是2:2的划分。为什么这么划分呢?不解。】。通过修改配置选项可以改变比例,但是只有对非常特殊的配置和应用程序,这种修改才会带来好处。
可用的物理内存将映射到内核的地址空间中【为什么呢?因为物理内存是内核来管理的,用户空间申请内存必然要通过kernel的分配】。访问内存时,如果所用的虚拟地址空间地址与内核区域的起始地址之间的偏移量不超出物理内存的长度,那么该虚拟地址会自动关联到物理页帧【例如在IA-32系统上,内核的虚拟地址空间只有1GB,但是如果物理内存的大小小于1GB,那么直接线性映射就可以】。不管还有一个问题,如我们所知,在IA-32位系统,大部分人会装4G内存,那么内核如何用1G的虚拟地址空间来管理者4G内存呢?如果物理内存比可以映射到内核地址空间中的数量要多,那么必须借助高端内存(highmem)方法来管理“多余的内存”。在IA-32系统上,可以直接管理的物理内存数量不超过896MB。超过该值的内存只能通过高端内存寻址【为什么是896?!满足两个约束条件:1.直接映射的内存尽量多 2.剩余的虚拟地址空间足够管理多余的内存】。
主:1. 内核使用高端内存之前,必须使用kmap和kunmap函数将其映射到内核虚拟地址空间中,对普通内存这是不必要的。因为普通内存和内核虚拟地址空间存在线性映射关系,但是高端内存必须在使用时临时建立映射。所以访问普通内存要比高端内存块。
2. 对用户进程来说,是高端内存还是普通页完全没有任何差别。因为用户空间总是通过页表访问内存,绝不会直接访问。
有两种不同的计算机,分别以不同的方法管理内存。
(1)UMA计算机(一致内存访问,uniform memory access)将可用内存以连续的方式组织起来(可能有小缺口)。SMP系统中每个处理器访问各个内存区一样快。
(2)NUMA计算机(非一致内存访问,non-uniform memory access)总是多处理器的计算机。系统的各个CPU都有本地内存,可支持特别快速的访问。各个处理器之间通过总线连接起来,以支持对其他CPU的本地内存访问,当然比访问本地内存慢些。
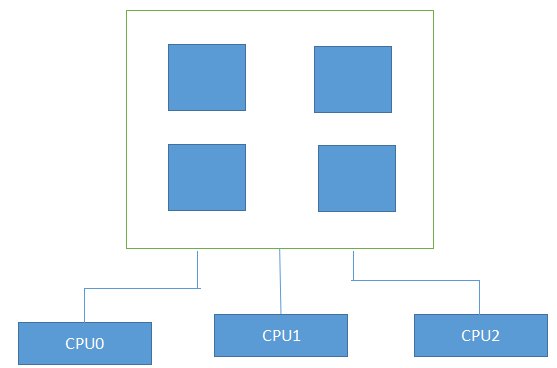
UMA系统

NUMA系统
两种类型计算机的混合也是可能的,其中使用不连续的内存。即在UMA系统中,内存不是连续的,而有比较大的洞。此时使用NUMA体系结构的原理可以使内核的内存访问更简单。实际上内核会区分3中配置选项:FLATMEM、DISCONTIGMEM和SPARSEMEM。DISCONTIGMEM和SPARSEMEM实际作用相同,但从开发者的角度讲,对应代码的质量有所不同。SPARSMEM被认为更多是实验性的,不那么稳定,但有一些性能优化。我们认为DISCONTIGMEM相关代码更稳定一些,但不具备内存热拔插之类的新特性。
FLATMEM是内核的默认配置,也是使用最多的内存组织类型。我们主要讨论FLATMEM。
真正的NUMA会配置选项CONFIG_NUMA,相关内存管理的代码与上述两种变体有所不同。通过配置NUMA_EMU可以使用平坦内存模型的AMD64系统来感受NUMA系统的复杂性,实际上将内存划分为加的NUMA内存域。由于某种原因,NUMA计算机过于昂贵。
我们集中讨论UMA系统,不考虑OCNFIG_NUMA。由于UMA系统可以在地址空间有比较大的洞是选择配置选项CONFIG_DISCONTIGMEM,这种情况下即使不采用NUMA技术但是系统也会有多个内存结点。所以NUMA相关的数据结构不可完全忽略。

注意:在下文中,我们经常会用到术语分配阶(allocation order)。它表示内存区中页的数目以2为底的对数。阶0的分配由一个页面组成,阶1的分配包括2^1 = 2个页。