行存储 与 列存储
行业业务集中焦点:
- 有效地处理海量数据
- 兼顾安全, 可靠, 完整性
- example: HBase采用列存储, MongoDB采用文档型的行存储, Lexst采用二进制的行存储
列存储(column-based)
传统关系型数据库行式存储(Row-based storage storestable in a sequence of rows)
列存储(Column-based storage storesatable in a sequence of columns)
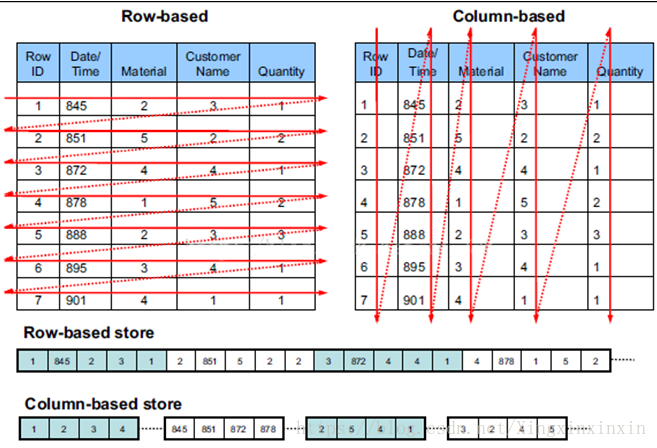
行式存储下一张表的数据是放在一起的, 但列式存储下都被分开保存了。
数据写入对比
- 行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上, 可以保证写入过程的成功或者失败, 数据的完整性因此可以确定。
- 列存储由于需要把一行记录拆分成单列保存, 写入次数明显比行存储多(意味着磁头调度次数多, 而磁头调度需要时间, 一般在1ms ~ 10ms), 再加上磁头需要在盘片上移动和定位话费的时间, 实际时间消耗会更大。所以, 行存储在写入上占有很大的优势。
- 数据修改实际上也是一次写入过程。区别是数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次, 而列存储是将磁盘定位到多个列上分别写入, 这个过程仍是行存储的列数倍, so数据修改也是行存储占优势。
数据读取对比
- 数据读取时, 行存储通常将一行数据完全读出, 如果只需要其中几列数据的情况, 就会存在冗余列, 出于缩短处理事件的考量, 消除冗余列的过程通常是在内存中进行的。
- 列存储每次读取的数据是集合的一段或者全部, 不存在冗余性问题
- 两种存储的数据分布。由于列存储的每一列数据类型是同质的, 不存在二义性问题。For instance, 某列数据类型为int(整形), 那么它的数据集合一定是整形数据。这种情况使数据解析变得十分容易。相比之下, 行存储反而要复杂不少, 因为在一行记录中保存了多种类型的数据, 数据解析需要在多种数据类型之间频繁转化,而该操作很吃cpu, 增加了解析的时间。所以, 类存储的解析过程更有利于分析大数据。
- 数据的压缩以及更性能的读取方面对比
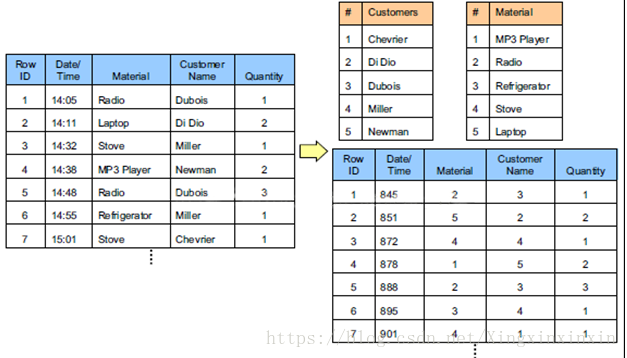
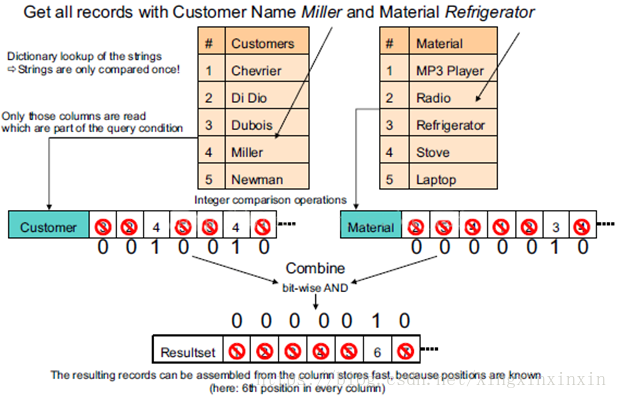
优缺点
- 行存储:
- 优点: 行存储的写入是一次性完成的, 消耗的时间比列存储少, 并且能够保证数据的完整性
- 缺点: 数据读取过程中会产生冗余数据, 如果只看少量数据, 此影响可以忽略; 数量大可能会影响数据的处理效率
- 列存储:
- 优点: 在读取过程中, 不会产生冗余数据, 这对数据完整性要求不高的大数据处理领域尤为重要(i.e. 互联网)
- 缺点: 写入效率, 保证数据完整性上都不如行存储
列存储的适用场景
概念
- OLTP (OnLine TransactionProcessor) 在线联机事务处理系统: mysql, oracle...
- OLAP (OnlLine AnalaysierProcessor) 在线联机分析处理系统: Hive, HBase...
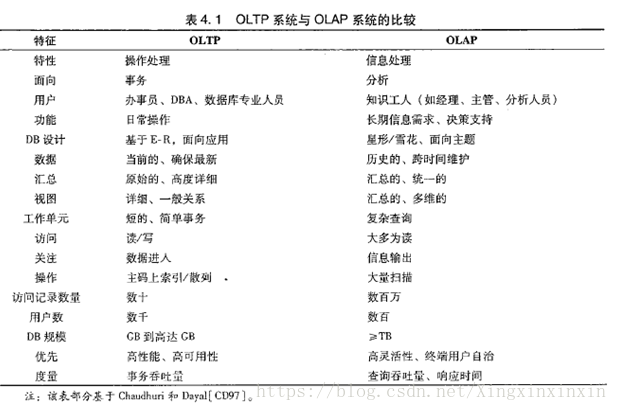
(1). 一般来说, 一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行, 且该查询往往只关心少数几个数据列, 而其他数据列对该查询是无意义的。
(2). 很多列式数据库还支持列族(column group[locality group]), 即将多个经常一起访问的数据列的各个值存放在一起。如果读取的数据列属于相同的列族, 列式数据库可以从相同的地方一次性读取多个数据列的值, 避免了多个数据列的合并。列族是一种行列混合存储模式, 这种模式能够同时满足OLTP和OLAP的查询需求。
(3). 由于同一数据列的数据重复度很高, 因此, 列式数据库压缩时有很大的优势.
(4). 如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据, 列式数据库并不适用。
行存储与类存储总结:
行式存储数据库:
- 数据是按行存储的。
- 没有索引的查询使用大量I/O。一般的数据库表都会建立索引, 通过索引加快查询效率。
- 建立索引和物化视图需要花费大量的时间和资源。
- 面对查询需求, 数据库必须被大量膨胀才能满足需求。
列式存储数据库:
- 数据按列存储, 即每一列单独存放。
- 数据即索引。
- 只访问查询涉及的列, 可以大量降低系统I/O。
- 每一列有一个线程来处理, 即查询的并发处理性能高。
- 数据类型一致, 数据特征相似, 可以高效压缩。 比如增量压缩, 前缀压缩算法都是基于列存储的类型定制的, 所以可以大幅度提高压缩比, 有利于存储和减少网络输出数据带宽的消耗。
数据存储格式
-
Avro Data Files
- avro是一个数据序列化系统, 它提供:
- 丰富的数据结构
- 快速可压缩的二进制数据格式
- 存储持久数据的文件容器
- 远程过程调用RPC
- 简单的动态语言结合功能
- 实现模式:
- 二进制编码: Avro-specific 方式依赖代码(文件)生成特定类, 并内嵌JSON Schema
- JSON编码: Avro-generic 方式通过JSON文件动态加载Schema, 不需要编译加载直接就可以处理新的数据源
- avro是一个数据序列化系统, 它提供:
-
Sequence Files
- 描述:
- 是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)
- 特点:
- 并不保证其存储的key-value数据是按照key的某个顺序存储的, 同时不支持append操作
- 每一个key-value被看作是一条记录(Record), 因此基于Record的压缩策略, SequeneceFile文件可支持三种压缩类型:
- NONE: 对records不进行压缩
- RECORD: 仅压缩每一个record中的value值
- BLOCK: 将一个block中的所有records压缩在一起
- 对应的Hadoop提供的三种类型的Writer
- SequenceFile.Writer 写入时不压缩任何的key-value对(Record);
- SequenceFile.RecordCompressWriter 写入时只压缩key-value对(Record)中的value;
- SequenceFile.BlockCompressWriter 写入时将一批key-value对(Record) 压缩成一个Block
- 描述:
-
Parquet Files
-
描述:
- Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language
无论数据处理框架,数据模型或编程语言的选择如何,Apache Parquet都是Hadoop生态系统中任何项目可用的列式存储格式
-
特点:
- 可以跳过不符合条件的数据, 只读取需要的数据, 降低IO数据量
- 压缩编码可以降低磁盘存储空间
- 只读取需要的列, 支持向量运算, 能够获取更好的扫描性能
- Parquet 格式是Spark SQL 的默认数据源, 可通过spark.sql.sources.default 配置
-
-
ORC(Optimized Row Columnar) Files
-
Hadoop生态圈中的列式存储格式, 最初产生自Apache Hive, 用于降低Hadoop数据存储空间和加速Hive查询速度
-
物理视图(HDFS)

- 逻辑视图
- 结构块:
- block
- stripe
- row_group
- stream
- index
- data
- Row data
- fileFooter
- postscript
- 存储结构
- orc在hdfs上存储, 为适应hdfs区块存储思想会将orc文件划分为block块
- orc的block块大小一般和hdfs的block大小一致,通过配置(hive.exec.orc.default.block.size 默认256M) 指定
- 每个block块中包含多个stripe, stripe大小通过参数 (hive.exec.orc.default.stripe.size 默认64M)
- 应尽量避免stripe跨hdfs: block存储, 否则在解析stripe时会存在IO跨节点的数据请求, 从而增加系统资源开销
- 一般orc: block块大小是orc:stripe大小的整数倍。但是在有些情况下是会出现block块不能被整数个stripe完整填满, 需要关闭跨hdfs:block的数据存储。(hive.exec.orc.default.block.padding=false)关闭块存储 另外需要指定最小磁盘利用空间( hive.exec.orc.block.padding.tolerance 默认0.05,例如orc:block=256M,256*0.05=12.5M),hdfs:block块剩余磁盘空间低于此值将放弃使用
-