介绍
MLR算法是alibaba在2012年提出并使用的广告点击率预估模型,2017年发表出来。
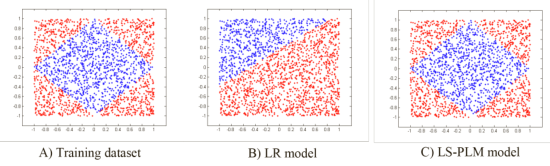
如下图,LR不能拟合非线性数据,MLR可以拟合非线性数据,因为划分-训练模式。
讨论,非线性拟合能力:
数据划分规则如下公式,特征分片数m=1时,退化为LR;上图MLR中m=4。m越大,模型的拟合能力越强,一般m=12。

基础知识
优化方法:
1)剃度下降:![]()
大小:一阶导数,方向:导数负方向。由目标函数的泰勒一阶展开式求得
2)牛顿法:![]()
大小:一阶导数,方向:-海信矩阵的逆。由目标函数的泰勒二阶展开式求
3)拟牛顿法(LBFGS):牛顿方向通过约等替换,每个样本保存下面三个参数:delta x ,delta剃度 和p:
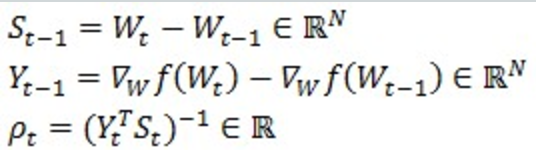
增量替换,计算牛顿方向D

LBFGS方法通过一阶导数中值定理,避免了计算海信矩阵(复杂度太大)。但是L1范数不能求导,所以需要OWLQN方法。
4)OWLQN:
(1)次梯度定义如下,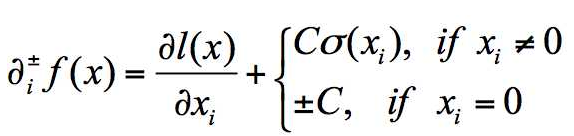
(2)不可导点取左or右次梯度,如下 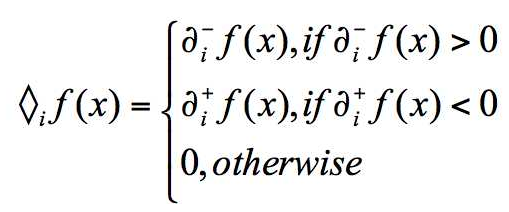
直观解释,当你打算用左偏导时,说明是在负象限,因此要加上一个负值,使得更新之后参数更往负象限前进,这样就避免了跨象限;当打算用右偏导数时,说明在正象限,一次要加上一个正值,使得更新之后参数更往正象限前进,从而避免跨象限;否则,只能直接设置subgradient为0。
(3)象限搜索line search: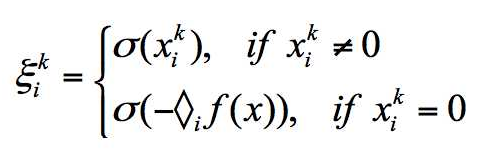
x不在0点时,line search在x_i所在象限搜索;如果模型参数在0点,就要在(2)次梯度约束的象限内进行line search.
MLR算法

算法公式如下:
0计算边界下降方向d:
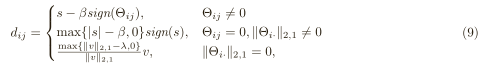
1计算梯度大小:theta在0处不可导,取sign符号函数dij。

2计算最终下降方向p:
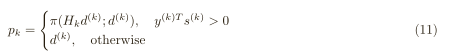
3象限内梯度下降,同OWLQN,line search:

paper介绍,MLR与LBFGS有三点不同:
1)OWLQN需要计算次梯度,MLR需要计算方向导数;
2)计算最终下降方向p时,MLR也要进行象限约束;
3)象限搜索line search,与OWLQN相似。
分布式框架实现
分布式
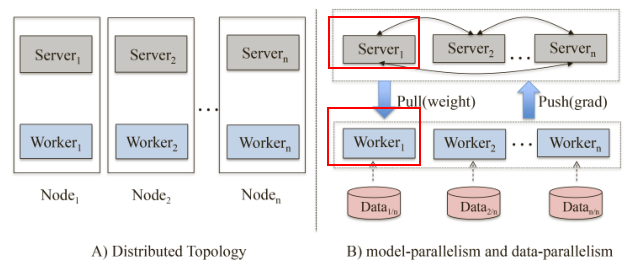
User特征共享
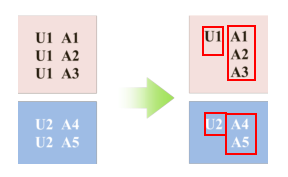
个人理解是为了加快运算速度,具体特征划分如下所示。其中,c是用户特征,nc是非用户特征。

实验结果
实验截图略,具体图表可以查看参考paper
纵坐标是内存使用率,特征共享技巧使速度提高了三倍。
参考paper:Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction