1、目标地址 http://quotes.toscrape.com
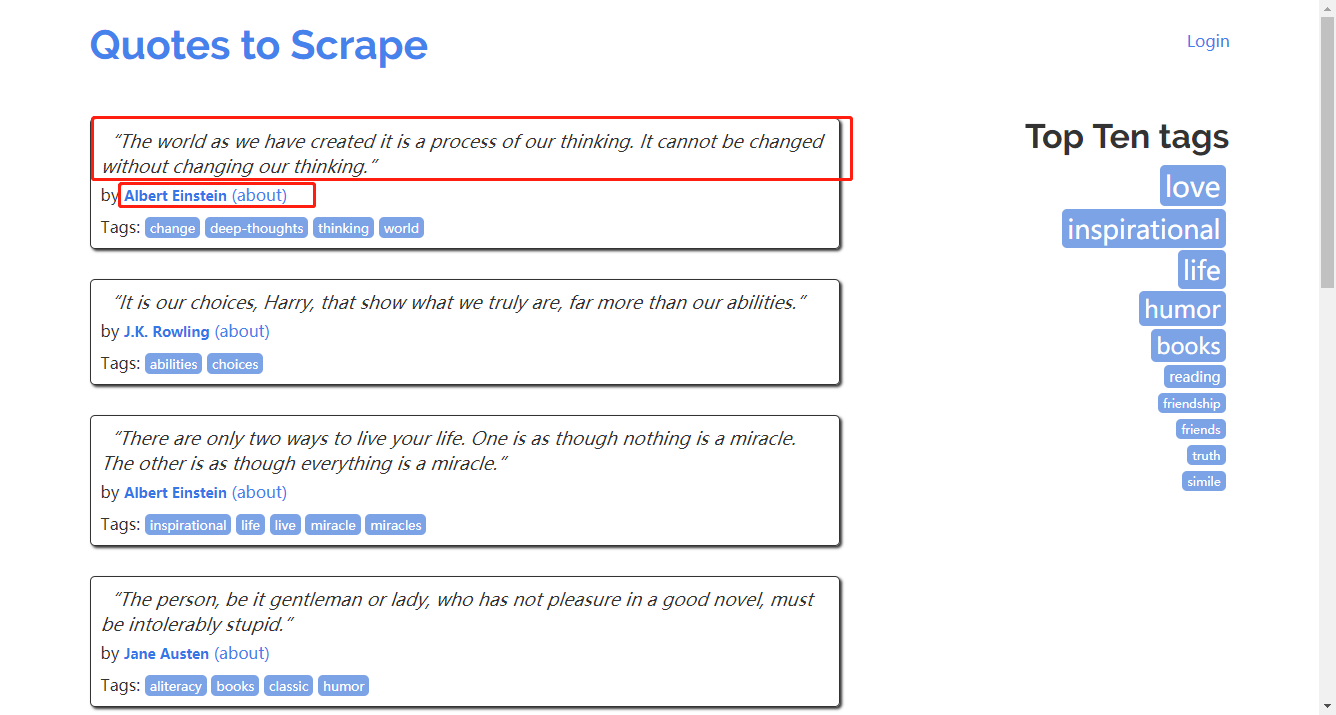
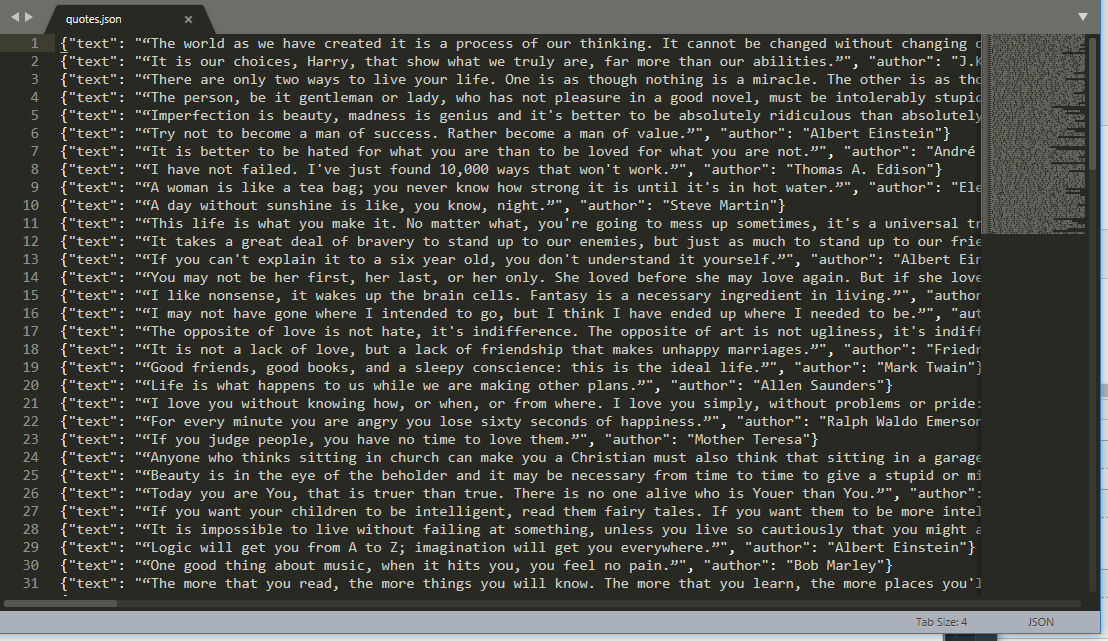
将页面的文章内容和作者爬下来,并保存到json文件里面。
下面代码:
用到的工具:scrapy ,xpath选择器,json,codecs编码
爬虫代码:
class ScrapeSpider(scrapy.Spider): name = 'toscrape' allowed_domains = ['toscrape.com'] start_urls = [ 'http://quotes.toscrape.com' ] def parse(self, response): for quote in response.xpath('//div[@class="quote"]'): item = QuoteItem() item["text"] = quote.xpath('./span[@class="text"]/text()').get() item['author'] = quote.xpath('./span/small[@class="author"]/text()').get() yield item next_page = response.xpath('//nav/ul/li[@class="next"]/a/@href').get() if next_page and len(next_page) > 0: yield response.follow(next_page, self.parse)
在items.py 中添加数据
class QuoteItem(scrapy.Item): text = scrapy.Field() author = scrapy.Field() pass
定义pipelines: 保存到quotes.json文件中
import json
import codecs
class QuotePipeline(object): def __init__(self): self.file = codecs.open('quotes.json', 'wb', encoding='utf-8') pass def process_item(self, item, spider): lines = json.dumps(dict(item), ensure_ascii=False) + " " self.file.write(lines) return item def close_spider(self, spider): self.file.close() pass
之后执行
scrapy crawl toscrape
爬下来的数据: