数据组织模式 是通过分区、分片、排序等方式将个别记录的价值突显出来。 分布式系统是可以通过分、分片及排序方式优化性能。
分层结构模式是从数据中创造出不同与原有结构的新记录。
当从 RDBMS 中将数据迁移至 hadoop 系统时,首先考虑将数据重新格式化成对计算更为有利的结构。
案例:
一个网站上的帖吧结构。 从RDBMS 迁移至 hadoop 系统时。 有很多数据并不总是能够分组在一起。当有人回答了帖子的一个问题时,hadoop 不能酱这条记录立刻插入到分层结构中。 因此需要周期性的用脚本为 MapReduce 创建非格式化的记录。
解决方式:
处理频繁持续更新的方式是用 HBase。 HBase 能够按照半结构化 和 分层样式存储数据。
适用范围:
1 数据被外键连接。
2 数据是结构化的并且是基于行的。
结构
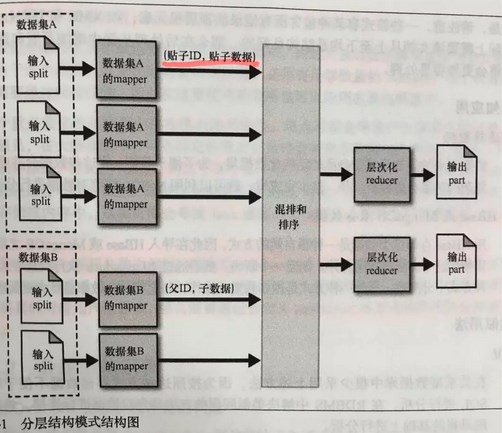
如果想把多个数据源合并成分层数据结构。 需要用到 Hadoop 中 MultipleInputs 类。(包含于 org.apache.hadoop.mapreduce.lib.input 中)
mapper
读入数据并将记录解析成更简洁的格式,便于 reduce 去处理。 输出键代表如何确定分层纪录的根。
本文中,帖子ID就是记录的根,还需要记录每块数据关于其来源的上下文。
一般来说,combiner 在此处基本没用,这里或许可以将具有相同键的项先合并然后再发送出去。但此处不会取得多大的压缩效果。因为这个功能要做的就是链接字符串。所以字符串输出的大小与输入是相同的。
reduce
不同来源的数据按照键一次发送至 reduce。 一个特定分组的数据会保存在一个迭代器中,因此剩下需要做的就是 根据数据项列表简历分层数据结构。比如 XML 或者 JSON。 推荐 JSON 尤其是 com.alibaba 的 fastjson。用起来很方便~
已知应用
预连接数据
数据到来最初形式是杂乱无章的结构化数据集,通过将这些数据合并为复杂的对象会更容易分析一些。
为 HBase 或其他分布式数据库准备数据
用 HBase 存储这类数据是一种很自然的方式。因此导入之前,可以使用这个方法将数据合并。创建一个表,然后通过 MapReduce 执行批量导入。 十分搞笑。(多轮插入 非批量 低效不推荐)
性能分析
1 需要知道 mapper 发送了多少数据给 reduce
2 需要知道 reduce 构建的对象占用了多少内存。
因为按键分组的记录零散的分布在整个数据集中,因此大量的数据需要通过网络迁移。 注意:必须要有足够数量的 reduce。下一个关注重点是数据中存在 热点 的可能性。因为这将会导致 Java 虚拟机堆栈溢出。 热点带来的另一个问题就是数据倾斜。 导致不同的 reduce 处理数据量的差别很大。 一般这种情况都是忽略。但是如果真的对应用产生影响,就需要自定义 partitioner 的方式将数据拆分得更为均匀。
示例
main{} : 1 使用多路径输入。 org.apache.hadoop.mapred.lib.MultipleOutputFormat;
2 加入多结构分析。
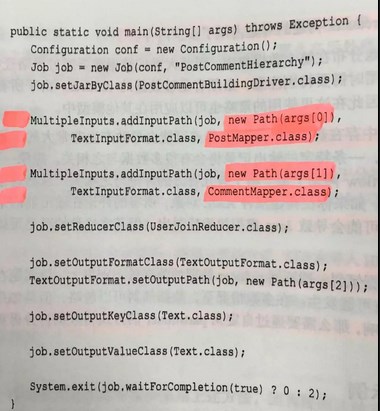
mapper : 做两套(N套)Mapper 继承类。 存入上图。 mapper 方法下图:
第二个 Map 类
reduce 中 判断是那个结构
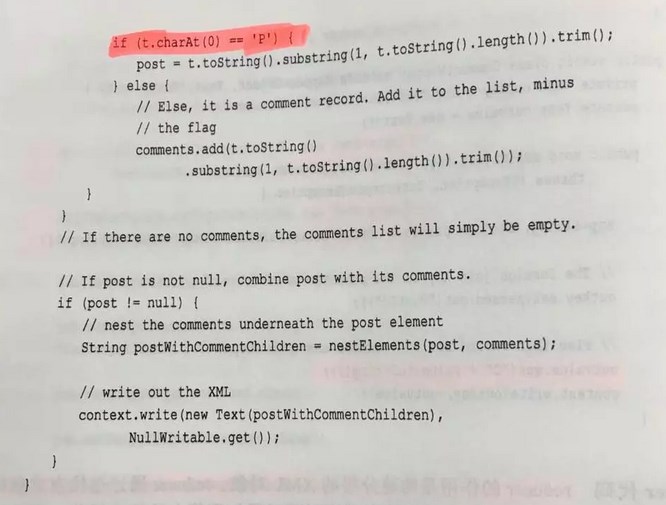
回到原题: 在例子中, 将帖子的问题 与 回复 管理起来,是非常必要的。 因为帖子中即包含回复,也包括问题, 并且问题和回复仅仅是通过 PostTypeId 进行区分。 因此可以通过问题中的 ID 以及回复中的 ParentId 将其组合在一起。 该模式使用自连接的方式将同一数据集中不同的记录关联起来。
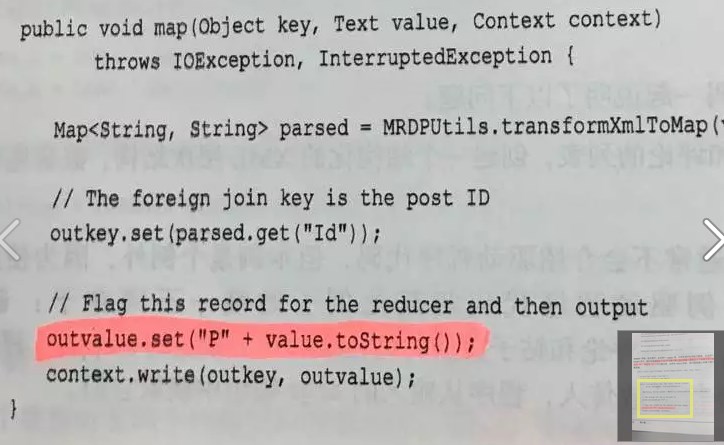
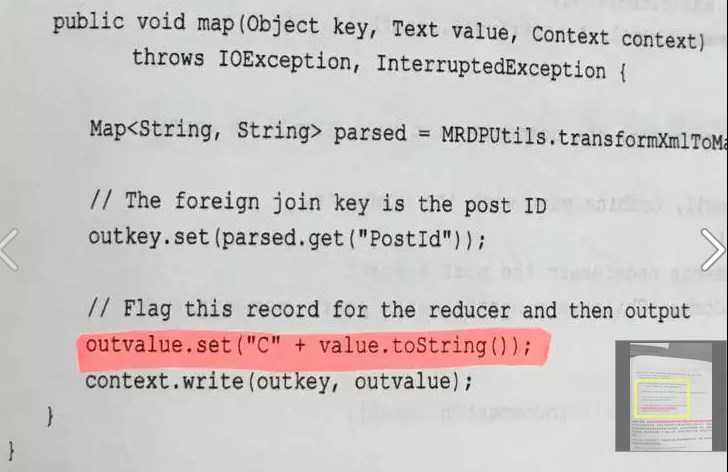
Mapper 代码: 判断该记录是问题还是回复。 对于问题, 取其 ID 作为键并将其标记为问题。 对于回复 则取其 ParentId 作为键 并将其标记为回复。
Reduce 代码: 判断输入值进行迭代处理获取问题和回复。 并将标识去除。(组成新 String ) 然后将回复嵌套至问题内。(突然觉得 XML 太适合层次结构了。因为可以无限加入 Element 向下延伸。)
误解: 此处只是解析, 并不是新浪微博那种可以无限叠楼。 无限叠楼仍然需要 存储入 HBase 中拉取数据。