1. 场景
从日志中获取漏发奖励的司机id
2. 日志 如下(需要获取一个时间段的 driverIdStr)
15:13:34.484 INFO [DubboServerHandler-10.0.30.43:20899-thread-5] order.service.TOrderInfoServiceImpl:1654 - 调用支付完成登记接口,URL=http://rocky/tOrderHandle/settleTaxiAccount,参数={"phone":"1865558888","cityIdStr":"44","customerIdStr":"4433","driverIdStr":"56398","orderTimeStr":"2018-01-19 14:56:36","activityFlagStr":"2","serviceType":35,"orderPriceStr":"14.00","orderId":"53743"}
3. 过滤出相关日志 继续处理
cat 19.log |grep 'settleTaxiAccount,参数='|awk -F '"driverIdStr":' '{print $2}'|awk -F '[,"]+' '{print $2}' > driverId_19.log #一天的 截取的司机id重定向到 文件中
cat driverId_19.log driverId_20.log |sort|uniq -u > driverId_uniq.log #将多日的司机id 排序 去重 再重定向到结果文件
mysql balabala... #导出已有司机id
comm -23 driverId_uniq.log driver_done.txt # 去除 已有的 -2 不显示在第二个文件中出现的内容; -3 不显示同时在两个文件中都出现的内容;-1:不显示在第一个文件中出现的内容 ;
4. sed 一把
cat 19.log 19_1.log 20.log 20_1.log|grep '"cityIdStr":"44"' |grep 'driverIdStr'|sed 's/.*"driverIdStr":"//g'|sed 's/".*$/ /g'|sort|uniq -u > driver_id2.txt
5. 20180524
今天遇到从字符串中摘出文案的小需求(双引号里的文字)

我想到了awk
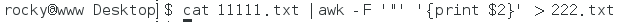
好用!
grep '过滤数单奖活动出错===>订单号' integral-error-xx.log integral-error-xx.log|awk -F ' ' '{print $1}'|awk -F '.' 'BEGIN {count=0;print "次数:"} {if($3>"13:00:00"){count+=1}} END {print count}'