主要两个方面
- Probabilistic modeling
概率建模,神经网络模型尝试去预测一个概率分布
- Cross-entropy作为误差函数使得我们可以对于观测到的数据
给予较高的概率值
同时可以解决saturation的问题
- 前面提到的线性隐层的降维作用(减少训练参数)

这是一个最初版的神经网络语言模型
- 选取什么要的loss function,为什么用cross-entropy,为什么不用squared loss呢?

首先 可以看到 cross-entropy更能从数值上体现0.01,0.0001两个预测的真实差别
另外一点是saturation

考虑sigmoid的激活单元输出y
考虑Cost和z之间的对应关系


由于cross-entropy的话 是convex的 所以没有局部的最优解只有全局最优解,因此更容易optimize
- 线性隐层单元

等价于embedding矩阵的lookup, R是embedding矩阵或者叫做lookup table
那么如何起到了降维效果,怎样降低了训练的参数?


embedding降维
- 当前神经网络语言模型的局限
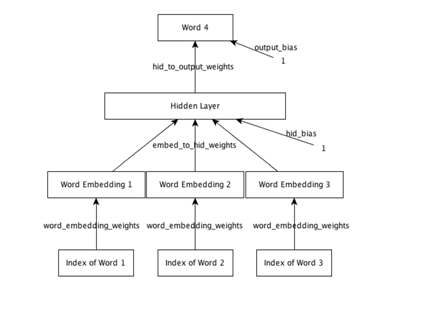
这个语言模型其实就是和word2vec的skip-gram model所对应的 continuous bag of words model(cbow)
Word2vec是从一个词预测周围的词 这个是从周围的词预测中心词 ,语言模型特定是从前几个词预测当前词
这意外着我们只能使用类似NGRAM,遵循markov assumption 而不能利用前几个词之外的更多信息

但是有时候长距离的语境也是有意义的比如

- RNN模型
RNN模型可以解决上述问题,可以学习到长距离的依赖关系


这是一个简单的RNN例子,将输入加和。
- RNN的训练
这和之前的普通神经网络训练的backprop算法是一样的 也是 backprop只是这里有两个新的问题
- Weight constraints 权重限制
- Exploding and vanishing gradients 梯度的爆炸和消失
5.1 关于权重的限制
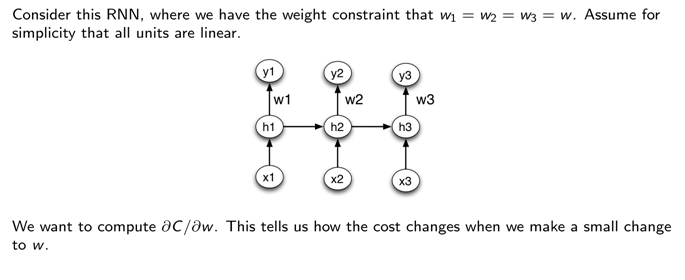
也就是说随着时间所有的单元的输出weight限制为相同的
一个hidden 到hidden的weight的例子


具体一个rnnlm实现的例子 参考http://www.cnblogs.com/rocketfan/p/4953290.html 关于rnnlm的图和介绍。
5.2 关于梯度的爆炸和消失

真正的问题不是backprop而是长距离的依赖非常复杂,梯度的爆炸和消失易于在backprop过程中传递叠加出现。

大于1的梯度不断传递 带来梯度爆炸,小于1的梯度不断传递带来梯度消失。
解决rnn的梯度爆炸和消失的方案:

- LSTM
- 将输入或者输出序列逆序,这样网络可以先看到近距离的依赖,然后再尝试学习困难的远距离的
- 梯度截断
Rnnlm,fater-rnnlm采用的第三种方法,强制截断梯度避免梯度爆炸
- LSTM
LSTM通过将单一的单元替换成复杂一些的记忆单元来解决这个问题

tensorflow关于LSTM的例子
https://github.com/jikexueyuanwiki/tensorflow-zh/blob/master/SOURCE/tutorials/recurrent/index.md
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
这里提到当距离较短时,rnn可以学习到历史的信息,但是当距离较长的情况下rnn是无能为力的。
短距离的例子,预测sky

长距离的例子,预测French

下面这个图非常清楚 普通的rnn,对应值做一个简单的非线性单元比如sigmoid,tanh
struct SigmoidActivation : public IActivation {
void Forward(Real* hidden, int size) {
for (int i = 0; i < size; i++) {
hidden[i] = exp(hidden[i]) / (1 + exp(hidden[i]));
}
}
来自 <http://www.cnblogs.com/rocketfan/p/4953290.html>


LSTM将单一的神经网络层变成了4个。

The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates.
来自 <http://colah.github.io/posts/2015-08-Understanding-LSTMs/>
LSTM可以通过gates的条件来给cell state去掉或者增加信息
第一步是丢弃信息
forget gate layer
It looks at ht−1 and xt, and outputs a number between 0 and 1 for each number in the cell state Ct−1. A 1 represents "completely keep this" while a 0 represents "completely get rid of this."
通过结合前一步输出和当前输入,输出一个0-1直接的数值(sigmoid),1表示全部保留,0表示全部丢弃。
举一个例子,比如语言模型,结合当前主题的性别信息来判断当前代词是she,he?
当遇到新的主题我们需要忘记掉之前的主题的性别信息

第二步是确定要保留的信息
对应语言模型的例子,遇到新的主题我们添加当前主题的性别信息

两次变化 sigmoid input layer gate + tanh layer
第三步:前两步结合到一起,丢弃掉之前的性别信息 + 加入当前的性别信息

第四步: 最后输出
Finally, we need to decide what we're going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer which decides what parts of the cell state we're going to output. Then, we put the cell state through tanh (to push the values to be between −1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to.
For the language model example, since it just saw a subject, it might want to output information relevant to a verb, in case that's what is coming next. For example, it might output whether the subject is singular or plural, so that we know what form a verb should be conjugated into if that's what follows next.
来自 <http://colah.github.io/posts/2015-08-Understanding-LSTMs/>
