考虑典型的文本分类,一个经典的方法就是
- 分词,扫描所有特征,建立特征词典
- 重新扫描所有特征,利用特征词典将特征映射到特征空间编号 得到特征向量
- 学习参数 w
- 存储学习参数 w , 存储特征映射词典
- 预测截断装载学习参数w,装载特征映射词典
- 扫描数据,将所有特征利用特征映射词典映射到特征空间编号 得到特征向量
- 利用用学习参数w 对得到的特征向量 进行 点积 做出预测
Feature hashing怎么做?
不使用特征词典了,不用考虑额外的存储词典的空间,直接对特征进行hash编号。
有冲突? 后面会说明对效果影响不大!
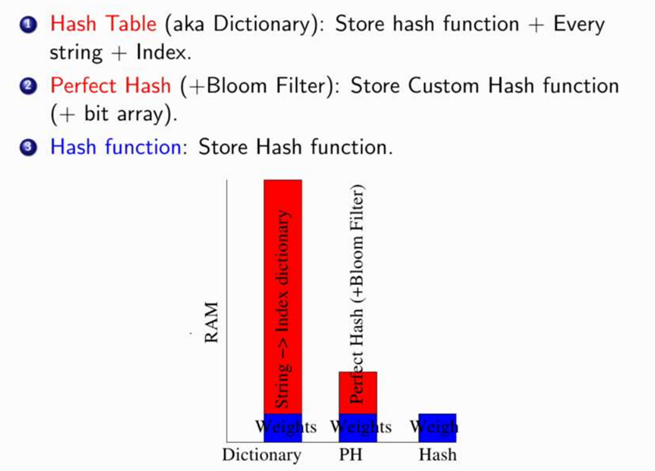
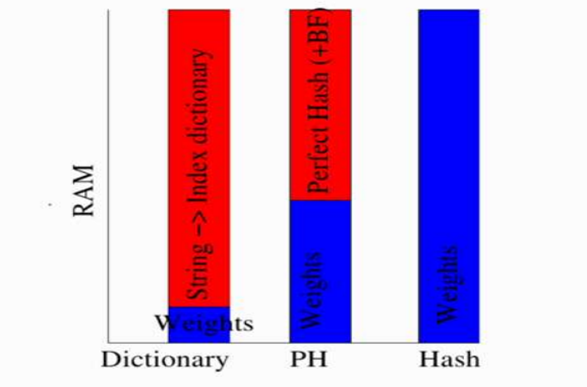
同样的内存占用下 我们可以存储更多的weights!