一.索引的本质:
索引是为MySQL提高获取数据效率的数据结构,为了快速查询数据。索引是满足某种特定查找算法的数据结构,而这些数据结构会以某种方式指向数据,从而实现高效查找数据。
二.索引的原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等,下面内容看不懂的同学也没关系,能明白这个目录的道理就行了。 那么你想,书的目录占不占页数,这个页是不是也要存到硬盘里面,也占用硬盘空间。你再想,你在没有数据的情况下先建索引或者说目录快,还是已经存在好多的数据了,然后再去建索引,哪个快,肯定是没有数据的时候快,因为如果已经有了很多数据了,你再去根据这些数据建索引,是不是要将数据全部遍历一遍,然后根据数据建立索引。你再想,索引建立好之后再添加数据快,还是没有索引的时候添加数据快,索引是用来干什么的,是用来加速查询的,那对你写入数据会有什么影响,肯定是慢一些了,因为你但凡加入一些新的数据,都需要把索引或者说书的目录重新做一个,所以索引虽然会加快查询,但是会降低写入的效率。
索引的影响
1、在表中有大量数据的前提下,创建索引速度会很慢
2、在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
三 .索引的数据结构
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构,例如MySQL就普遍使用B+Tree实现其索引结构。
实现过程:
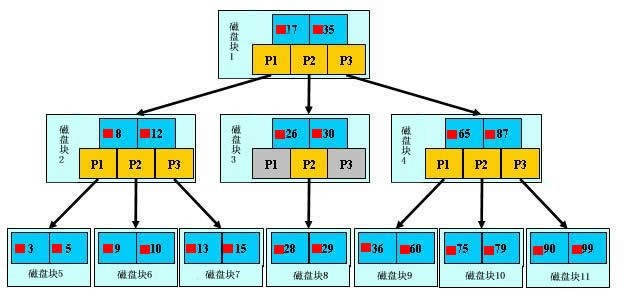
如上图,是一颗b+树,最上层是树根,中间的是树枝,最下面是叶子节点,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块或者叫做一个block块,这是操作系统一次IO往内存中读的内容,一个块对应四个扇区,可以看到每个磁盘块包含几个数据项(深蓝色所示,一个磁盘块里面包含多少数据,一个深蓝色的块表示一个数据,其实不是数据,后面有解释)和指针(黄色所示,看最上面一个,p1表示比上面深蓝色的那个17小的数据的位置在哪,看它指针指向的左边那个块,里面的数据都比17小,p2指向的是比17大比35小的磁盘块),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
b+树的查找过程:
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。除了叶子节点,其他的树根啊树枝啊保存的就是数据的索引,他们是为你建立这种数据之间的关系而存在的。
四.聚集索引与非聚集索引(辅助索引)
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index)
聚集索引
一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。
聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行 的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此 类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。
当索引值唯一时,使用聚集索引查找特定的行也很有效率。例如,使用唯一雇员 ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。
聚集索引的好处:
1.它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页并取出
10条记录
2.范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可
非聚集索引
一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。如下图:

InnoDb索引实现(叶节点包含了所有数据,使用聚集索引)
使用B+树作为索引结构,数据文件本身就是索引文件。数据文件按照B+树的结构进行组织,叶节点的data域存储完整的数据记录,索引的key即为表的主键。


#InnoDB存储引擎表示索引组织表,即表中数据按照主键顺序存放。而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个数据页都通过一个双向链表来进行链接。
#如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。
#如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。
#由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。在多少情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。此外由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值得查询。
MyISAM索引实现(叶节点的data域存放的是数据记录的地址,使用非聚集索引)
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。同样也是使用B+树作为索引结构,叶子节点data域存储的是数据记录的地址。数据文件和索引文件是分别存储在xxx.MYD和xxx.MYI(xxx表示
数据表名),索引文件xxx.MYI保存数据记录的地址.
MyISAM中检索索引算法为:首先按照B+树搜索算法搜索,如果找到指定的key,取出其data域的值,再以data域值为地址查找对应的数据记录。因此MyISAM的索引方式也称为非聚集索引。
五.创建索引
创建索引
1.创建表的时候创建索引
1.创建普通索引:
create table tb1 ( bookid int not null, info varchar(255) null, index(info) # 在这里创建普通索引 ):
2.创建唯一索引:(与创建唯一约束其实一样)
create table t1 ( id not null, name char(30) not null, unique index unidx(id) # unidx是索引名 );
3.创建单列索引:
create table t2 ( id int not null, name char(50) null, index singleidx(name(20)) );
4.创建组合索引:(在多个字段上创建一个索引)
create table t3 # 表中的id,name和age字段上建立联合索引 ( id int not null, name char(30) not null, age int not null, info varchar(255), index multiIdx(id,name,age(100)) # 索引名是multiIdx
5.创建全文索引(fulltext)
fulltext(全文索引)可以用于全文搜索,只有MyISAM存储引擎支持fullltext索引,并且只为char,varchar和text列创建索引.索引总是对整个列进行,不支持局部(前缀)索引
create table t4 ( id int not null, name char(30) not null, age int not null, info varchar(255), fulltext index fulltxtidx(info) ) engine= myisam
6.创建空间索引
空间索引必须在MyISAM类型的表中创建,且空间类型的字段必须为空
create table t5 (g geometry not null, spatial index spatidx(g)) engine = MyISAM;
2.在已经存在的表上创建索引
1.使用alter,基本语法
alter table table_name add [unique|fulltext|spatial] [index|key] [index_name] (col_name[length],...) [ASC | DESC]
示例:
使用alter table 在bookname字段上添加索引 alter table book add index bknameidx(bookname(30)) 在book表的bookid字段上建立名称为uniqueididx的唯一索引 alter table book add unique index uniqididx(bookid); 在book表的comment字段上建立单列索引 alter table book add index bkcmtidx( comment(50) ) 在book表的authors和info字段上建立组合索引 alter table book add index bkindex ( authors(30),info(50) )
2.使用create index
基本语法:
create [unique] index 索引名 on 表名
创建unique索引 create unique index uniqidinx on book ( bookid )
六.删除索引
1.使用alter table 删除索引
alter table 表名 drop index index_name;
删除book表中名为uniqididx的唯一索引 alter table book drop index uniqididx;
2.使用 drop index 删除索引
drop index 索引名 on 表名
七.禁用索引
插入记录时,影响插入速度的主要时索引,唯一性校验,一次插入记录条数等
对于MyISAM引擎的表 ,可以禁用索引来优化插入记录的速度.
1.在插入记录之前禁用索引
alter table 表名 disable keys;
2.插入完毕后重新开启索引
alter table 表名 enable keys;