lucene详细存储结构:
索引 (Index) :
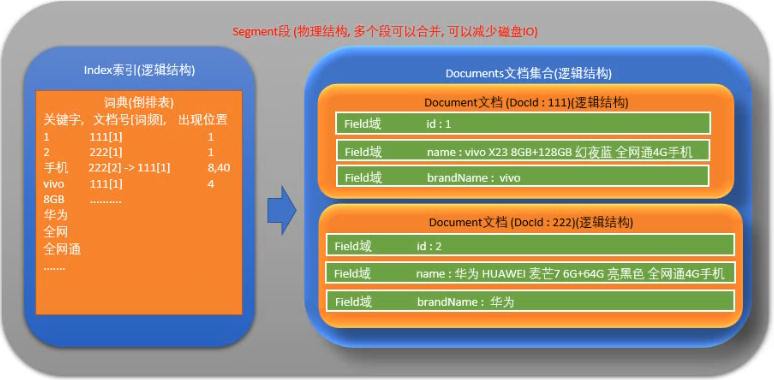
一个目录一个索引,在 Lucene 中一个索引是放在一个文件夹中的。
段(Segment) :
一个索引 (逻辑索引)由多个段组成, 多个段可以合并, 以减少读取内容时候的磁盘IO.
Lucene 中的数据写入会先写在内存的一个Buffer,当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是批量追加,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并。
文档(Document) :
文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
域(Field) :
一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,描述等,都可以保存在不同的域里。
不同域的索引方式可以不同。
词(Term):
词是索引的最小单位,是经过词法分析和语言处理后的字符串。
词典的构建:
为何Lucene大数据量搜索快, 要分两部分来看:
一点是因为底层的倒排索引存储结构
另一点就是查询关键字的时候速度快 , 因为词典的索引结构
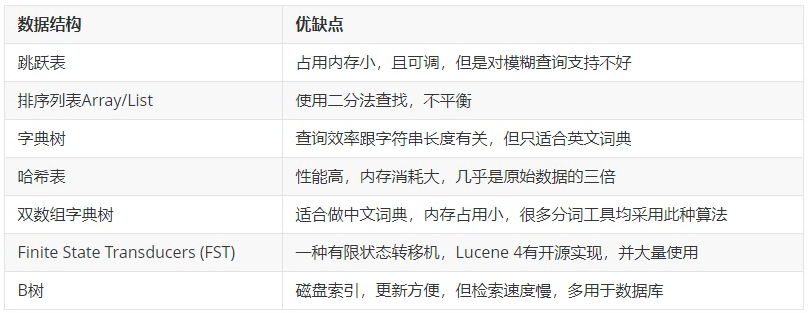
词典数据结构对比:
倒排索引中的词典位于内存,其结构尤为重要,有很多种词典结构,各有各的优缺点,最简单如排序数组,通过二分查找来检索数据,更快的有哈希表,磁盘查找有B树、B+树,但一个能支持TB级数据的倒排索引结构需要在时间和空间上有个平衡,下图列了一些常见词典的优缺点:
Lucene3.0之前使用的也是跳跃表结构,后换成了FST,但跳跃表在Lucene其他地方还有应用如倒排表合并和文档号索引。
跳跃表原理:Lucene3.0版本之前使用的跳跃表结构,后换成了FST结构
优点 :结构简单、跳跃间隔、级数可控
缺点 :模糊查询支持不好.
Lucene 优化:
解决大量磁盘IO
config.setMaxBufferedDocs(100000); 控制写入一个新的segment前内存中保存的document的数目,设置较大的数目可以加快建索引速度。
数值越大索引速度越快, 但是会消耗更多的内存
indexWriter.forceMerge( 文档数量); 设置N个文档合并为一个段
数值越大索引速度越快, 搜索速度越慢; 值越小索引速度越慢, 搜索速度越快
更高的值意味着索引期间更低的段合并开销,但同时也意味着更慢的搜索速度,因为此时的索引通常会包含更多的段。
如果该值设置的过高,能获得更高的索引性能。但若在最后进行索引优化,那么较低的值会带来更快的搜索速度,因为在索引操作期间程序会利用并发机制完成段合并操作。故建议对程序分别进行高低多种值的测试,利用计算机的实际性能来告诉你最优值。
选择合适的分词器:
不同的分词器分词效果不同, 所用时间也不同
虽然StandardAnalyzer切分词速度快过IKAnalyzer, 但是由于StandardAnalyzer对中文支持不好, 所以为了追求好的分词效果, 为了追求查询时的准确率, 也只能用IKAnalyzer分词器, IKAnalyzer支持停用词典和扩展词典, 可以通过调整两个词典中的内容, 来提升查询匹配的精度
选择合适的位置存放索引库:

Directory directory = MMapDirectory.open(Paths.get("D:\dir"));
搜索api的选择:
1. 尽量使用TermQuery代替QueryParser
Query query = new TermQuery(new Term(fieldName,queryString));
new Term("title","Java");即表示在title域里查询包含Java的
QueryParser会经过分词器,会使用分词器把用户输入的关键字进行分词,而TermQuery则不会,直接根据用户提供的关键字去分词后的Term里查找的
2. 尽量避免大范围的日期查询
Lucene 相关度排序:
什么是相关度排序?
Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边。
如何打分?
Lucene是在用户进行检索时实时根据搜索的关键字计算出来的,分两步:
1. 计算出词(Term)的权重
2. 根据词的权重值,计算文档相关度得分。
明确索引的最小单位是一个Term(索引词典中的一个词),搜索也是要从Term中搜索,再根据Term找到文档,Term对文档的重要性称为权重,影响Term权重有两个因素:
Term Frequency (tf) : 指此Term在此文档中出现了多少次。tf 越大说明越重要。词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“Lucene”这个词,在文档中出现的次数很多,说明该文档主要就是讲Lucene技术的。
Document Frequency (df) : 指有多少文档包含次Term。df 越大说明越不重要。 比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
怎样影响相关度排序?
boost是一个加权值(默认加权值为1.0f),它可以影响权重的计算。
在索引时对某个文档中的 field 设置加权值高,在搜索时匹配到这个文档就可能排在前边。
在搜索时对某个域进行加权,在进行组合域查询时,匹配到加权值高的域最后计算的相关度得分就高。
设置boost是给域(field)或者 Document 设置的。
// 创建分词器 Analyzer analyzer = new IKAnalyzer(); // 查询的域名 String[] fields = {"name","brandName","categoryName"}; // 设置权重 Map<String, Float> boots = new HashMap<>(); boots.put("categoryName", 10000000f); // 根据多个域进行搜索 MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, analyzer, boots); // 创建搜索对象 Query query = queryParser.parse("手机");
Lucene 使用注意事项:
关键词区分大小写:
OR AND TO等关键词是区分大小写的,lucene只认大写的,小写的当做普通单词。
读写互斥性:
同一时刻只能有一个对索引的写操作,在写的同时可以进行搜索
文件锁:
在写索引的过程中强行退出将在tmp目录留下一个lock文件,使以后的写操作无法进行,可以将其手工删除
时间格式
lucene只支持一种时间格式yyMMddHHmmss,所以你传一个yy-MM-dd HH:mm:ss的时间给lucene它是不会当作时间来处理的
设置 boost:
有些时候在搜索时某个字段的权重需要大一些,例如你可能认为标题中出现关键词的文章比正文中出现关键词的文章更有价值,你可以把标题的boost设置的更大,那么搜索结果会优先显示标题中出现关键词的文章.