前言:不端学习就是程序员的宿命。
一、概述
参考之前鄙人博客:SpringCloud全家桶学习之断路器---Hystrix(五)
Hystrix的Github地址:https://github.com/Netflix/hystrix/wiki,现已停更进维
(1)服务降级:服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback。哪些情况会触发降级?例:程序运行异常、超时、服务熔断触发服务降级、线程池/信号量打满也会导致服务降级。服务的降级处理是在客户端实现完成,与服务端没有关系。在服务熔断机制下,每个方法都要有一个对应的注解HystrixCommand和fallback方法,这样显然是不合适的,而且对本身业务也有侵入性。所以服务降级可以实现上述逻辑的解耦和分离。而这里又是面向接口编程,所以自然想到了将异常等处理逻辑与接口进行绑定,即可实现对业务本身无侵入,实现解耦。
(2)服务熔断:类似保险丝达到最大服务访问后,直接拒绝访问,然后调用服务降级的方法并返回友好提示。服务熔断:熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回“错误”的响应信息。当检测到该节点的微服务调用响应正常后恢复调用链路。在Spring Cloud框架里熔断机制通过Hystix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定的阈值,缺省是5秒内20次调用失败就会启动熔断机制。熔断机制的注解是@HystrixCommand
熔断类型:
①熔断打开:请求不再调用当前服务,内部设置一般为MTTR(平均故障处理时间),当打开长达导所设时钟则进入半熔断状态
②熔断关闭:熔断关闭后不会对服务进行熔断
③熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断
大神论文:https://martinfowler.com/bliki/CircuitBreaker.html
熔断官网流程图地址:https://github.com/Netflix/Hystrix/wiki/How-it-Works
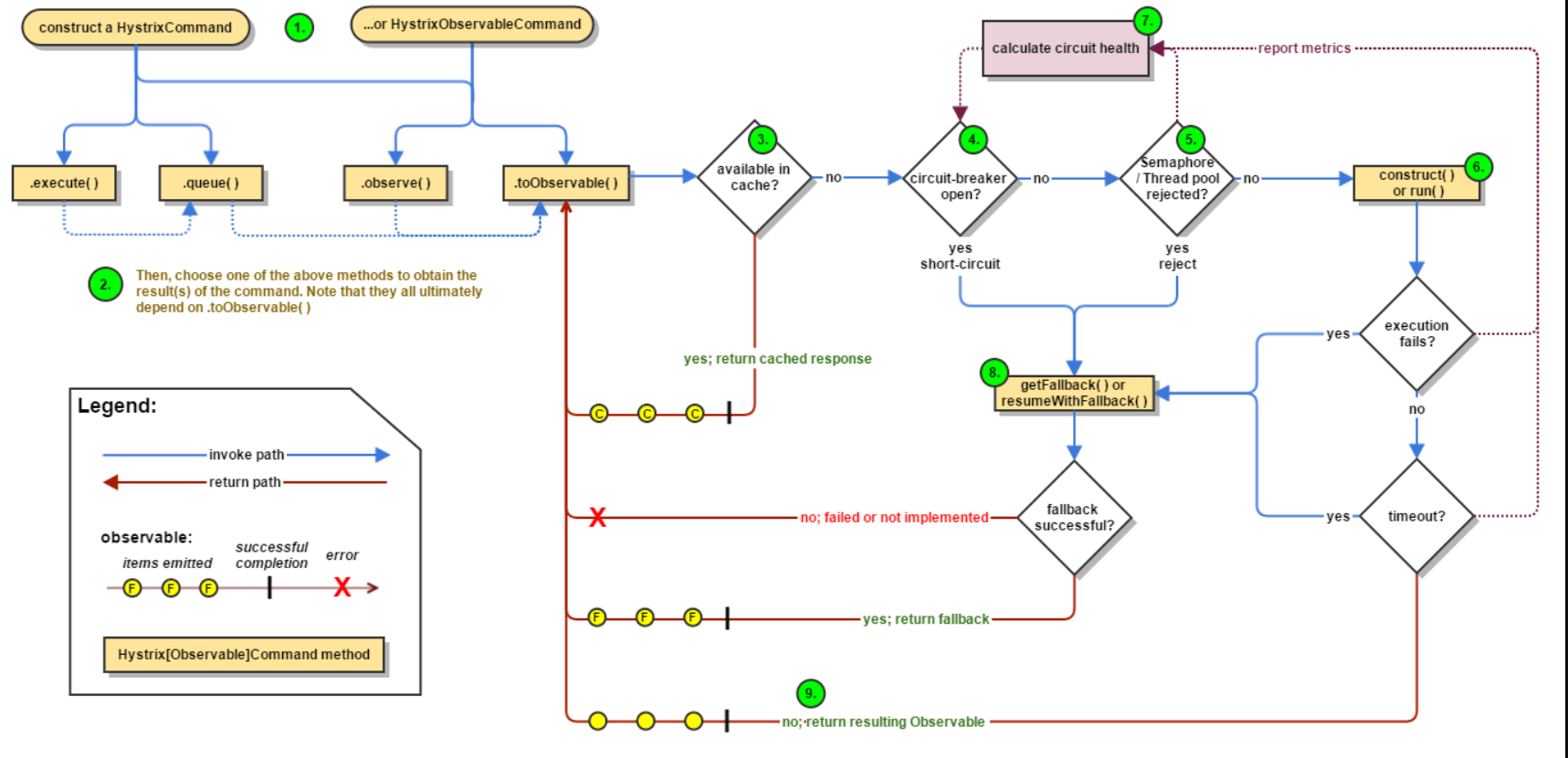
流程图分析:

(3)服务限流:秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行。
(4)服务监控DashBoard
二、服务降级
1、provider端服务降级:@HystrixCommand注解

2、consumer端服务降级:@HystrixCommand+@EnableHystrix+配置文件
2.1 application.yml新增如下配置:
feign: hystrix: # 在feign中开启Hystrix enabled: true
2.2主启动类添加@EnableHystrix
2.3使用@HystrixCommand注解
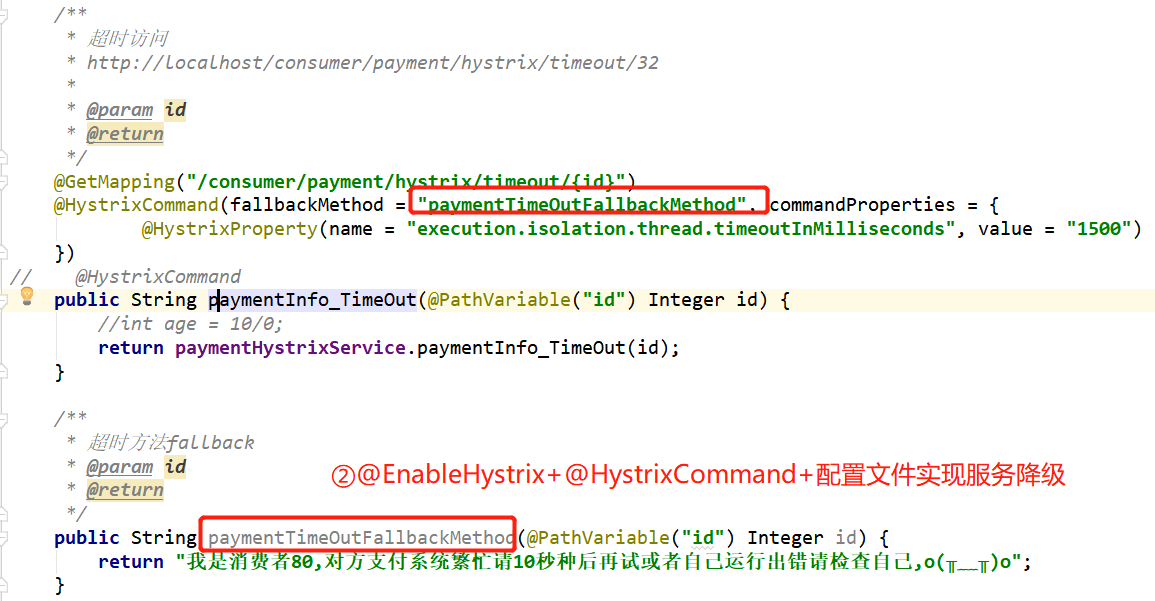
3、全局服务降级

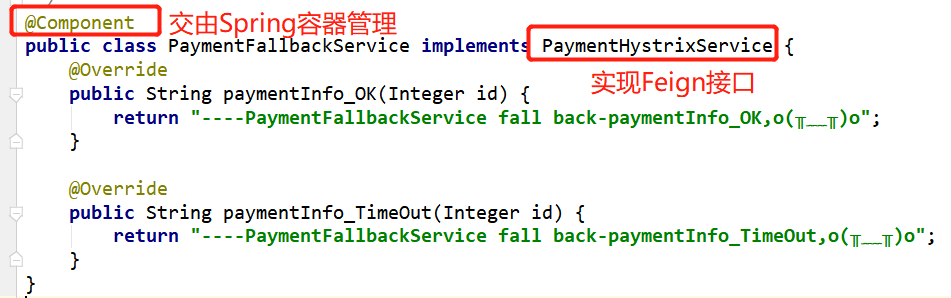
4、通配服务降级FeignFallback
使用方式:实现Feign接口并交由Spring容器管理,@FeignClient注解添加Fallback属性

三、服务熔断
1、代码实现
HystrixCommandProperties查看配置

2、测试及分析

分析:
(1)断路器在什么情况下开始起作用?
涉及到断路器的三个重要参数:快照时间窗、请求总数阈值、错误百分比阈值
1、快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
2、请求总数阈值:在快照时间窗内,必须满足请求总数阈值才有资格熔断。默认为20,意味着在10秒内,如果该Hystrix命令的调动次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
3、错误百分比阈值:当请求总数在快照时间窗内超过了阈值,比如发生了30次调用,如果在这30次调用中,有15次调用发生了超时异常,也就是超过了50%的错误百分比,在默认设定50%阈值的情况下,这时候断路器就会打开。
(2)断路器开启或关闭的条件?
1、当满足一定阈值时(默认10秒内超过20个请求次数)
2、当失败率达到一定时(默认10秒内超过50%的请求失败)
3、到达以上阈值,断路器将开启
4、当开启时,所有请求将不会转发
5、一段时间后(默认是5秒),这个时候断路器是半开状态,会让其中一个进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4~5
(3)断路器开启后:
1、再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback,通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
2、原来的主逻辑要如何恢复?
①Hystrix实现了自我恢复的功能
②当断路器打开时,Hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的主逻辑
③当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将闭合,主逻辑恢复;否则继续打开状态,休眠时间窗重新计时。
四、Hystrix图形化DashBoard监控
参考鄙人博客:SpringCloud全家桶学习之断路器---Hystrix(五),Cloud升级后有坑
1、被监控的服务添加如下代码
否则会出现:Unable to connect to Command Metric Stream


/** * 此配置是为了服务监控而配置,与服务容错本身无观,springCloud 升级之后的坑 * ServletRegistrationBean因为springboot的默认路径不是/hystrix.stream * 只要在自己的项目中配置上下面的servlet即可 * * @return */ @Bean public ServletRegistrationBean getServlet() { HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet(); ServletRegistrationBean<HystrixMetricsStreamServlet> registrationBean = new ServletRegistrationBean<>(streamServlet); registrationBean.setLoadOnStartup(1); registrationBean.addUrlMappings("/hystrix.stream"); registrationBean.setName("HystrixMetricsStreamServlet"); return registrationBean; }
2、DashBoard Web界面

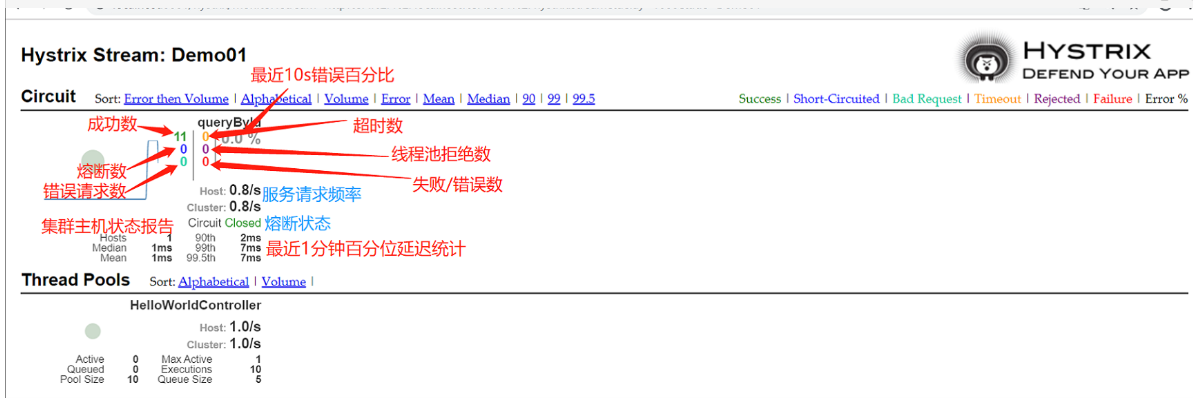
简记:7色,1圈,1线
7个颜色分别对应有英文提示说明;
1圈越大,说明该服务的访问频率越高,流量压力也比较大;
1线就很明显了,实时的调用频率。
说明:
①实心圆:两层含义,它通过颜色的变化代表了实例的健康程度,它的健康程度从绿色<黄色<橙色<红色依次递减。此外,它的大小也会根据实例的请求流量发生变化,流量越大该实心圆就越大。所以通过实心圆的展示,就可以在大量的实例中快速的发现故障实例和高压力实例。
②曲线:用来记录2分钟内的相对变化,可以通过它来观察到流量的上升和下降趋势