SparkSQL将RDD封装成一个DataFrame对象,这个对象类似于关系型数据库中的表。
一、SparkSQL入门
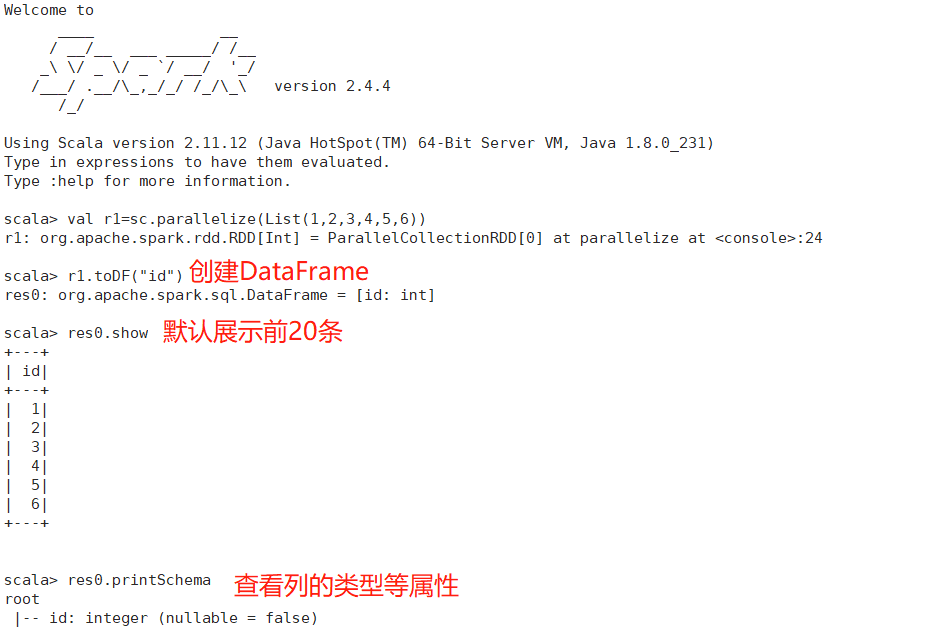
1、创建DataFrame
相当于数据库中的一张表,它是一个只读的表,不能在运算过程中再往里加元素。RDD.toDF("列名")
2、创建多列DataFrame对象
1)2列DataFrame

2)3列DataFrame

3、外部文件构造DataFrame
1)txt文件
txt文件不能直接转化成DataFrame,先利用RDD转换成tuple,然后toDF()转换为DataFrame

2)json文件

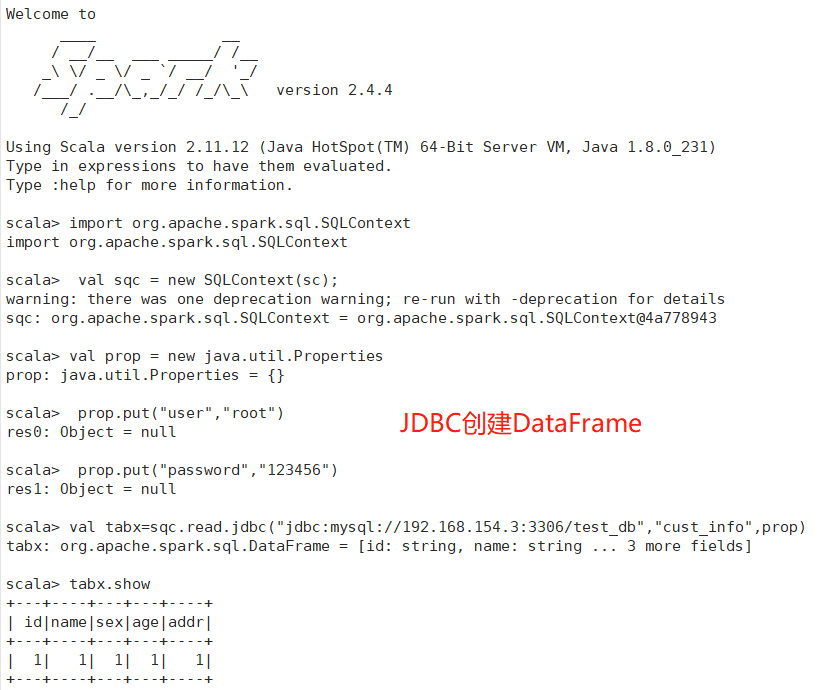
3)jdbc读取
实现步骤:
①将mysql的驱动jar包上传至Spark的jars目录下
②重启Spark服务
③进入spark客户端
④执行代码,比如在mysql的数据库下有一个test_db库,在test_db库下有一张表为cust_info
二、SparkSQL基础语法(方法)

三、SparkSQL基础语法(sql语句)

四、SparkSQL API
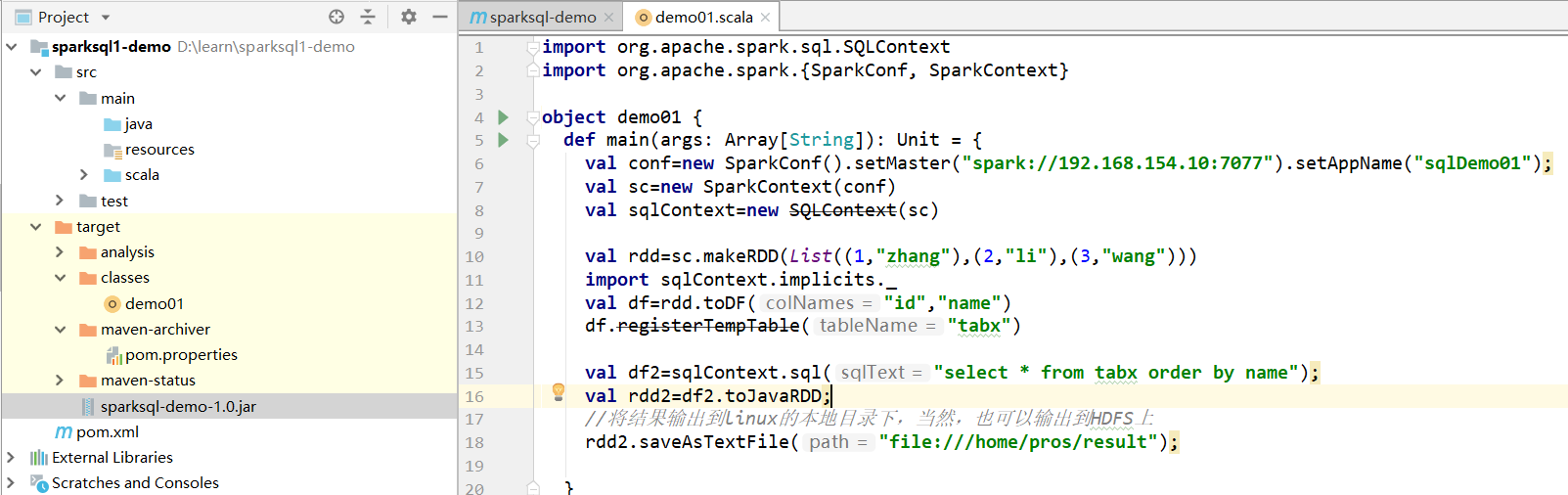
1、编写Scala代码
2、打jar包并上传至服务器
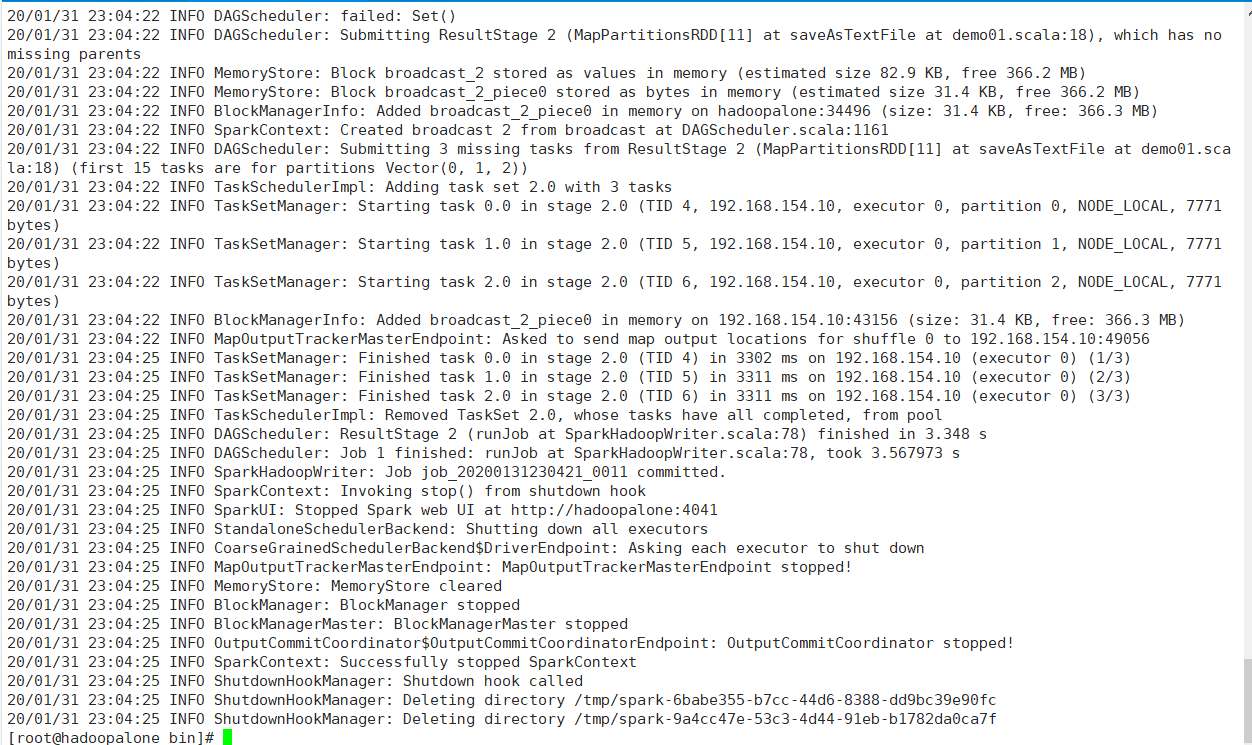
3、在spark的bin目录下执行
sh spark-submit --class demo01 ./sparksql-demo-1.0.jar ,执行后出现如下结果:
4、查看结果文件
